Python数据可视化:Matplotlib、Seaborn、Plotly直方图绘制 |
您所在的位置:网站首页 › 直方图的总结 › Python数据可视化:Matplotlib、Seaborn、Plotly直方图绘制 |
Python数据可视化:Matplotlib、Seaborn、Plotly直方图绘制
|
Statistical Charts(统计图表)
直方图
直方图(Histogram)是一种用于可视化数据分布的图表类型。它将数据集划分成若干个连续的区间(通常称为“箱”或“柱”),然后统计每个区间内数据点的个数或频率。最终,通过绘制垂直的矩形条来表示这些频数,直方图展示了数据的整体分布特征,有助于理解数据的集中趋势、离散程度和分布形状。 以下是直方图的一些重要概念和特点: 箱子(Bins): 数据范围被划分成若干个连续的区间,每个区间称为一个箱子。箱子的宽度可以根据数据范围和需求进行调整。频数(Frequency): 在每个箱子内的数据点个数。直方图的纵轴通常表示频数。频率(Frequency Density): 每个箱子内的频数除以总样本数,表示相对频率。频率可以用来比较不同数据集的分布,因为它不受样本数量的影响。X轴: 表示数据的范围,沿水平轴排列的箱子表示数据点的分布范围。Y轴: 表示频数或频率,沿垂直轴测量箱子的高度。直方图的形状可以提供关于数据集的重要信息: 对称分布: 如果直方图两侧大致对称,数据可能是正态分布或近似正态分布。偏态: 如果直方图的一侧比另一侧更长,数据可能是右偏(正偏)或左偏(负偏),这取决于长尾的方向。峰度: 直方图的峰度表示数据分布的尖峭程度,即数据集中趋势的陡峭度。直方图是数据分析和统计学中常用的可视化工具,能够快速展示数据的分布特征,帮助分析者更好地理解数据。在Python中,matplotlib和seaborn等库提供了绘制直方图的工具。 直方图与柱状图之区别直方图和柱状图都是用于表示数据分布的图表,但它们有一些区别。直方图通常用于表示连续数据的分布,其中横轴表示数据的范围或区间,纵轴表示每个区间内的频数或相对频率。柱状图则更适用于表示离散数据,其中横轴表示不同的类别或项目,纵轴表示与每个类别相关联的数值。 总体而言,直方图强调数据的分布和频率,而柱状图则更强调不同类别之间的比较。 创建直方图 – 指南创建一个直方图涉及几个关键步骤:数据准备、分区、可视化。下面是如何一步一步构建直方图的指南: Step 1: 获取数据创建直方图的第一步是收集数据。 Step 2: 数据准备准备好数据,确保数据进行干净可靠。这可能涉及数据清洗任务。 Step 3: 定义箱子的数量准备好数据后,下一步就是确定箱子的数量。箱子数量的选择通常取决于数据集的大小和可变性。 Step 4: 计算bin的宽度bin:数据的总范围(最大值-最小值)除以箱数。 Step 5: 绘制直方图直接调用api即可。 matplotlib绘制直方图 import matplotlib.pyplot as plt import numpy as np plt.rcParams["font.sans-serif"]=["SimHei"] # 设置字体 plt.rcParams["axes.unicode_minus"] = False # 该语句解决图像中的“-”负号的乱码问题 # 示例数据 data = np.random.normal(loc=0, scale=1, size=1000) # 正态分布的随机数据 # 绘制直方图 plt.hist(data, bins=30, edgecolor='black', density=True) # density=True 表示绘制频率而非频数 # 添加标题和标签 plt.title('随机数据的直方图(正态分布)') plt.xlabel('数值') plt.ylabel('频率密度') # 绘制正态分布的拟合曲线 xmin, xmax = plt.xlim() x = np.linspace(xmin, xmax, 100) p = (1 / (np.sqrt(2 * np.pi))) * np.exp(-0.5 * x**2) plt.plot(x, p, 'k', linewidth=2) # 显示图表 plt.show()绘制正态分布的拟合曲线的每一部分解释如下: xmin, xmax = plt.xlim(): 这一行获取当前绘图区域的x轴范围,然后将其分配给xmin和xmax变量。x = np.linspace(xmin, xmax, 100): 这一行使用NumPy库创建一个包含100个点的线性空间,范围在xmin和xmax之间。这将作为x轴上的点,用于绘制正态分布曲线。p = (1 / (np.sqrt(2 * np.pi))) * np.exp(-0.5 * x**2): 这一行计算对应于每个x值的正态分布概率密度函数(PDF)的值。这里使用的是标准正态分布的PDF,即均值为0,标准差为1的正态分布。plt.plot(x, p, 'k', linewidth=2): 这一行使用Matplotlib的plot函数绘制正态分布的拟合曲线。x是x轴上的点,p是对应的概率密度函数值。'k'表示黑色线条,linewidth=2指定线条的宽度为2。因此,整个代码段的目的是在当前的Matplotlib绘图中添加一个标准正态分布的拟合曲线。如果之前有其他绘图或数据,这段代码将在已有的图上添加这条曲线。
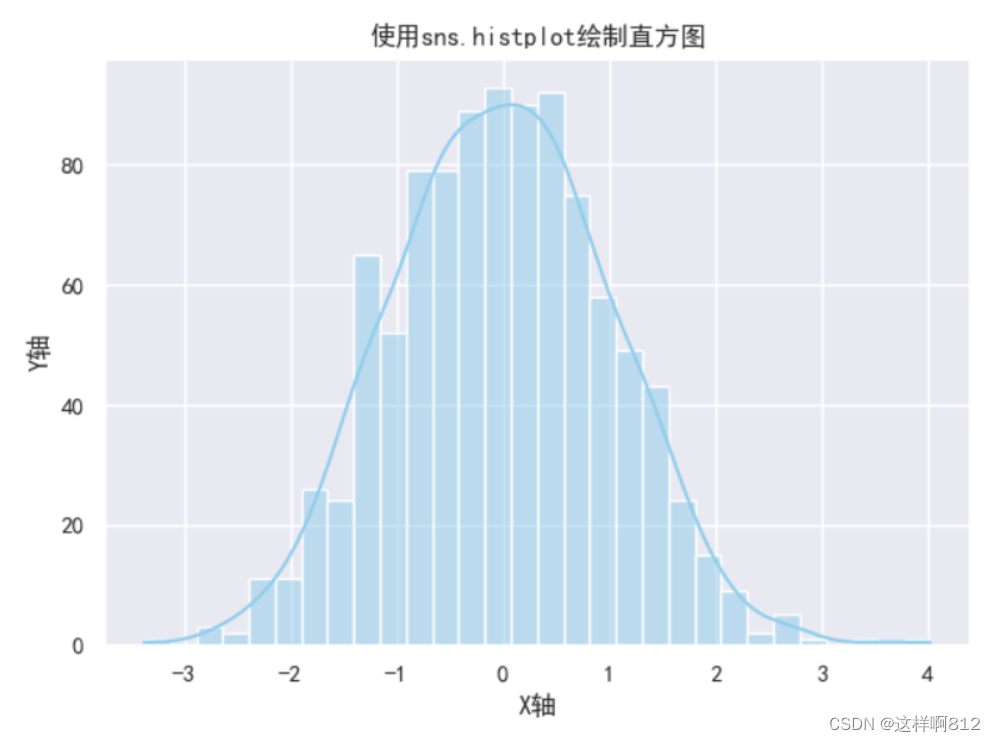
histplot 和 displot 是Seaborn库中用于绘制数据分布的两个不同函数(基本上用法一样,绘制的图也一样): histplot histplot 是Seaborn中的一个函数,用于创建直方图(histogram)。histplot 可以绘制单变量数据的直方图,可以选择是否添加核密度估计(KDE)曲线来更好地可视化数据的分布。 import seaborn as sns import matplotlib.pyplot as plt import numpy as np plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题 sns.set(rc={'font.sans-serif': ['simhei', 'Arial']}) # 处理图形显示中文乱码问题 # 示例数据 data = np.random.randn(1000) # 生成服从标准正态分布(均值为0,标准差为1)的随机数 # 创建直方图和核密度估计曲线 sns.histplot(data, kde=True, bins=30, color='skyblue') # 添加标题和标签 plt.title('使用sns.histplot绘制直方图') plt.xlabel('X轴') plt.ylabel('Y轴') # 显示图形 plt.show()sns.histplot 函数创建直方图。kde=True 参数表示显示核密度估计曲线,bins=30 指定直方图的箱数(用于将数据范围划分为离散间隔的数量),color='skyblue' 设置直方图的颜色。 如果需要直方图的y轴显示为频率,则在histplot函数加上这个参数:stat='density'
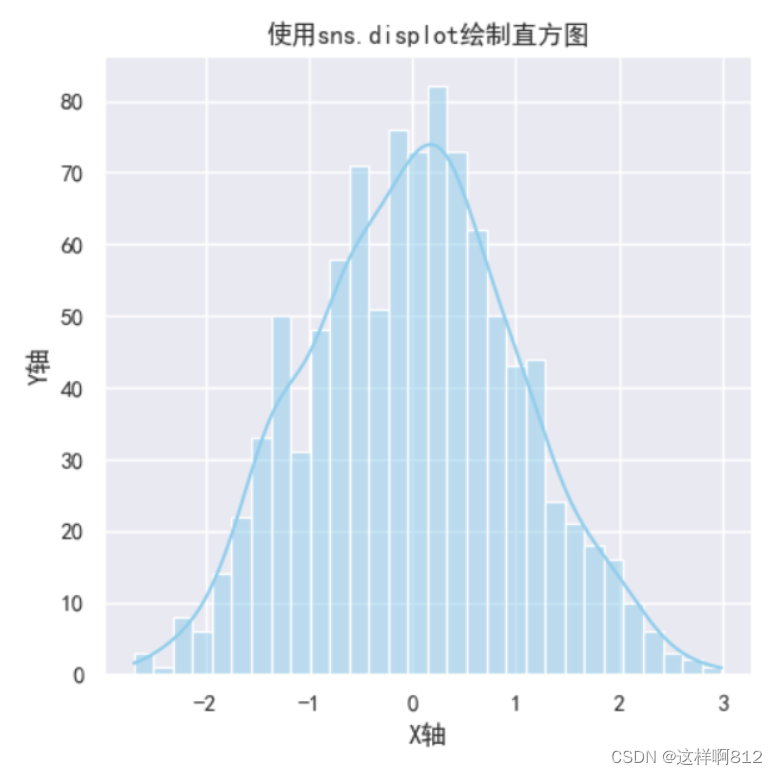
从上面的实例程序中可以看出seaborn对于matplotlib绘制直方图更加简化了,不需要写复杂的“绘制正态分布的拟合曲线”部分代码,直接用kde=True就解决了这个问题。 displot displot 也用于绘制数据分布,但它更通用,可以在一张图中同时显示直方图和核密度估计,以及可选的拟合参数分布。displot 可以用于单变量或双变量数据的分布可视化,并且可以在一个图中展示更多信息,例如数据的形状、中心趋势和离散度。单变量数据 import matplotlib.pyplot as plt import seaborn as sns import numpy as np plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题 sns.set(rc={'font.sans-serif': ['simhei', 'Arial']}) # 处理图形显示中文乱码问题 # 示例数据 data = np.random.randn(1000) # 生成服从标准正态分布(均值为0,标准差为1)的随机数 # 绘制直方图和核密度估计曲线 sns.displot(data, kde=True, bins=30, color='skyblue') # 添加标题和标签 plt.title('使用sns.displot绘制直方图') plt.xlabel('X轴') plt.ylabel('Y轴') # 显示图形 plt.show()如果需要直方图的y轴显示为频率,则在displot函数加上这个参数:stat='density'
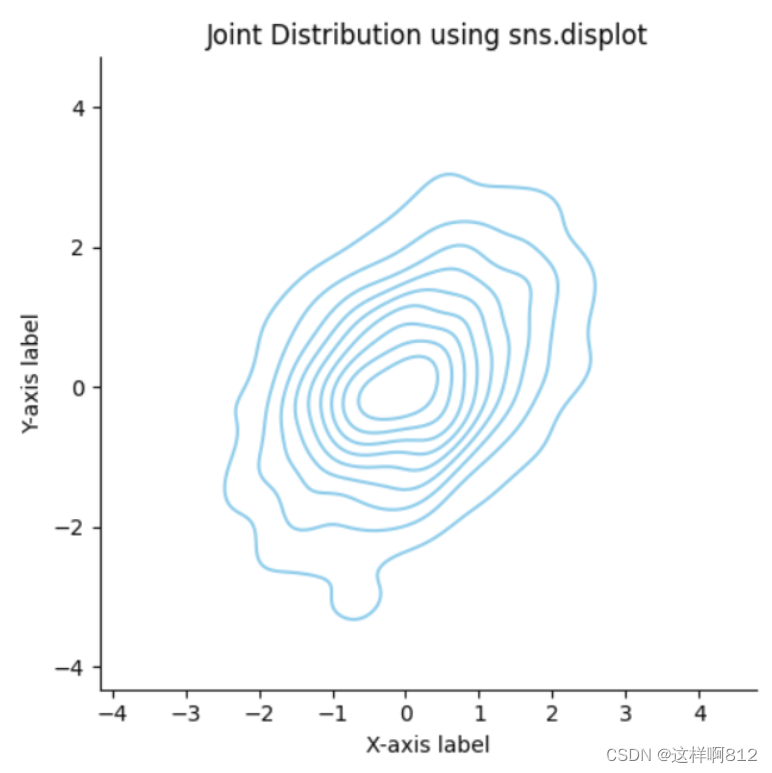
双变量数据 import seaborn as sns import matplotlib.pyplot as plt import numpy as np # 生成两个相关的随机变量 np.random.seed(42) x = np.random.randn(1000) y = 0.5 * x + np.random.randn(1000) # 使用 displot 绘制双变量的分布图 sns.displot(x=x, y=y, kind='kde', color='skyblue') # 添加标题和标签 plt.title('Joint Distribution using sns.displot') # Joint Distribution:联合分布 plt.xlabel('X-axis label') plt.ylabel('Y-axis label') # 显示图形 plt.show()“Joint Distribution”(联合分布)是指两个或多个随机变量在同一概率空间中的联合概率分布。它描述了这些变量之间的依赖关系以及它们如何共同变化的规律。
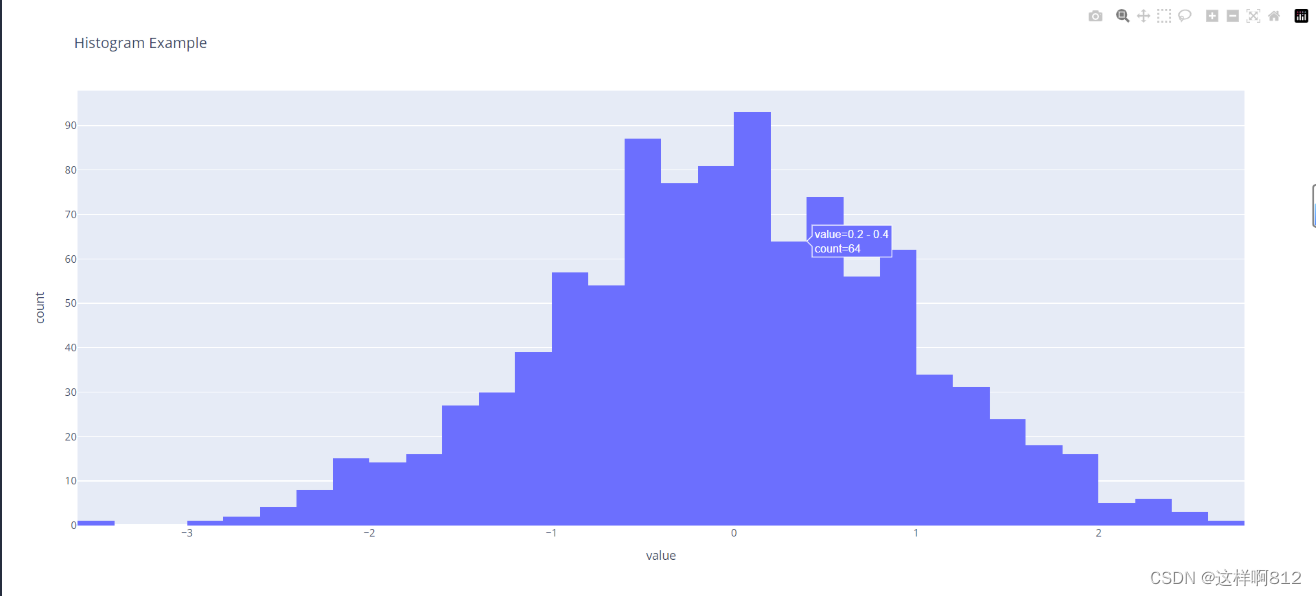
简单例子 import plotly.express as px import pandas as pd import numpy as np # 创建一个示例数据集 data = pd.DataFrame(np.random.normal(0,1,1000), columns=["value"]) # 使用Plotly Express创建直方图 fig = px.histogram(data, x='value', title='Histogram Example') # 显示图表 fig.show()
箱线图 箱线图(Boxplot)是一种用于显示数据分布情况的图表类型。它显示了数据的中位数、四分位数(上下四分位数),以及异常值的位置。箱线图通常由一个矩形框(箱体)、两条竖直线(上下边缘,也称为“箱须”),以及可能的异常值点组成。 箱体代表了数据的中间50%范围,也就是数据的第二(上四分位数Q1)和第三(下四分位数Q3)个四分位数之间的距离。箱线的长度表示了数据的离散程度,而中间的线表示了数据的中位数。箱须通常延伸到数据中的最大值和最小值,但不包括异常值。 箱线图的主要优点在于它提供了一种直观的方式来比较不同数据集之间的位置、离散程度和异常值情况。通过箱线图,你可以快速地了解数据的分布特征,并识别潜在的异常值。此外,箱线图也可用于检测数据的对称性和偏态性。 import plotly.express as px import pandas as pd import numpy as np # 创建一个示例数据集 data = pd.DataFrame(np.random.normal(0,1,1000), columns=["value"]) # 使用Plotly Express创建直方图 fig = px.histogram(data, x='value', marginal='box', # 参数marginal='box'用于在直方图的边缘添加箱线图。 title='Histogram Example') # 显示图表 fig.show()
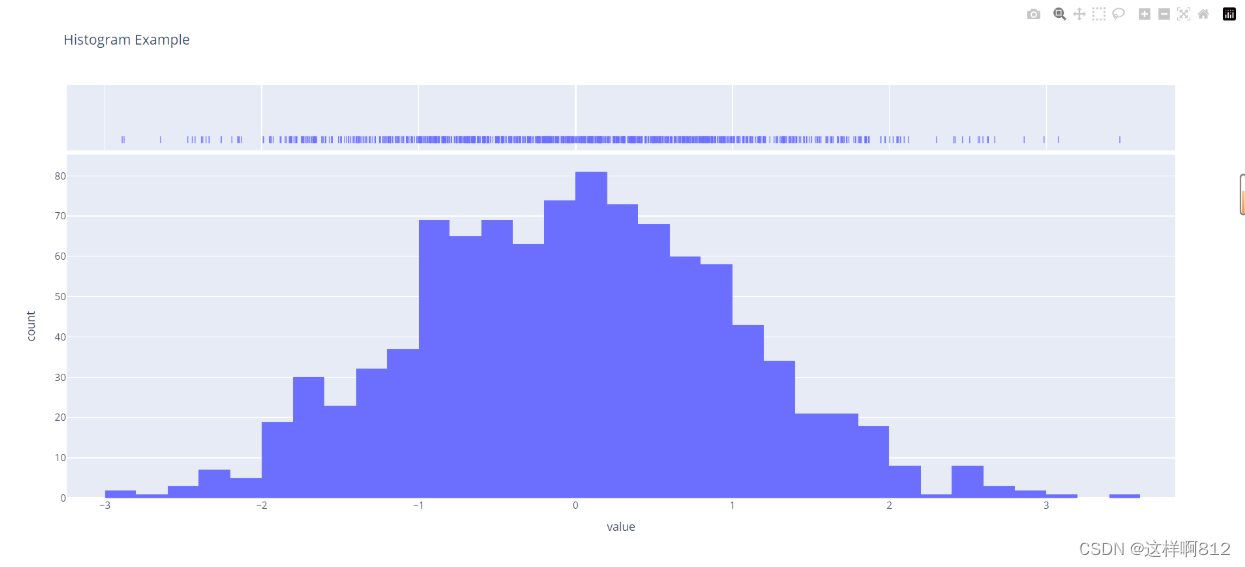
地毯图 地毯图(rug plot)是一种数据可视化工具,通常用于在一维数据分布上显示每个数据点的位置。它的作用在于提供了一种直观的方式来显示数据的分布情况,并且可以与其他类型的图表结合使用,例如直方图或密度图,以提供更全面的数据展示。 地毯图的原理很简单:在一维轴线上,对于每个数据点,绘制一个垂直的线段(或“毛毯上的线”),表示该数据点的位置。这些线段的密集程度可以反映数据的密度,而线段的分布情况则反映了数据的分布范围。 地毯图的优点之一是它能够显示出数据的离散性和分布的集中程度,而无需汇总数据。它通常用作辅助图形,与直方图、密度图或箱线图等结合使用,以提供更全面的数据分析和可视化。 修改marginal参数值为'rug'即可。
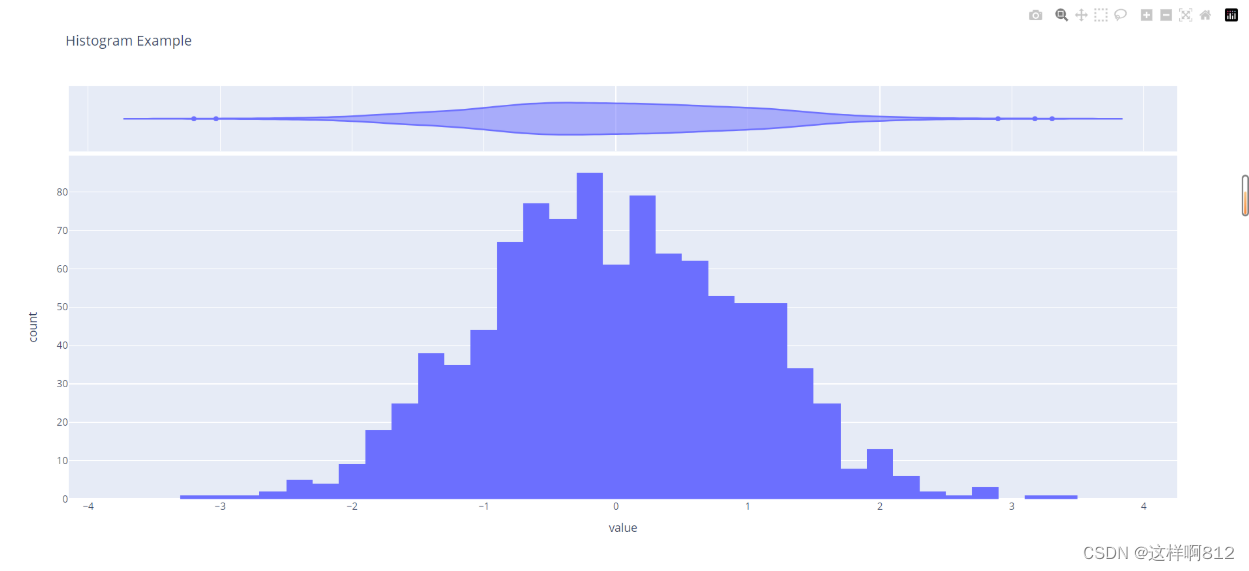
小提琴图 小提琴图(violin plot)是一种用于可视化数据分布的图表类型。它结合了箱线图和核密度估计图的特点,能够同时展示数据的位置、分布形状和密度。小提琴图通常沿着一个连续的变量绘制,以显示数据在该变量上的分布情况。 小提琴图的外形类似于小提琴,中间的粗部分表示数据的主体密度,而两端的尖部表示数据的稀疏区域。通过小提琴图,可以直观地比较不同组或类别之间的数据分布情况,以及数据的中心趋势和离散程度。 小提琴图的优点之一是它能够同时显示多个组或类别之间的数据分布情况,从而更直观地比较它们的特征。它也能够有效地识别数据的多模态性(多峰分布)、异常值以及密度差异等特征。 修改marginal参数值为'violin'即可。
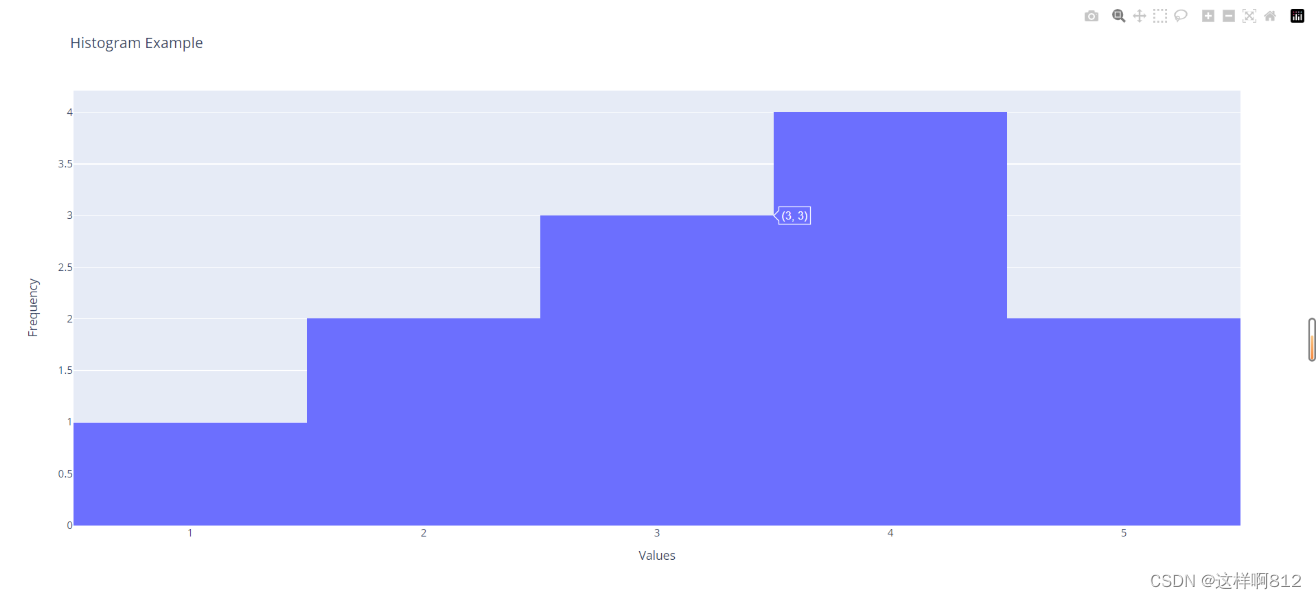
使用plotly.graph_objects创建直方图相对于plotly.express更为底层,但它提供更大的灵活性。下面是一个使用plotly.graph_objects创建直方图的示例代码: import plotly.graph_objects as go import pandas as pd # 创建一个示例数据集 data = pd.DataFrame({'Values': [1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5]}) # 创建直方图 fig = go.Figure() # 添加直方图的数据和布局 trace = go.Histogram(x=data['Values'], nbinsx=5, name='Histogram') fig.add_trace(trace) # 设置布局 fig.update_layout(title='Histogram Example', xaxis_title='Values', yaxis_title='Frequency') # 显示图表 fig.show()与plotly.express相比,使用plotly.graph_objects需要更多的手动设置,但它允许更大程度的定制。你可以根据需要调整图表的各个方面。
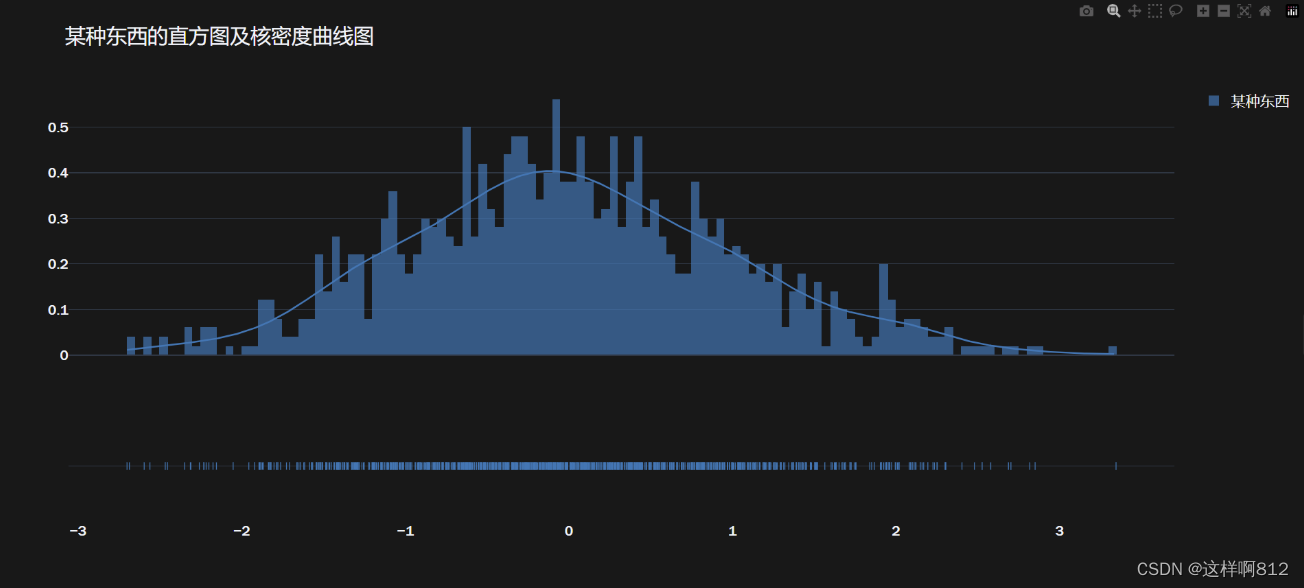
分布图(Distribution Plot)是一种同时显示数据分布直方图和核密度曲线的图表类型。 一个数据组的情况 import numpy as np import plotly.figure_factory as ff # 生成一个数据组的示例数据 data = list(np.random.randn(1000)) # 使用Plotly的figure_factory创建分布图 fig = ff.create_distplot(hist_data=[data], group_labels=['某种东西'], bin_size=0.05, show_hist=True, show_curve=True, curve_type='kde') # 设置图表样式为暗色主题 fig.layout.template = 'plotly_dark' # 更新图表布局,设置标题和字体样式 fig.update_layout(title='某种东西的直方图及核密度曲线图', font=dict(size=17, family="Franklin Gothic")) # 显示生成的图表 fig.show() ######################### ff.create_distplot函数参数说明 #################################### # hist_data:包含数据的列表的列表,每个子列表是一个数据组 # group_labels:数据组的标签,对应于 hist_data 中的每个子列表 # bin_size:直方图箱子的大小 # curve_type:曲线类型,可选值包括 'kde'(核密度曲线)和 'normal'(正态分布曲线),默认为"kde" # show_hist:是否显示直方图,默认为 True # show_curve:是否显示曲线,默认为 True # histnorm:直方图归一化参数,可选值包括 'probability'(概率密度)和 'percent'(百分比)
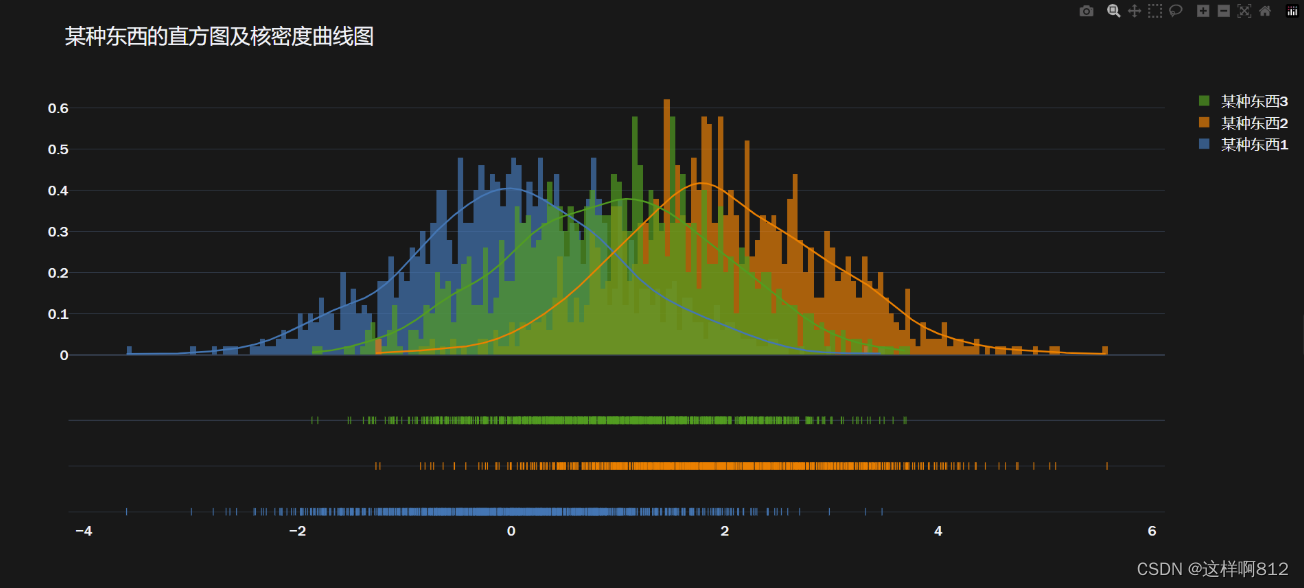
多个数据组的情况 import numpy as np import plotly.figure_factory as ff # 生成一些示例数据 data = list(np.random.randn(1000)) # 生成符合标准正态分布的1000个数据点 data_2 = list(np.random.normal(2,1,1000)) # 生成均值为2,标准差为1的正态分布的1000个数据点 data_3 = list(np.random.normal(1,1,1000)) # 生成均值为1,标准差为1的正态分布的1000个数据点 # 使用Plotly的figure_factory创建分布图 fig = ff.create_distplot(hist_data=[data, data_2, data_3], group_labels=['某种东西1', '某种东西2', '某种东西3'], bin_size=0.05, curve_type='kde') # 设置图表样式为暗色主题 fig.layout.template = 'plotly_dark' # 更新图表布局,设置标题和字体样式 fig.update_layout(title='某种东西的直方图及核密度曲线图', font=dict(size=17, family="Franklin Gothic")) # 显示生成的图表 fig.show()
plotly.figure_factory 和 plotly.express 都是 Plotly 库的子模块,用于创建交互式数据可视化图表,但它们之间有一些重要的区别: 复杂度: plotly.figure_factory 旨在创建一些相对复杂的图表,如统计图表、子图、分布图等。这些图表通常需要更多的参数和设置,因此适用于更高级的可视化需求。plotly.express 旨在创建简单且快速的图表,通常仅需几行代码即可生成常见的图表类型。这对于快速的探索性数据分析非常有用。 数据输入: plotly.figure_factory 通常需要输入原始的数据或数据框 (DataFrames),并需要手动指定数据的分布、箱线图等内容。plotly.express 更适合处理已经整理好的数据框 (DataFrames),并提供了一种更高级的界面,可以根据列名轻松地生成图表。 代码复杂度: 使用 plotly.figure_factory 创建图表通常需要更多的代码,因为你需要手动配置图表的各种属性。plotly.express 提供了更简洁的API,通常可以使用一行或几行代码创建图表,减少了代码复杂性。 适用场景: plotly.figure_factory 适用于需要更高级定制或者创建复杂图表的场景,例如需要同时显示多个子图或进行更多统计分析的情况。plotly.express 适用于快速生成常见图表的场景,特别是对于初学者或需要快速生成可视化的数据科学家来说,它提供了更直观的工具。综上所述,选择使用 plotly.figure_factory 还是 plotly.express 取决于你的具体需求和数据可视化的复杂程度。如果你需要创建复杂的图表或需要更高度的自定义,可以选择使用 plotly.figure_factory。如果你只需要简单而快速地创建常见的图表,那么 plotly.express 是更好的选择。 结尾Matplotlib、Seaborn和Plotly是Python中三种强大的数据可视化工具,各自在直方图绘制方面有独特优势。Matplotlib提供灵活性,Seaborn美观且简化代码,Plotly则以交互性和在线分享脱颖而出。通过学习本文提供的示例,读者能更自信地选择适用于不同场景的工具,为数据赋予生动形式,更好地传达信息。希望本文对读者在Python数据可视化的实践中提供有益的指导,助力取得更大成功。 |

 直方图添加其他图形
直方图添加其他图形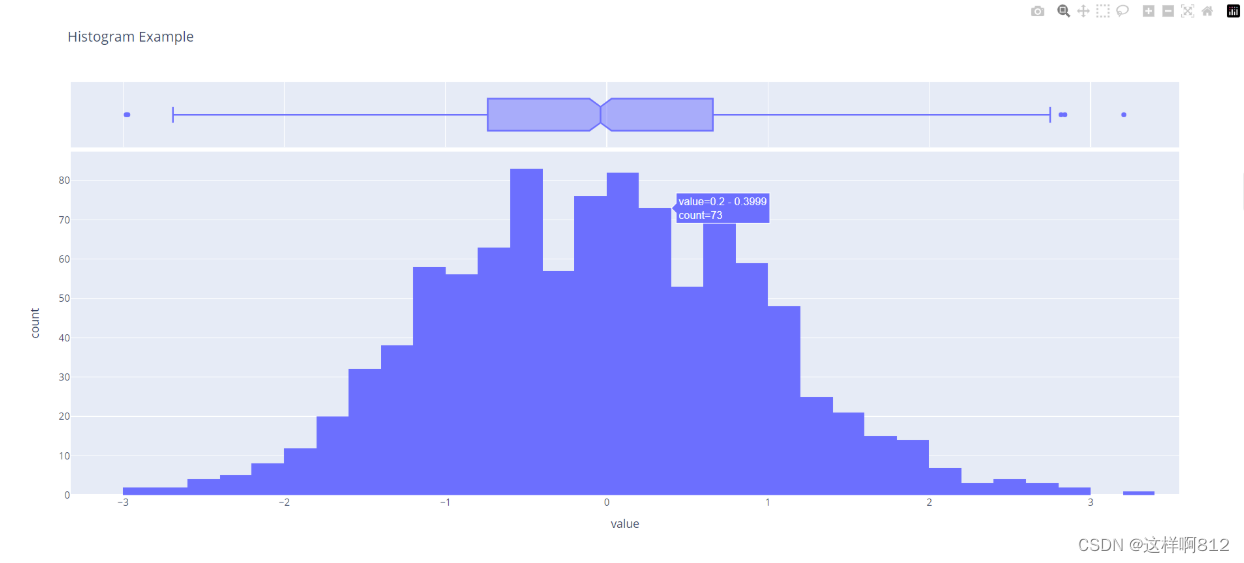
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |