SwissLog: Robust and Unified Deep Learning Based Log Anomaly Detection for Diverse Faults 阅读与思考 |
您所在的位置:网站首页 › bi为前缀的单词有哪些 › SwissLog: Robust and Unified Deep Learning Based Log Anomaly Detection for Diverse Faults 阅读与思考 |
SwissLog: Robust and Unified Deep Learning Based Log Anomaly Detection for Diverse Faults 阅读与思考
|
前言:
本文主要是对《SwissLog: Robust and Unified Deep Learning Based Log Anomaly Detection for Diverse Faults 》论文的解析以及我个人的思考。 论文简介:提出SwissLog的深度学习日志异常检测框架,用于检测不同类型的故障日志。SwissLog框架通过将日志解析为结构化的事件序列,并将事 件序列作为输入来训练多个模型,从而实现对各种故障类型的检测 一、日志异常
大规模系统不可避免地会出现故障,导致日志模式发生变化。我们在实践中针对两种类型的日志变化,如图1(b)和图1©所示。我们省略了一些不重要的日志语句,只显示关键信息(即时间、冗长级别、简化的日志语句)。 1.1.1序列顺序变化:图1(a)中正常序列与异常序列对比,如图1(b)所示,异常日志语句以黄色突出显示。 在这种情况下,系统接收到一个多余的addStoredBlock请求,导致序列顺序发生变化。因此,顺序日志异常一般可以从其异常的顺序顺序来观察。以往的针对顺序日志异常的工作,通过检测异常日志的顺序来识别。 1.1.2日志时间间隔变化:另一种故障是性能问题,如图1©所示。 与异常的序列顺序相反,有性能问题的块通常保持与正常块相同的序列顺序。但是,性能问题会根据特定任务的故障组件降低其执行时间。例如,第3行中的接收块有3000毫秒的延迟,这是由网络拥塞引起的。这里的性能问题表现在时间间隔的变化上。这种性能问题就像埋在地下的地雷,可能会引发灾难性的中断。因此,检测性能问题的主题最近得到了很多关注。但是现有的方法采用静态分析来发现性能缺陷,或者采用侵入式方法来检测它们。它们要么很难在运行时检测到性能问题,要么会降低系统性能。如果我们通过挖掘日志数据中的时间间隔变化来检测性能问题,那么上述问题就相应解决了。 1.2总结也就是说,主要两种异常,一种是序列顺序变化,另一种是日志时间间隔变化。 仅用语义信息来检测多种类型的错误是不够的。它是无法检测到第二种时间间隔变化的异常。因此,需要时间信息作为异常检测方法的补充,后面的Sentence Embedding部分会具体讲到。 二、SwissLog的整体流程架构SwissLog包括离线处理阶段和在线处理阶段两个阶段。每个阶段包括日志解析、句子嵌入、基于attn的Bi-LSTM阶段,特别是在线阶段包含异常检测阶段。 首先,SwissLog采用了一种新颖的日志解析方法,通过对历史日志数据进行标记化、字典化和聚类来提取多个模板。这些模板保存为自然的句子,而不是事件id。我们将这些日志语句与相同的标识符链接起来,或者简单地使用一个滑动窗口来构造名为“会话”的日志序列。然后将日志序列转换为语义信息和时间信息。SwissLog使用BERT编码器将语义信息F编码到嵌入的Econtext中,并将时态信息ΔT投影到嵌入的Etime中。 将语义嵌入Esemantic和时间嵌入Etime作为输入输入到基于attn的Bi-LSTM中,学习正常、异常和性能异常日志序列的特征。在运行时,在线阶段也执行与离线阶段相同的工作流。最后,预训练的SwissLog模型预测日志序列是否异常。一旦检测到异常,就会产生告警
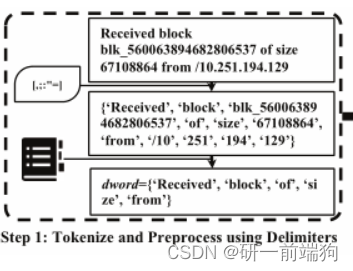
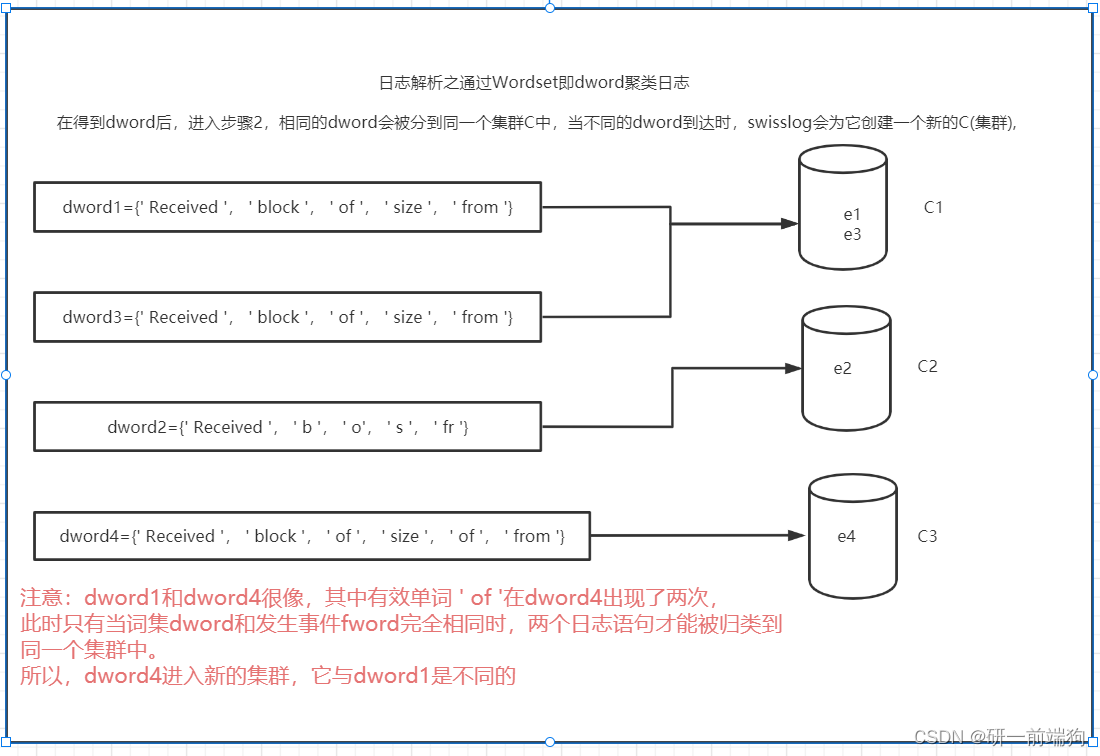
根据论文中的例子: 当原始日志消息“Received block blk_560063894682806537 of size 67108864 from /10.251.194.129”到达时,它将被分离为11个tokens。在字典中搜索后,’ Received ', ’ block ', ’ of ', ’ size ', ’ from '被识别为有效单词。最后,我们获得包含有效单词的wordset词集dword。 1.2标记化和预处理的具体原理:在每个日志语句e中,定义一个日志语句片作为token。。在基于字典的方法中,如何将完整的日志语句标记为适当的tokens是一个关键问题,因为解析结果在很大程度上依赖于它。日志系统使用特殊的分隔符来分隔字符串。为了更好的标记化,论文中使用即{,。; : "},用于标记日志语句。 给定一个字典D = {w1, w2,…, wn},这样每个单词wi都可以被标识为有效单词。在标记化之后,我们首先检查日志语句e的tokens是否在字典D中,然后我们得到wordset词集:一个由有效单词组成的多重集dword = {d1, d2,…, dm},其中∀di∈D。 1.3标记化和预处理的总结:
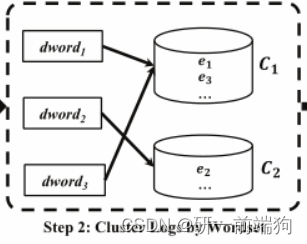
根据论文中的例子: 假设dword1、dword2、dword3分别是日志语句e1、e2、e3的wordset。由于日志语句e1和e2有不同的wordset, SwissLog分别为它们创建新的集群C1和C2。观察到wordset dword3与dword1相同,日志语句e3因此被归类到集群C1中。 2.2 dword聚类日志的具体原理:这一步的目标是用相同的Wordset即dword聚类相似的日志语句。当一个新的 wordset dword到达时,SwissLog为它查找匹配的组。如果匹配到一个组,SwissLog将wordset dword放入其中。否则,SwissLog将为wordset dword创建一个新的集群。 2.3 dword聚类日志的总结:
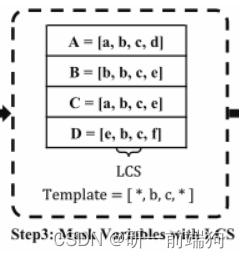
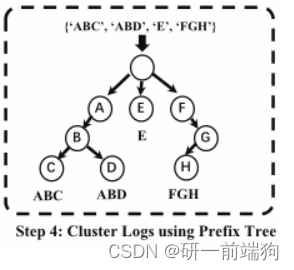
假设集群C1中有四个日志语句A、B、C、D。 A和C的两个公共子序列是{a, b, c}。A, B, C, D的令牌级LCS为{b, c}。 这个有点像数学里面的交集:A∩B∩C∩D 3.2 具体原理:掩码层的目的是区分聚类中的常量部分和变量部分。同一集群中日志语句的共同序列可视为常量部分,变化部分可视为变量部分。接下来,我们引入令牌级最长公共序列(LCS)来帮助我们用*掩盖集群中的所有变量部分。 LCS就是在一个序列集中找出最长的序列,即公共子序列。 与传统的LCS问题相比,SwissLog侧重于token-level的LCS。通过wordset聚类后,日志语句e1和e3在同一集群C1中。步骤3的输入涉及到所有的tokens,不仅包括vocabulary中的单词,还包括vocabulary词汇表外的单词。 词汇表中的 集群C1的令牌级LCS为{’ Receiving ', ’ block ', ’ src ', ’ dest '},因此该集群的屏蔽结果为“Receiving block * src: * dest: *”。 4 Cluster Logs using Prefix Tree:
给定一组字符串strs = {ABC, ABD, E, F GH},它们由前缀树索引。String ABD从根开始遍历整个树,以检查是否存在公共前缀。然后找到ABC,因此它们的叶节点指向相同的父节点B,而字符串E和FGH由于没有共同的前缀而分支出去。键列在节点中,最终的字符串值在节点下面。 4.2 具体原理:在屏蔽变量之后,有一个重要的问题不容忽视。给出一个例子,图4中的模板来自OpenSSH日志数据。我们观察到日志语句e4和e5之间的区别是一个用户名,在e4中分别是admin,在e5中分别是root。在这种情况下,变量部分涉及有效单词,因此两个模板在按wordset聚类日志后被视为不同的模板。我们在日志分析中使用前缀树是为了避免上述情况。 **在聚类之前,我们首先按照字母顺序对所有词集wordset进行排序,这在很大程度上有助于减少前缀树的构建时间。**同样,我们将*放在所有alpha顺序之前的第一排。该方法不需要搜索前缀,而是需要找出公共的前子序列。可以将词集dword中的每个token(即图4中的“disconnect”)视为一个元素,然后利用前缀树寻找公共的前子序列。这样,图4中所示的例子最终可以聚集到一个模板中。 (2)句子嵌入前面提到,仅用语义信息来检测多类型的错误是不够的,还需要引入时间信息作为异常检测方法的补充。在日志解析之后,我们通过将日志与相同的标识符或滑动窗口相关联来构造会话。我们将序列转换为语义信息T和时态信息ΔT。然后我们用下面的方法对这两种信息进行编码。 (3)基于attn的Bi-LSTM阶段经过句子嵌入,每条日志信息转化为语义向量 Esemantic 和时间嵌入向量 Etime 。我们得到连接 V = concat(Esemantic, Etime),因此每个日志序列都表示为一个向量列表(如 [V1, V2,…], vt] )。SwissLog 以这些向量为输入,采用基于 attn 的 Bi-LSTM 神经网络对不同的异常进行检测,如图 7 所示。 异常检测阶段在离线阶段,我们获得了一个预先训练好的基于 attn 的 Bi-LSTM 模型,用于使用历史日志进行异常检测。当一组新的日志语句到达时,它首先经过日志解析和句子嵌入。然后将得到的向量作为输入输入到预训练的模型中。最后,基于 attn 的 Bi-LSTM 可以检测是否发生异常。请注意,SwissLog 是基于由一个公共标识符(如block ID)关联的日志语句会话做出决策的。因此,在会话关闭之前,可以稳定地报告异常。换句话说,SwissLog 像 LogRobust 和 LogAnomaly 一样以接近实时的方式工作。 四、 实验部分本实验部分主要是根据以下几个问题展开的: RQ1:建议的日志解析器的有效性和鲁棒性如何?• RQ2: BERT编码器对异常检测的有效性如何?使用BERT编码器,其他日志解析器的性能是否与建议的日志解析器一样好? RQ3:随着事件的变化,SwissLog对这些日志数据的鲁棒性如何? RQ4: SwissLog能检测到性能问题吗?SwissLog对记录时间偏差有多敏感? 4.1数据集实验中所用的数据集 Real-world Datasets.Logpai采用16个真实世界的日志数据集,涵盖分布式系统、超级计算机、操作系统、移动系统、服务器应用,以及HDFS、Hadoop、Spark、Zookeeper、BGL、HPC、Thunderbird、Windows、Linux、Android、HealthApp、Apache、proxy、OpenSSH、OpenStack、Mac等独立软件,由LogHub提供。 4.2在调试代码后,跑出数据:
|

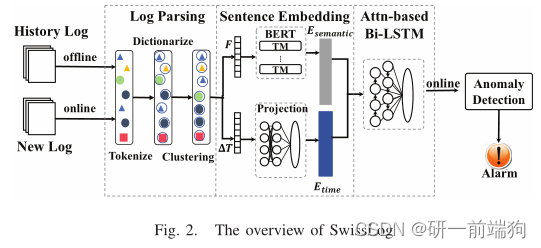 接下来我们将详细介绍SwissLog的四个阶段,包括日志解析,句子嵌入,基于attn的Bi-LSTM,异常检测。
接下来我们将详细介绍SwissLog的四个阶段,包括日志解析,句子嵌入,基于attn的Bi-LSTM,异常检测。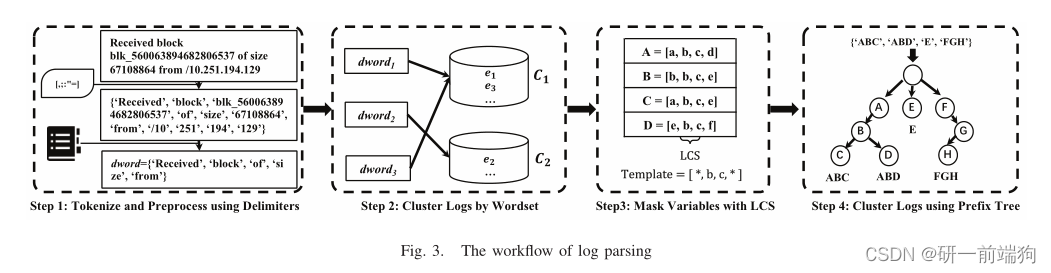
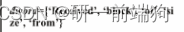

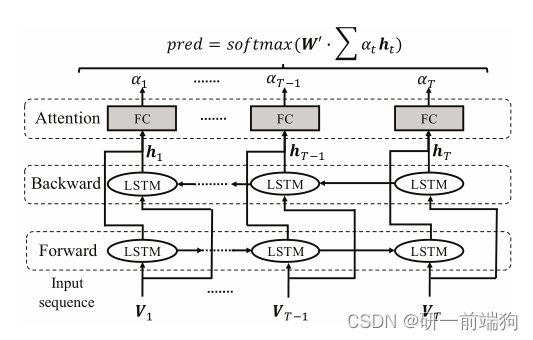 LSTM网络是循环神经网络(RNN)的一种变体,能够捕获序列数据的上下文信息。通过结合门控机制,LSTM可以向cell状态中删除或添加信息,并最终决定要通过哪些信息。它允许神经网络动态地表现时间行为。LSTM网络由三层组成:输入层、隐藏神经元层和输出层。在每个时间步中,LSTM使用输入状态Vt和传输隐藏状态ht−1计算新的单元状态ct和新的隐藏状态ht。Bi-LSTM是LSTM的扩展。特别地,它在backward direction增加了一个隐藏神经元层,通过从两个方向连接作为输入到输出层,计算t时刻的每个隐藏状态ht。 与日志语句中的verbosity level一样,不同的日志语句在日志序列中显示不同的重要性。为了减轻噪声或不重要日志语句的影响,Bi-LSTM引入了注意机制attention mechanisms,为不同的日志语句分配不同的权重。有噪声的或不重要的日志语句往往不被重视。 t时刻的注意函数αt采用全连接层(即图7中的FC层)实现,
LSTM网络是循环神经网络(RNN)的一种变体,能够捕获序列数据的上下文信息。通过结合门控机制,LSTM可以向cell状态中删除或添加信息,并最终决定要通过哪些信息。它允许神经网络动态地表现时间行为。LSTM网络由三层组成:输入层、隐藏神经元层和输出层。在每个时间步中,LSTM使用输入状态Vt和传输隐藏状态ht−1计算新的单元状态ct和新的隐藏状态ht。Bi-LSTM是LSTM的扩展。特别地,它在backward direction增加了一个隐藏神经元层,通过从两个方向连接作为输入到输出层,计算t时刻的每个隐藏状态ht。 与日志语句中的verbosity level一样,不同的日志语句在日志序列中显示不同的重要性。为了减轻噪声或不重要日志语句的影响,Bi-LSTM引入了注意机制attention mechanisms,为不同的日志语句分配不同的权重。有噪声的或不重要的日志语句往往不被重视。 t时刻的注意函数αt采用全连接层(即图7中的FC层)实现,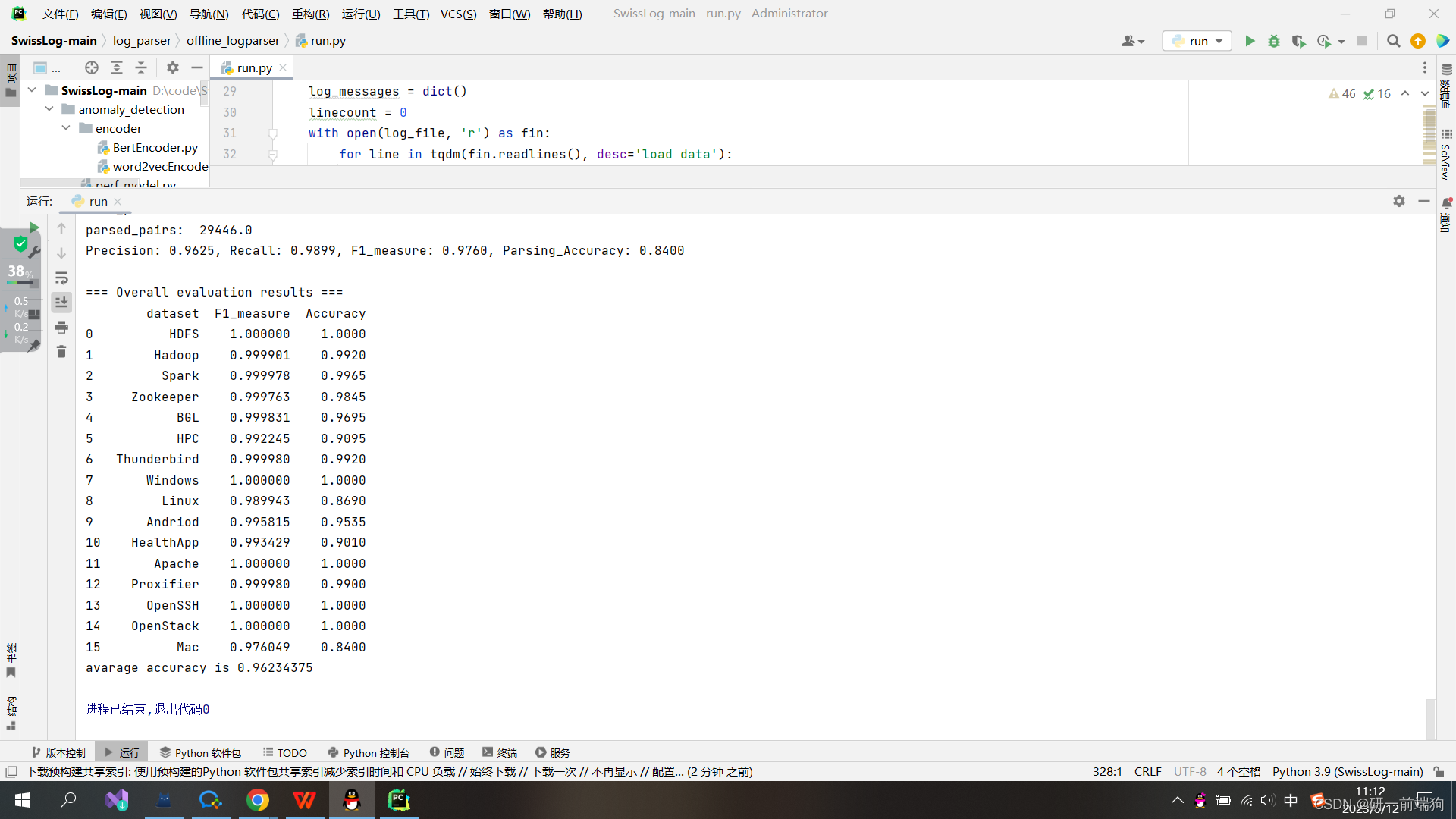 和GitHub上展示的结果,并无异议。
和GitHub上展示的结果,并无异议。【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |