(详细)分层强化学习 |
您所在的位置:网站首页 › rnd1鞋子 › (详细)分层强化学习 |
(详细)分层强化学习
|
EXPLORATION BY RANDOM NETWORK DISTILLATION
RND这类文章是基于强化学习在解决Atari游戏中蒙德祖玛的复仇的困境提出的。由于在这类游戏中存在非常稀疏的奖励,Agent在探索利用上存在很大的问题。RND也是第一个使用与人类平等的RL算法在蒙特祖玛的复仇上获得人类水平成绩的算法。 为提升稀疏奖励情况下的探索利用,之前有很多类似Curiosity、count-based的方法,但问题是,这些方法很难在大规模环境下使用(或者高维连续状态或动作),因为对于绝大多数的状态,count都是1或者0。RND提出了一种只需要做前向传播就能很好计算得到的探索奖励。 一个容易理解的事实是,神经网络的输入和训练样本相似时,具有更小的error,这给了一个可以使用agent过去的经验的预测误差来估计新经验探索性的启发。但直接利用这发方法会导致agent更倾向于探索具有随机性的状态转移(例如有的状态转移是完全随机的事件例如投硬币等等)。为了解决这种倾向随机的问题,RND使用了一个确定的随机初始化的神经网络,来预测当前状态的输出,进而确定这个探索奖励。 定义总奖励值 RND使用两个神经网络:一个固定、随机初始化的target network和另一个使用数据训练的predictor network。target network是一个输入映射 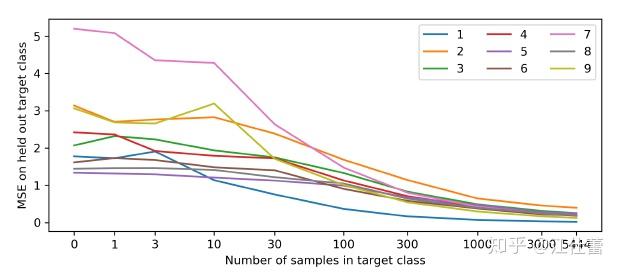
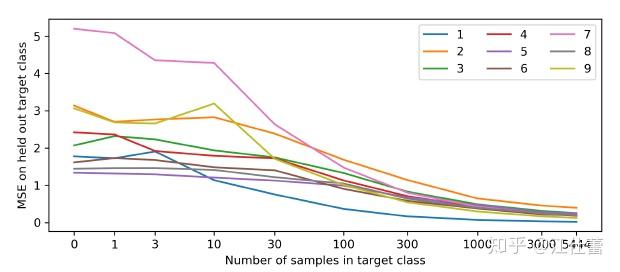
从上图能看到样本在训练数据中越新MSE越大。predictor可以理解为在向着“随机”的方向在优化。 进一步考虑在RL中使用这种方法模拟随机网络的MSE来源: 训练样本的分布;显然样本本身分布的变化,特别是之前很少见的样本会带来MSE增大;随机的状态转移;类似上面我们提到过的一些状态下状态转移的随机性很强,与动作决策的相关性较差;这个问题也可以成为被局部熵陷阱吸引模型的不确定性;不完全可观或观测不足;模型学习的问题;优化器不能很好的模仿target network。其实可以简单分一下:1是我们希望看到的结果;2是我们希望避免优化的方向;3是不可控的部分;4要么是可以通过改进优化器和参数避免,要么就是玄学问题。由于RND的target network是确定的,不会随着predictor的训练而受到数据或环境的局部熵影响,因此可以很好的避免2。 文章还讨论了RND网络蒸馏方法和不确定度量化之间的关系。假设我们的回归问题的数据集是 用 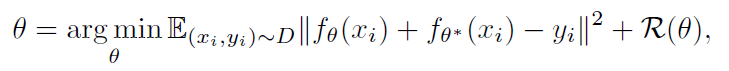
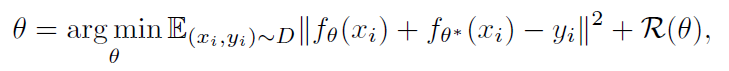
其中, 当回归目标 回到RND本身上来,由于在环境本身奖励 但是,只依赖 对于target network,由于未进行训练,因此很难适应新样本的规模和分布,因此,对输入target network和predictor的状态进行了归一化(减均值除以标准差,一般会让agent先随便跑几步得到一个简单的均值和标准差结果就行);同时,为了让 效果:在蒙特祖玛的复仇上还是非常显著的 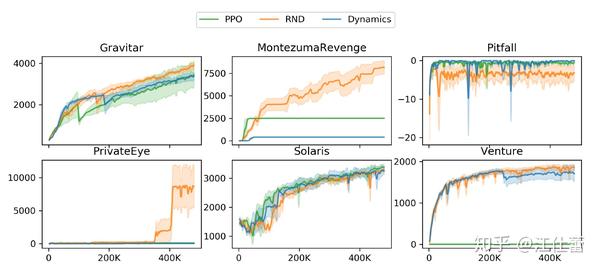
RND的伪码: 

除了归一化参数的部分外,主要的差别就是使用了distillation network来作为值函数的估计网络,并用探索奖励和环境奖励合并,来求优势函数更新策略网络。 |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
|
图片新闻 |
|
专题文章 |