| DAY44:动态规划(四)整数拆分(递归+DP递推都可以做,注意区别和理解) | 您所在的位置:网站首页 › 递归与非递归区别 › DAY44:动态规划(四)整数拆分(递归+DP递推都可以做,注意区别和理解) |
DAY44:动态规划(四)整数拆分(递归+DP递推都可以做,注意区别和理解)
|
文章目录
343.整数拆分思路1:递归法(最直观的想法)递归思路普通递归写法注意点:max的嵌套普通递归存在的问题
记忆化搜索+递归写法时间复杂度
递归解法总结
思路2:动态规划(注意递推的理解)确认DP数组含义递推公式初始化遍历顺序DP写法完整版dp[i]求最大值为什么还要再写一遍时间复杂度
总结:递归和DP递推的区别动态规划和递归状态转移方程的进一步理解递归法与递推的区别
343.整数拆分
给定一个正整数 n ,将其拆分为 k 个 正整数 的和( k >= 2 ),并使这些整数的乘积最大化。 返回 你可以获得的最大乘积 。 示例 1: 输入: n = 2 输出: 1 解释: 2 = 1 + 1, 1 × 1 = 1。示例 2: 输入: n = 10 输出: 36 解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。提示: 2 //递归终止条件:输入为1,也就是已经拆到1了,直接返回 if(n==1) return 1; int result=0; for(int i=1;i return dfs(n); } }; 注意点:max的嵌套max()函数在c++标准库中定义的版本只接受两个参数。也就是说max()函数在每次调用时只比较两个值,因此,如果要比较三个或更多的值,需要将max()函数嵌套在一起使用。例如下面: result = max(result,max(i*n-i,i*dfs(n-i));max的三个元素比较的嵌套,嵌套任意两个都可以。无论如何嵌套max()函数,只要确保所有的数值都被比较,就能得到相同的结果。 result = max(i*n-i,max(result,i*dfs(n-i)));//这样写也可以正确运行,也是比较这三个数字 普通递归存在的问题
为优化时间复杂度,我们采用记忆化搜索来防止同一个数字被重复拆分。 记忆化搜索原理是使用一个数组memo,用来保存每个整数的dfs拆分结果。当我们要计算一个数的dfs(n)(也就是这个数字拆分后的最大乘积)时,首先检查memo数组,如果已经计算过,就直接返回,否则计算出结果后保存在memo数组中。 这么做可以防止类似dfs(5)在多个较大整数拆分的时候被重新拆的情况。 如果memo[n]已经有数值了,不用拆分,直接返回当前的记忆数值(历史拆分结果)memo[n]没有数值,才进行拆分的逻辑 class Solution { public: //创建记忆数组,初始化为0 vectormemo; int dfs(int n){ //递归终止条件:已经for结束存在memo里面了 //如果memo[n]已经有数值了,不用拆分,直接返回当前的数值(历史拆分结果) if(memo[n]!=0) return memo[n]; int result=0; for(int i=1;i //memo初始化 memo = vector(n+1,0);//注意memo的重新赋值 return dfs(n); } };进行了记忆化搜索的优化,递归写法就能通过这道题了。
时间复杂度:O(n²)。递归树的深度为n,每一层最多需要做n次操作(在for循环中比较和更新结果),所以时间复杂度为O(n²)。 空间复杂度:O(n)。我们使用了一个大小为n的一维数组memo来存储已经计算过的结果,所以空间复杂度为O(n)。 递归解法总结递归做法更加直观也更好理解,核心就是result = max(result, i*(n-i), i*dfs(n-i)),枚举从1–n的所有i和n-i的乘积结果,找到最大值。(实际上枚举1–n/2即可,i和n-i后半段是重复的) 但是这种做法,dfs(n-i)的拆分里会有大量的重复拆分,例如dfs(5)这个数值,遍历到dfs(9),dfs(8),dfs(7)的时候都会再拆一遍,造成大量时间消耗,会超时。 因此需要靠记忆化搜索进行防止重复拆分的操作,用memo数组存下每一次拆分的最终结果dfs(n)。递归之前检查如果memo数组有这个dfs(n),直接返回memo存的结果。 dfs(n)的含义就是n拆分后得到的因子乘积最大值结果。 思路2:动态规划(注意递推的理解)动态规划的思想,是当前状态全部由之前的状态推出来。也就是说,如果要获得最大乘积,我们需要让i(1 //和递归写法很像,都是取i情况下的最大值 dp[i]=max(dp[i],max(j*(i-j),j*dp[i-j])); } } //结果就是dp[n] return dp[n]; DP写法完整版 class Solution { public: int integerBreak(int n) { //DP数组建立,注意数组本身容量赋值 vectordp(n+1,0); //初始化 dp[2]=1; for(int i=3;i dp[i]=max(dp[i],max(j*(i-j),j*dp[i-j])); } } return dp[n]; } }; dp[i]求最大值为什么还要再写一遍 因为在递推公式推导的过程中,每次计算dp[i],需要取所有dp[i]中的最大值。 和下面引入result的写法是一样的。result完全可以用dp[i]来代替 class Solution { public: int integerBreak(int n) { //DP数组建立,注意数组本身容量赋值 vectordp(n+1,0); //初始化 dp[2]=1; for(int i=3;i result=max(result,max(j*(i-j),j*dp[i-j])); } //最大值存在dp[i]里 dp[i]=result; } return dp[n]; } }; 时间复杂度时间复杂度:O(n²)。因为有两层for循环,每一层最多需要做n次操作(比较和更新dp[i]),所以时间复杂度为O(n²)。 空间复杂度:O(n)。我们使用了一个大小为n的一维数组dp来存储所有状态的结果,所以空间复杂度为O(n)。 总的来说,这两种方法的时间复杂度和空间复杂度都相同,但实际运行效率可能因为具体实现(例如递归的开销、记忆化搜索的查找开销等)和语言特性等因素有所不同。 总结:递归和DP递推的区别本题中,递归解法和DP解法的核心思路是一样的,都是找到一个整数可以拆分为的两个数的最大乘积,这两个数可以是一个具体的整数和一个可能继续拆分的整数。 不同的是,递归解法是从上到下,对每个整数,都尝试所有可能的拆分方式,然后选择最大的乘积;而DP解法是从下到上,对每个整数,根据已经计算出的较小整数的最大乘积,来推导出当前整数的最大乘积。 动态规划和递归动态规划(DP)是一种以空间换时间的算法设计技术,通过存储和重用过去的结果,避免了重复计算,从而提高了算法的效率。DP是一种特殊的递推,通常我们会找到一个或一组状态转移方程,用于描述问题之间的关系,然后从基本情况(初始状态)开始,按照这个(这些)方程递推出所有的状态。 递归是一种算法设计技术,它通过将问题分解为更小的子问题来解决问题,而这些子问题与原问题具有相同的形式。通常,递归需要一个或多个基本情况来停止递归。当递归处理的子问题有重叠时(即在递归过程中多次求解相同的子问题),使用递归可能会导致效率低下。这时就可以使用动态规划或记忆化搜索来改进。 状态转移方程的进一步理解动态规划的状态转移方程,就是在找一个适用于从小到大所有元素的公式,这个公式可以把一个大问题转化为几个小问题的关系。 在整数拆分这个问题中,状态转移方程为:dp[i] = max(j*(i-j), j*dp[i-j]),这个方程表示,对于一个正整数i,我们要么选择将它拆分为j和i-j(不再拆分i-j),要么选择将它拆分为j和以某种方式继续拆分i-j得到的最大乘积。然后我们遍历所有的j(1 |
 用上面的写法来写,小用例可以通过,但是较大的用例会发生超时。
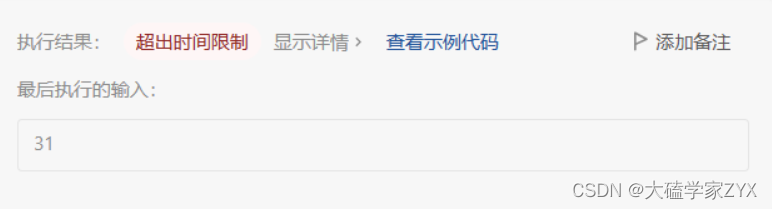
用上面的写法来写,小用例可以通过,但是较大的用例会发生超时。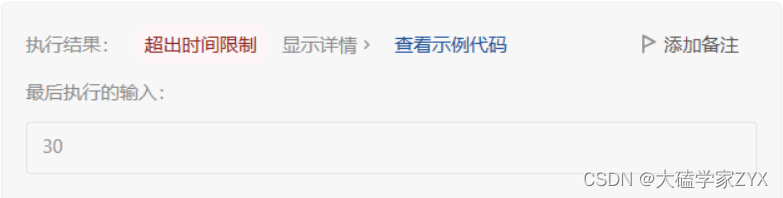 这是因为普通递归的思路,我们会多次计算相同值的最大乘积。例如下图情况:
这是因为普通递归的思路,我们会多次计算相同值的最大乘积。例如下图情况: 即使我们令i
//递归终止条件:输入为1,也就是已经拆到1了,直接返回
if(n==1) return 1;
int result=0;
for(int i=1;i
return dfs(n);
}
};
即使我们令i
//递归终止条件:输入为1,也就是已经拆到1了,直接返回
if(n==1) return 1;
int result=0;
for(int i=1;i
return dfs(n);
}
};

【本文地址】