| 爬取酷狗音乐(思路加代码) | 您所在的位置:网站首页 › 酷狗导入mp3音乐 › 爬取酷狗音乐(思路加代码) |
爬取酷狗音乐(思路加代码)
|
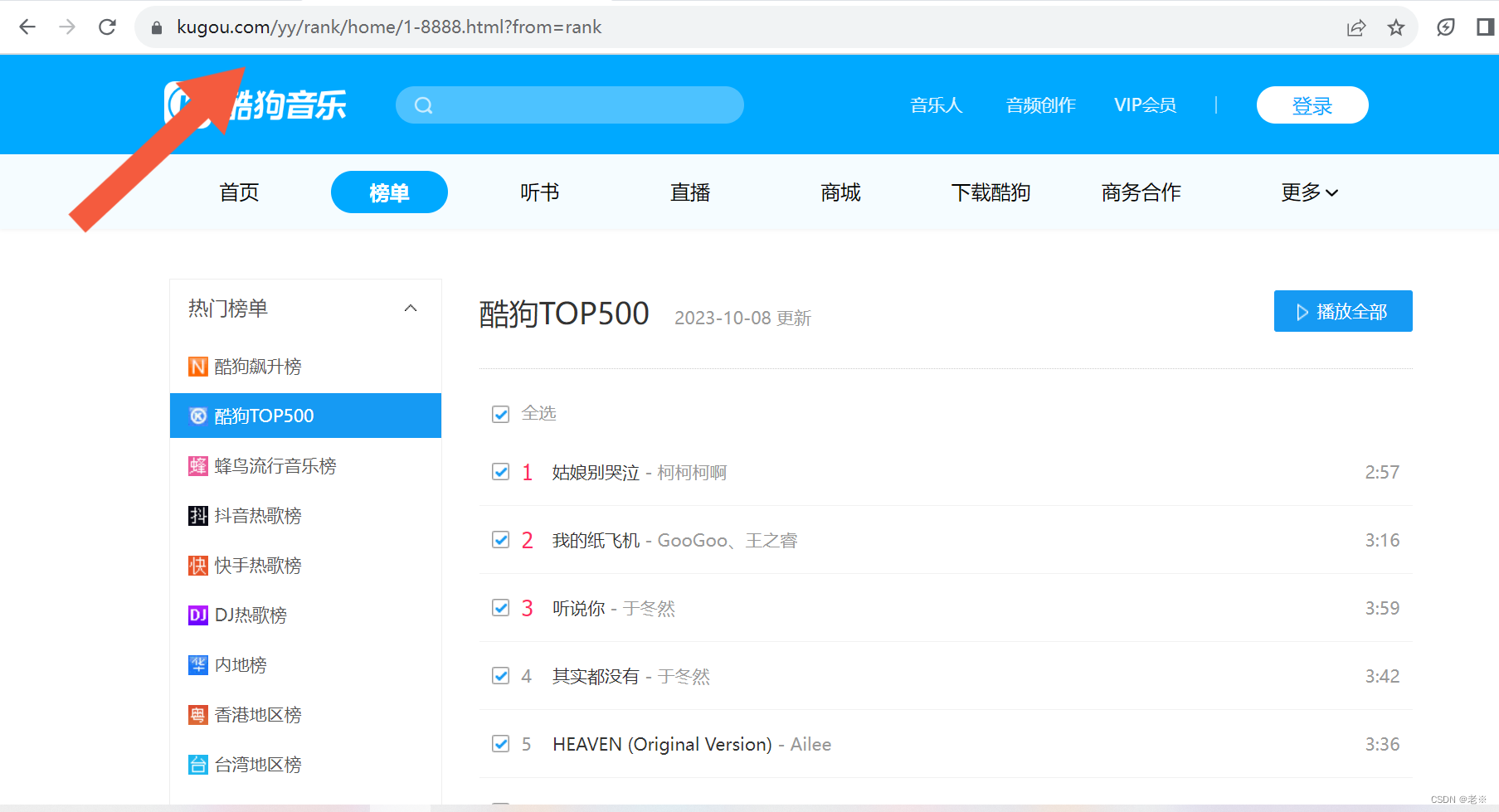
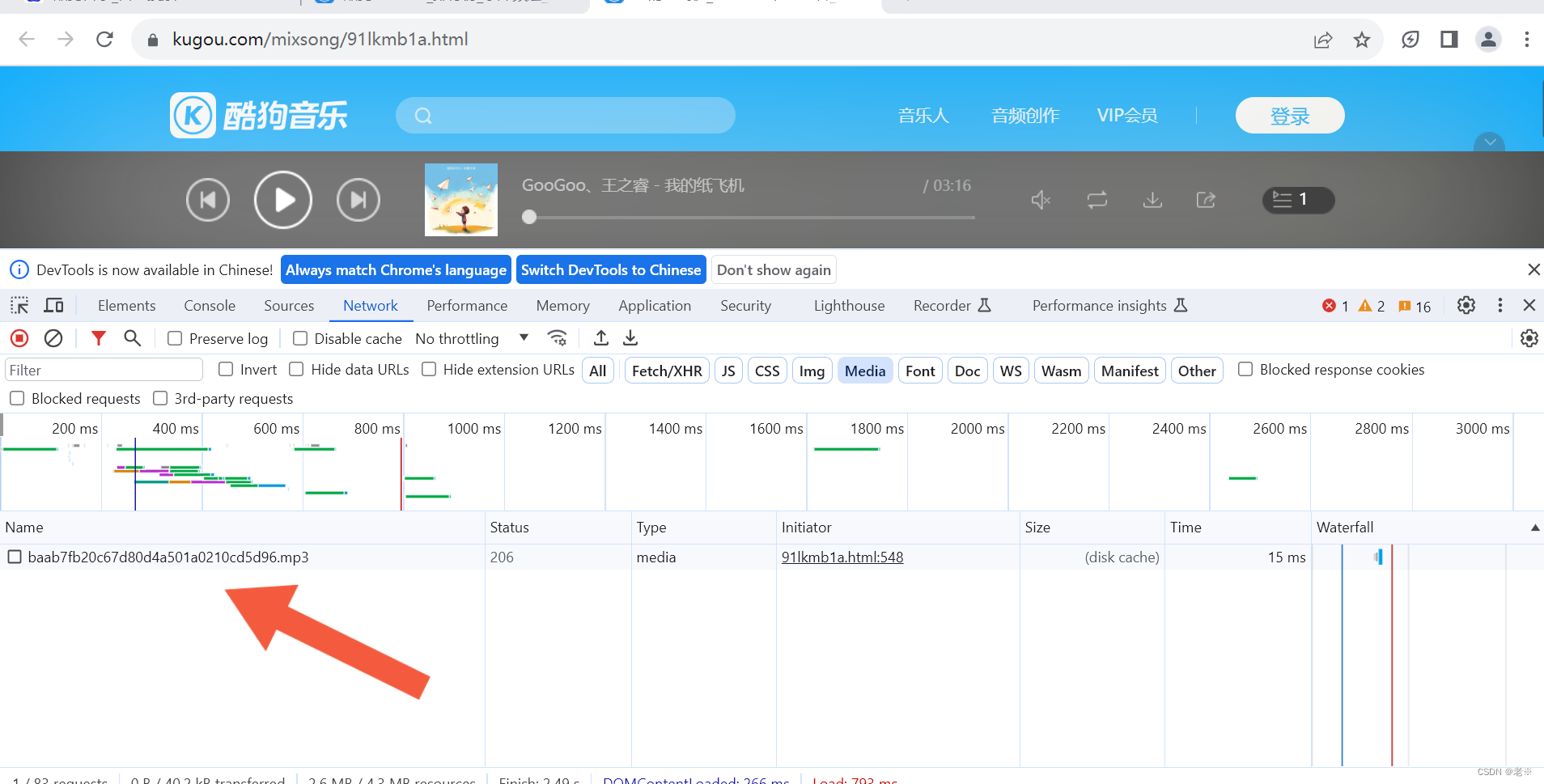
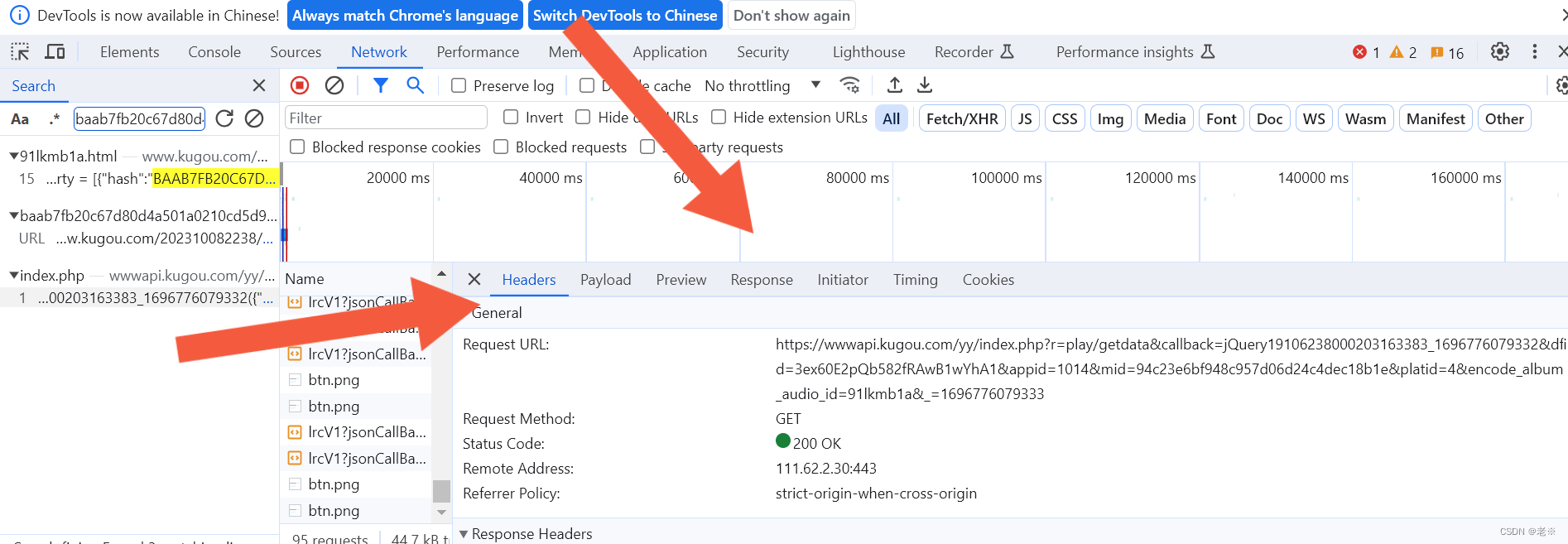
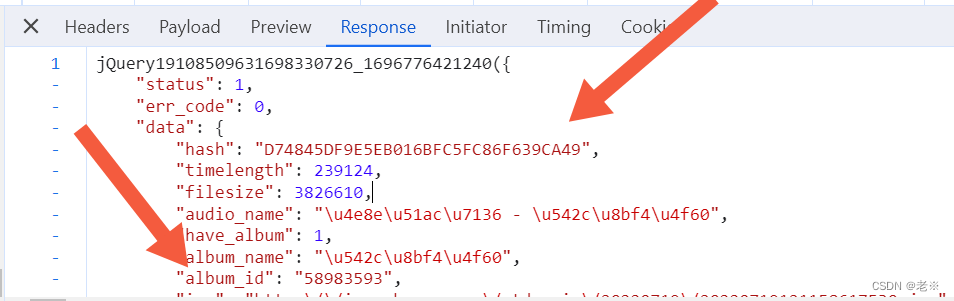
目标网站:酷狗TOP500_排行榜_乐库频道_酷狗网 (kugou.com) 具体页面如下: 1.网页结构分析 1)获取具体音乐的url 在目标页面中【右击】,点击页面检查,在菜单栏点击‘Network’,刷新页面,点击media(媒体),会出现相关数据流'mp3'文件,双击该文件,通过“headers”来看他的request url,在该网址中点击{}.mp3中的音乐文件署名,通过查找(ctrl+F)来查找相关文件信息,查找到‘php’文件,双击随后在‘Preview’下查看信息,会看见hash、album_id、play_url等信息,其中play_url就是我们要找的具体音乐地址,通过它可以去具体下载音乐文件。 首先,这是我们所获取的基础数据流信息。
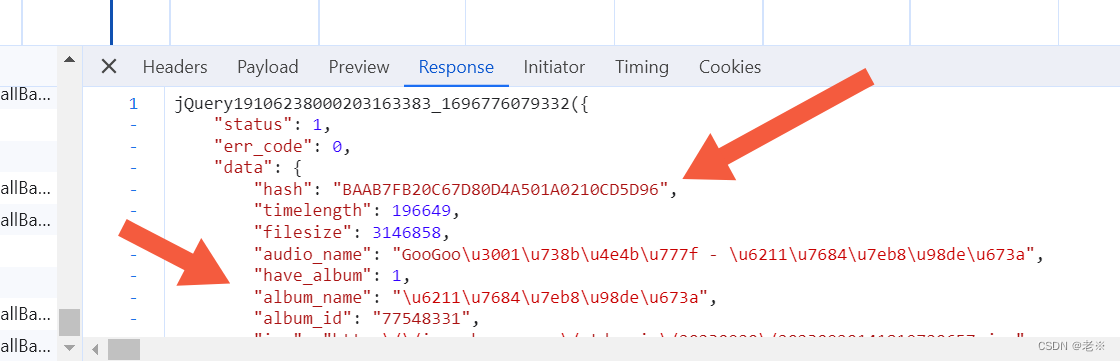
其次,通过它去寻找需要的php文件 再次,我们会得到以下data信息,以两首歌对比为例,会看见其中hash和album_id不同,同时在里面也会看到play_url等。
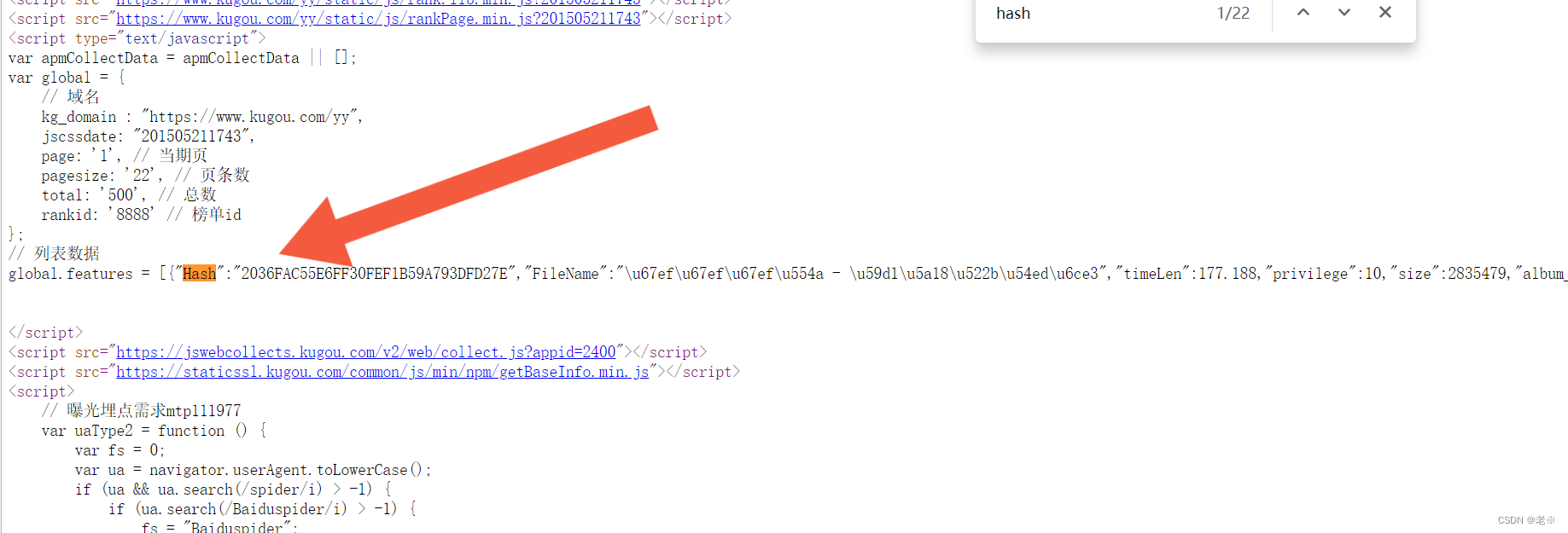
最后,获取到url为play_url,通过它会得到音乐文件。 2、代码分步实现 第一、导入相关的库和设定相关的参数 import requests import re import time其中我们获取到的url也设置出来 url = 'https://www.kugou.com/yy/rank/home/1-8888.html?from=rank'第二、伪装设定并获取页面回应 def get_response(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0' } response = requests.get(url=url,headers=headers) return response第三、函数封装 首先、我们通过对比两首歌曲的php文件的data信息可以看出它们的hash和album_id不同,同时它们也是我们获取play_url这个网站的网址所要的信息。下面的网址就是具体的网址,其中将hash和album_id虚处理。其中的其他信息dfid、mid、以及最后的数字串(时间戳)等都是无关信息。 https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={Hash}&dfid=3ex60E2pQb582fRAwB1wYhA1&appid=1014&mid=94c23e6bf948c957d06d24c4dec18b1e&platid=4&album_id={music_id}&_=1695860308340因此我们就需要来获取到我们所爬取榜单的歌曲的所有对应的hash和album_id
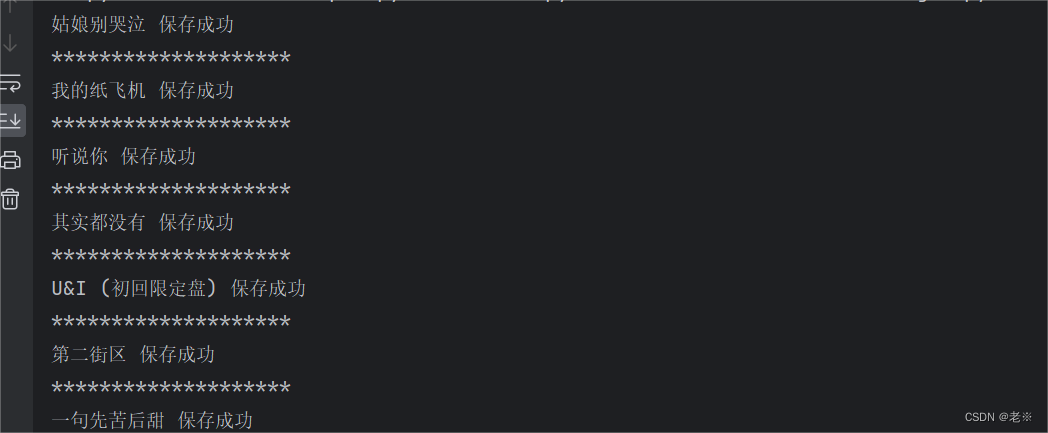
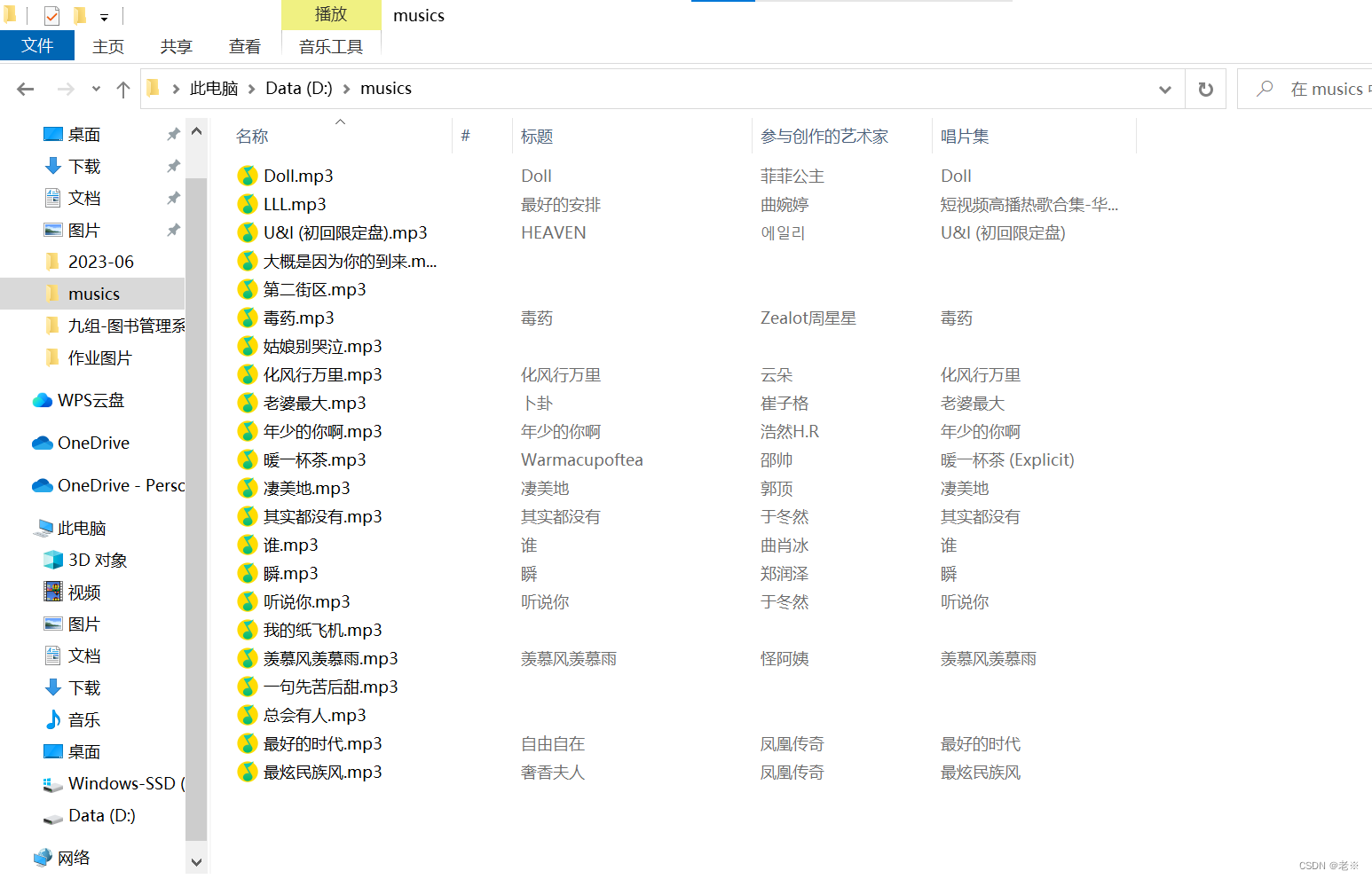
以hash查找为例在榜单页面的具体页面源代码中搜索hash信息,会查找到相关也数据。我们通过下面的封装函数来获取到所有的hash和id。 def get_music_id(url): response = get_response(url) Hash_list = re.findall('"Hash":"(.*?)"',response.text) album_id_list = re.findall('"album_id":(\d+)', response.text) music_id_list = zip(Hash_list,album_id_list) return music_id_list并存储为list 第三、获取网站信息及play_url 通过我们第二步得到的信息,带到网址里面,同时获取到我们的需要的基础信息(标题)等。 def get_music_info(Hash,music_id): """list""" link_list = f'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={Hash}&dfid=3ex60E2pQb582fRAwB1wYhA1&appid=1014&mid=94c23e6bf948c957d06d24c4dec18b1e&platid=4&album_id={music_id}&_=1695860308340' response = get_response(url=link_list) title = response.json()['data']['album_name'] play_url = response.json()['data']['play_url'] music_info = [title,play_url] # print(music_info) return music_info第四、再获取到页面信息后,来进行音乐文件的保存。 def save(title,play_url): music_content = get_response(url=play_url).content with open("D:/musics/{}.mp3".format(title),mode='wb') as f: f.write(music_content) print(title,'保存成功') print('*'*20)以保存到D盘中的music文件为例。以“歌曲的名称”为文件命名,保存为mp3文件。 第五、根据上述函数、步骤综合写出主函数。 def main(url): music_id_list = get_music_id(url=url) for Hash, music_id in music_id_list: try: music_info = get_music_info(Hash, music_id) save(music_info[0], music_info[1]) except Exception as e: pass continue我们在里面加入了try、catch来抛出异常(因为在榜单中有的音乐是),以防止我们对后续歌曲的爬取出现报错。 第六、运行函数 if __name__ == '__main__': url = 'https://www.kugou.com/yy/rank/home/1-8888.html?from=rank' main(url) time.sleep(2)通过带入“url”信息,以TOP500榜单为例,我们进行试爬取。
会看到已经爬取下来,在这我们加上sleep来减缓速度。 同时再看存储文件,已经存储成功。 3、全部代码 import requests import re import time def get_response(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0' } response = requests.get(url=url,headers=headers) return response def get_list_url(url): response = get_response(url) list_url = re.findall(' |


【本文地址】