| Logistic 回归简明教程: 原理、SPSS操作、结果解读与报告撰写 | 您所在的位置:网站首页 › 病例对照研究的原理图怎么画 › Logistic 回归简明教程: 原理、SPSS操作、结果解读与报告撰写 |
Logistic 回归简明教程: 原理、SPSS操作、结果解读与报告撰写
|
如果结局是分类变量,回归分析主要分析影响阳性事件发生的因素,预测阳性事件的发生。在本文案例中,冠心病的发生是需要探讨的阳性事件。 影响与预测阳性事件发生,可以用概率P来表示。P值越大,阳性事件发生的可能越大。如果一个因素可以导致概率P增大,说明该因素是重要的影响因素或者预测因素。 借鉴线性回归的原理,我们希望建立起一个关于P的线性函数:
遗憾的是,P与x的关系并不符合线性回归分析所要求的线性关系前提条件(它们的关系是S型曲线的关系),因此方程无法成立。 之前推文介绍过,线性回归若线性条件不符合,可以对Y或者X进行转换,以满足线性回归的要求。因此,统计研究者对P进行了转换,称之为logit转换,或者logit(P):
于是,我们就建立了关于P与结局的转换线性关系,这一回归模型被称之为广义线性模型,其中logit(P)的转换模型叫做Logistic回归。 只从数据本身考虑的话,Logistic回归模型都是包括一个分类因变量及若干自变量(可以是分类变量,也可以是连续变量),反映了m个自变量对因变量的线性影响。无论对于病例对照研究还是队列研究,这种形式都是不变的。 基于上述公式,我们可基于多个自变量预测结局Y。上述公式可以转为以下关于P的更直接的公式:
比如有一名患者,女性、年龄57岁、心电图ST段重度异常、同时患有高血压和糖尿病,则可计算得到她患冠心病的概率为0.961。相反,如果另一名患者为女性、年龄49岁、心电图ST段轻度异常、同时糖尿病而无高血压,则她患冠心病的概率是0.262。 这一概率就是回归分析的预测值,预测值显然与实际值有差异(详细可以阅读文章线性回归时,你还不会做残差分析?来看基本教程!)。比如第一名患者实际值是1(发生冠心病),真实值与实际值之间的差异是0.039,这一差异便是前文介绍过的残差。同样,第二名患者实际值是0(未发生),残差是-0.262。 好的模型,残差越小越好,残差均方越小越好。因此,logistic回归模型中,残差也是非常重要的评价指标。 3、Logistic OR值计算Logistic回归核心的功能之一是研究影响因素,它用于评价暴露因素影响程度的指标是OR值。 关于OR值,我在前文有详细的介绍(病例对照研究的基本统计分析策略)。观察性研究无论是横截面调查、病例对照研究或者队列研究,经常需要借助OR值暴露因素效应值,实际上实验性研究也经常使用该指标来评价干预措施的疗效。OR值指的是,优势比/比数比(odds ratio,OR)。优势(odds)是指二分类事件中一类事件相对于其对立事件的优势。病例组中优势是暴露者数/非暴露数,对照组中暴露数/非暴露数。
Logistic回归分析,实际上也是关于优势的回归模型。诸位稍微思考思考可以放发现a/(a+c)、b/(b+d)便是P,c/(a+c), d/(b+d)是1-P。a/(a+c) 除以c/(a+c) 即P/1-P,即阳性事件的优势。因此,可以得到以下的公式:
现在如果要探讨性别的影响,男性与女性的差异,可以从两个角度来分析讨:第一,计算回归系数β1,说明性别变量X对Y的影响;第二,计算OR值,两者是等同的,男性相对女性的影响回归系数b值等于ln(OR)值。
简而述之:
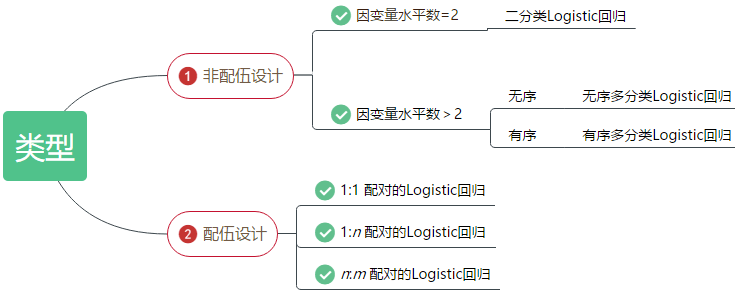
OR值大于1,提示暴露因素是阳性事件发生的促进因素; OR值小于1,提示暴露因素是阳性事件发生的阻碍因素; OR值等于1,提示暴露因素对阳性事件的发生无影响。 相对来说,OR值比b值在解释对结局的影响上更有意义,它能够说明结局Y风险增加的程度。比如OR=2,大致可以说明暴露因素增加发生阳性结局1倍的概率(千万注意,此处只能说大致、左右,原因后续再论) 医学研究中,风险大小估计是重要的内容。由于能够巧妙地计算OR值,Logistic回归在医学领域大受欢迎,特别是病例对照研究。 4、Logistic回归分析类型依据研究设计不同,可分为非条件Logistic回归模型和条件Llogistic回归模型。非条件Logistic回归用于成组设计的观察性研究,而条件Logistic 回归一般用于匹配设计研究。 依据因变量类型(水平数量),又可分为二分类Logistic回归模型和多分类Logistic回归模型;二分类Logistic回归也称二元Logistic回归(SPSS软件的叫法) 此外,根据多分类因变量是否有序,又可以分为多分类有序logistic回归模型和多分类无序logistic回归模型。
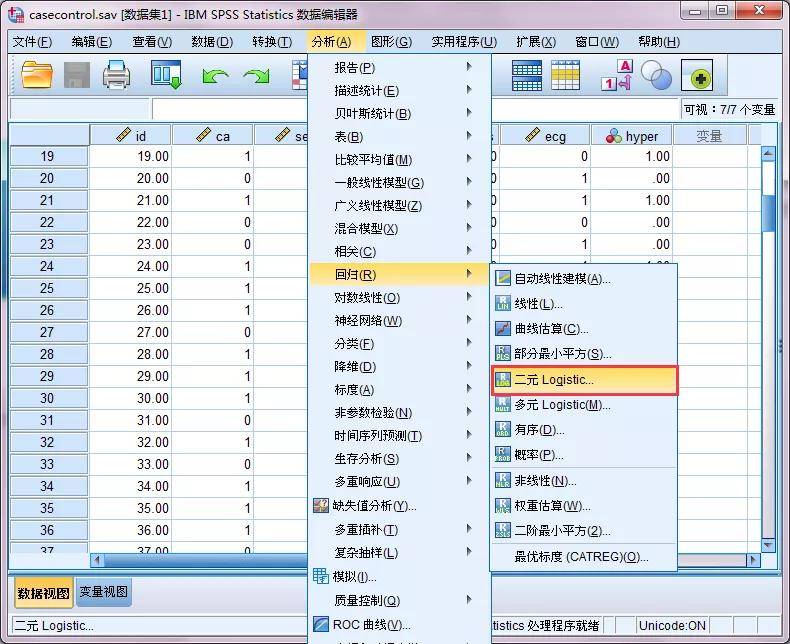
Logistic回归模型分类(本图来源于“医学统计分析学习”) 本研究是基础教程,多分类、配对Logistic回归不再学习范围之内,我就介绍最基本的二分类非Logistic回归分析。本例所采用的方法便是多因素非条件Logistic回归分析。 SPSS操作 1、Logistic回归入口分析--回归--二元Logistic回归
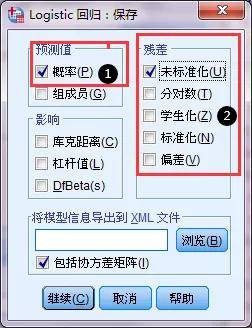
①因变量:放入“是否患有冠心病(ca)” ②协变量:即自变量,放入年龄、性别、心电图表现、糖尿病、高血压 ③保存:可分别计算除预测值(即P值)和残差,残差包括原始残差和标准化残差。
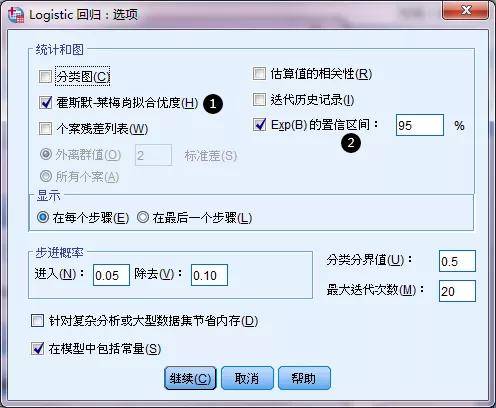
④选项:可计算霍斯黙-莱梅肖拟合优度(Hosmer-Lemesho,H-L检验)(①)、OR值的95%CI置信区间(②)
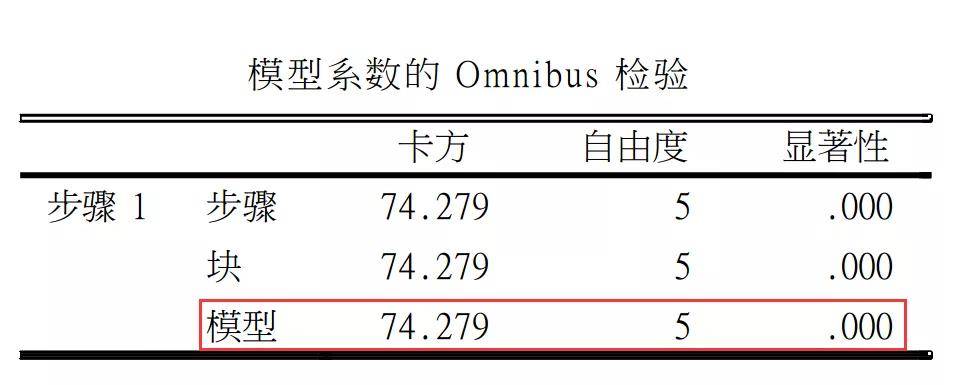
Logistic回归得到诸多结果,初学者仅需要重点关注以下几个表格。 首先提供的是Omnibus Tests of model Coefficients :指的是对模型的总的全局检验,为似然比检验。
结果里面的三行分别指的是:步骤(step)统计量是每一步与前一步的似然比检验结果,块(block)是指将block n与block n-1 相比的似然比检验结果,模型(model) 一行输出了Logistic回归模型中所有参数是否均为0的似然比检验结果,这是总体评价的关键检验。P0.05,则可说明模型拟合优度效果较好,若P |
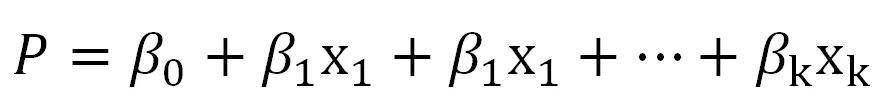
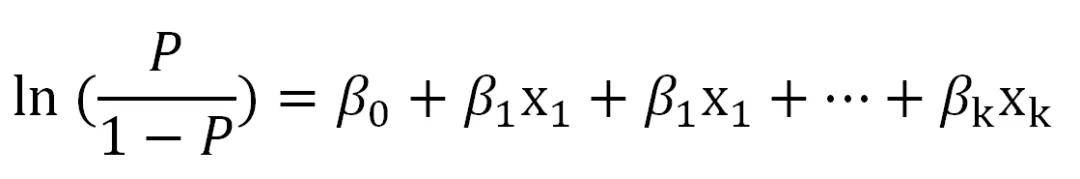
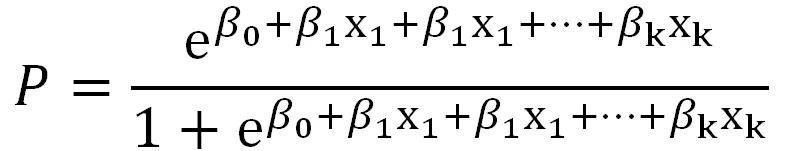

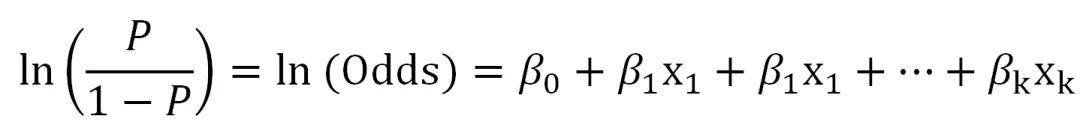
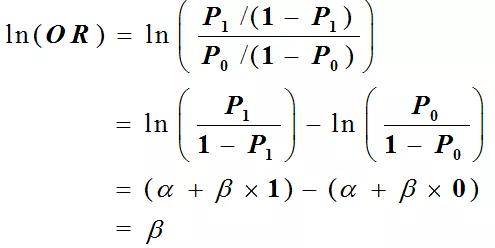


【本文地址】