| python爬虫:requests+pyquery实现知乎热门话题爬取 | 您所在的位置:网站首页 › 知乎的网站名称怎么修改 › python爬虫:requests+pyquery实现知乎热门话题爬取 |
python爬虫:requests+pyquery实现知乎热门话题爬取
|
文章目录
前言
1. requests库的基本使用2. pyquery库的基本使用3. 爬取知乎热门话题
前言
有些东西想忘都忘不了,而有些却转背就忘了!这段时间忙于找工作和学习mysql,把爬虫搁置一边,今天翻开书发现忘得差不多了,于是想到爬爬知乎热门话题,以此来温习爬虫的基本知识点。 1. requests库的基本使用1.1 网页获取get和post 前提安装好了requests库,get请求和post请求 #get请求 import requests r = requests.get('url') print(r.text) #post请求 import requests data = {'name':'anxiao', 'age':'23'} r = requests.post('http://httpbin.org/post', data=data) print(r.text)1.2 params参数构造url,json()方法将返回结果为json格式的文本转为字典 import requests data = {'name':'germy','age':22} r = requests.get('http://httpbin.org/get',params=data) print(r.text) print(r.url) print(type(r.text)) print(r.json()) print(type(r.json()))1.3 添加headers和cookies import requests headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36', 'cookie':'''_zap=f298cc22-ed45-47a7-80c5-0c1f60f3207e; d_c0="ALCjXn2C-A-PTj7MOThWA-1TyjHY7_qdZkc=|1567155243"; _ga=GA1.2.1140563663.1583908405; _xsrf=2e8xkoYwNLLG0bt9CMArPU7UMvI8WifQ; z_c0=Mi4xR1ZYa0RRQUFBQUFBc0tOZWZZTDREeGNBQUFCaEFsVk54UUYzWHdEZEtWcmk3dk5hdmJRd1VKMy16QkJIb0FkTjd3|1586082757|eead4bcc08f01e07ddcdd636c3d4c26a3e5ffd8d; q_c1=805e9a6adc9846dc82db227b9c60baa5|1586083219000|1586083219000; __guid=74140564.3769393844892784600.1595129352315.7222; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1595129354; _gid=GA1.2.512696011.1595129354; SESSIONID=3M4KH7g828eAbnCQSLCj70mOeqT9BvhOqnBpbyWwFgY; JOID=W1sSA02TelvBu4dBBZqPRAINum8aqjNojPy6IjquSDqH3-YIUJXHSZe-iUIEtj16n1FxY7wUR01Jm0KKd28XW9o=; osd=V1EXAUqfcF7DvItLAJiISAgIuGgWoDZqi_CwJzipRDCC3eEEWpDFTpu0jEADujd_nVZ9abkWQEFDnkCNe2USWd0=; tst=h; tshl=; monitor_count=9; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1595130975; KLBRSID=5430ad6ccb1a51f38ac194049bce5dfe|1595131061|1595129347referer: https://www.zhihu.com/people/gu-ying-13-66''' } r = requests.get('url',headers=headers)1.4 处理二进制数据 r = requests.get('https://github.com/favicon.ico') #print(r.text) #print(r.content) with open('github.ico','wb') as f: f.write(r.content)1.5 查看响应数据 import requests r = requests.get('http://www.jianshu.com') print(r.status_code)#返回状态吗 print(r.headers)#请求头 print(r.cookies)#cookies print(r.url)#查看url1.6 会话维持Session #无法获取网页,未建立会话 import requests requests.get('http://httpbin.org/cookies/set/number/123456789') r = requests.get('http://httpbin.org/cookies') print(r.text) #可以获取网页,已建立会话 import requests s = requests.Session() s.get('http://httpbin.org/cookies/set/number/123456789') r = s.get('http://httpbin.org/cookies') print(r.text) 2. pyquery库的基本使用pyquery库是python的一个网页解析库,它的强大之处在于它的css选择器,基pyquery的css选择器来分析和解析网页具有很高的效率。 2.1 初始化 pyquery的初始化有三种,分别为:字符串初始化,url初始化和文件初始化 #字符串初始化 #html = 'html文本内容' html =''' first item sceond item third item fouth item fifth item ''' from pyquery import PyQuery as pq doc = pq(html) #url初始化 from pyquery import PyQuery as pq doc = pq(url='https://cuiqingcai.com') #文件初始化 from pyquery import PyQuery as pq doc = pq('fielname'='文件名')2.2 查找节点 子节点 find():查找子节点 children():查找子孙节点父节点 parent():获取直接父节点 parents():获取祖先节点兄弟节点 siblings():获取兄弟节点有时候用pyquery选择的可能是多个节点,但打印出来的往往是第一个节点,这时候就需要用到items()方法了,使用items()方法就会得到一个生成器,再进行遍历就可以得到每个节点了,可以如下 html = ''' first item sceond item third item fouth item fifth item ''' from pyquery import PyQuery as pq doc = pq(html) li = doc('li').items() print(type(li)) for i in li: print(li)2.3 获取信息 获取属性 attr():获取节点的属性 获取文本 text():获取节点的文本信息 3. 爬取知乎热门话题3.1 爬取步骤 获取网页源码分析源码,提取需要的信息保存信息3.2 获取网页源码 在爬虫中第一步往往是获取爬取网页的源码,个人认为这是最重要也是最难的一步,因为它涉及的知识点比较多,例如参数的变化规律的寻找,登录验证,绕反爬虫等等。现在要爬的是知乎的入门话题,url为:https://www.zhihu.com/hot,现在利用requests库来获取热门话题的网页源码,如下 import requests from pyquery import PyQuery as pq def get_page(): #获取网页源码 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36', 'cookie':'''_zap=f298cc22-ed45-47a7-80c5-0c1f60f3207e; d_c0="ALCjXn2C-A-PTj7MOThWA-1TyjHY7_qdZkc=|1567155243"; _ga=GA1.2.1140563663.1583908405; _xsrf=2e8xkoYwNLLG0bt9CMArPU7UMvI8WifQ; z_c0=Mi4xR1ZYa0RRQUFBQUFBc0tOZWZZTDREeGNBQUFCaEFsVk54UUYzWHdEZEtWcmk3dk5hdmJRd1VKMy16QkJIb0FkTjd3|1586082757|eead4bcc08f01e07ddcdd636c3d4c26a3e5ffd8d; q_c1=805e9a6adc9846dc82db227b9c60baa5|1586083219000|1586083219000; __guid=74140564.3769393844892784600.1595129352315.7222; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1595129354; _gid=GA1.2.512696011.1595129354; SESSIONID=3M4KH7g828eAbnCQSLCj70mOeqT9BvhOqnBpbyWwFgY; JOID=W1sSA02TelvBu4dBBZqPRAINum8aqjNojPy6IjquSDqH3-YIUJXHSZe-iUIEtj16n1FxY7wUR01Jm0KKd28XW9o=; osd=V1EXAUqfcF7DvItLAJiISAgIuGgWoDZqi_CwJzipRDCC3eEEWpDFTpu0jEADujd_nVZ9abkWQEFDnkCNe2USWd0=; tst=h; tshl=; monitor_count=9; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1595130975; KLBRSID=5430ad6ccb1a51f38ac194049bce5dfe|1595131061|1595129347referer: https://www.zhihu.com/people/gu-ying-13-66''' } html = requests.get('https://www.zhihu.com/hot', headers=headers) if html.status_code == 200: print("网页获取成功...") return html.text else: print("网页获取失败...")值得一提的是这里必须添加User-Agent,它在这里的作用是伪造一个请求头里的User-Aagent,好让服务器响应(来自百度:User Agent中文名为用户代理,是Http协议中的一部分,属于头域的组成部分,User Agent也简称UA。它是一个特殊字符串头,是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。通过这个标识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计。)。 其次,这里要添加的还有cookie,它的作用是保持登录状态;有了User-Agent和cookie,这样就能获取到包含有热门话题信息的源码了,不然是无法获取有效源码的。 获取方式:登录知乎,切换到热榜下,按F12,然后如下,最后继续复制粘贴就行了 3.3 提取需要的信息 要想提取出需要的信息,就得找到它在源码里的位置。通过上面获取到的源码信息,大概能知道热门话题的信息应该与HotList这样的节点有关,接下来去浏览器F12准确定位下;可以发现我们需要的信息在节点为h2,属性为HotItem-title里 现在调用函数parse_html(),遍历items,结果如下 这里主要是利用text()获取信息,以及进行一下输出格式调整,代码如下 def write_to_file(items): #将信息保存到文件中 hotlist = [] for item in items: hotlist.append(item.text()) rank_hotlist = enumerate(hotlist) with open('hotlist.txt', 'w') as f: for index, values in rank_hotlist: f.write(str(index+1) + ' ') f.write(values + '\n') print("信息已保存...")注意write_to_file()函数要传入parse_html()函数返回的items,最终结果如下 |
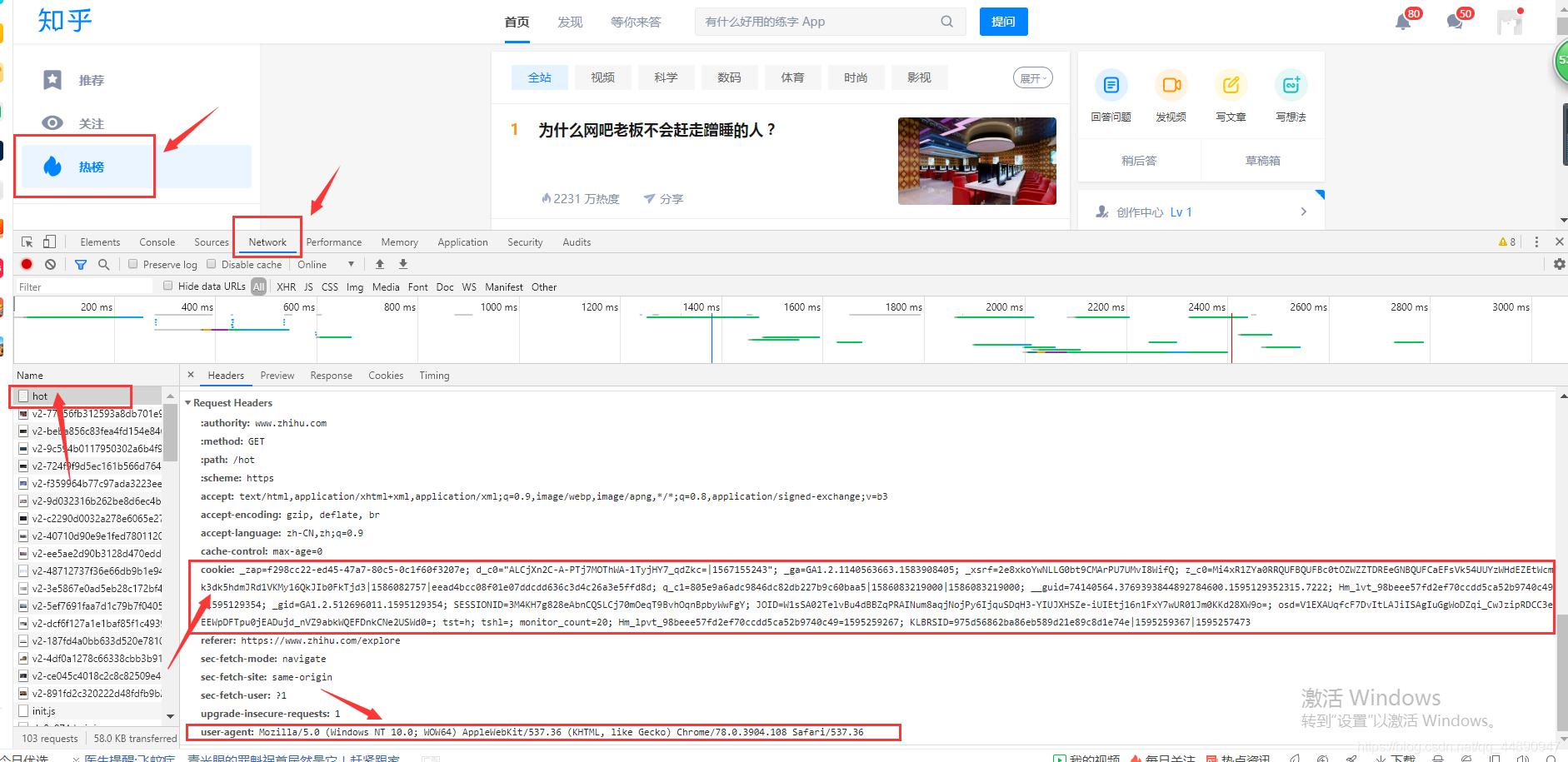 调用get_page()函数后结果如下
调用get_page()函数后结果如下 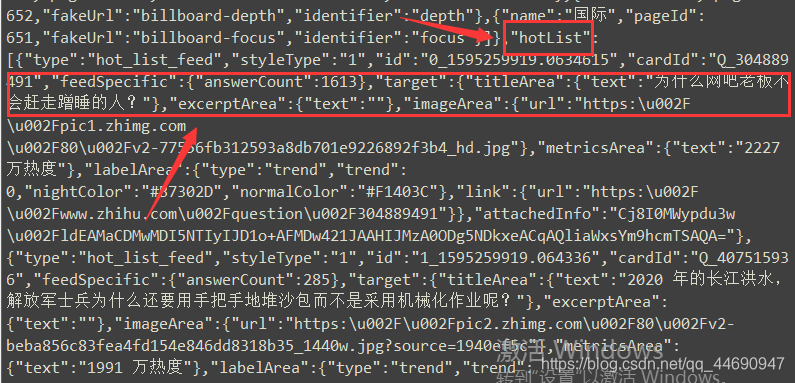
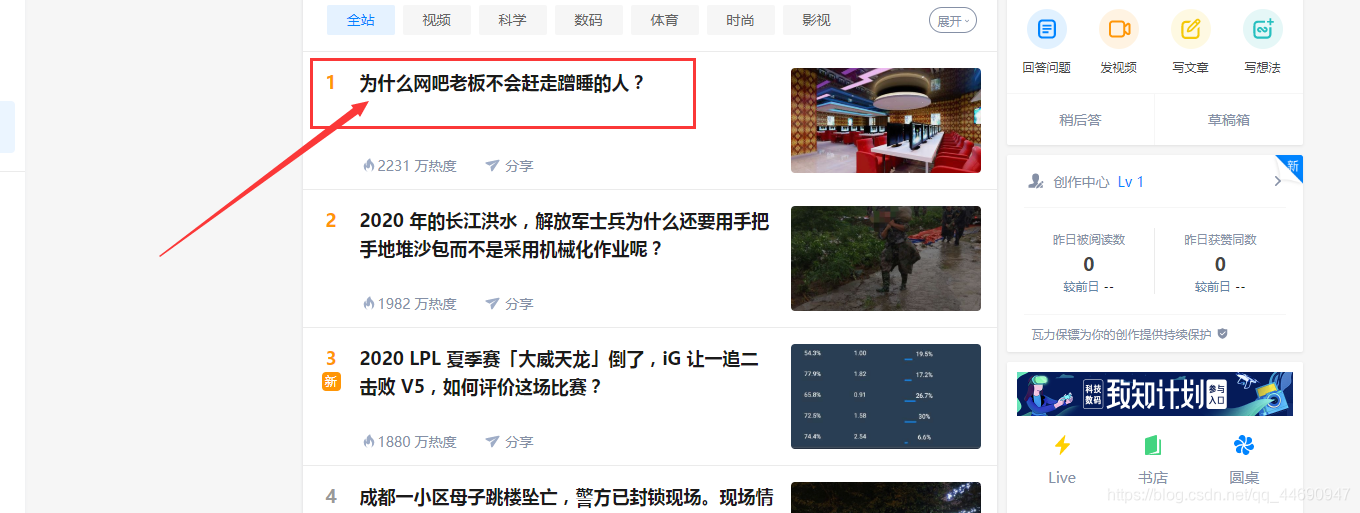 可以看到源码里的信息和在浏览器里看到的是一样的,说明成功获取到了要爬取得源码。
可以看到源码里的信息和在浏览器里看到的是一样的,说明成功获取到了要爬取得源码。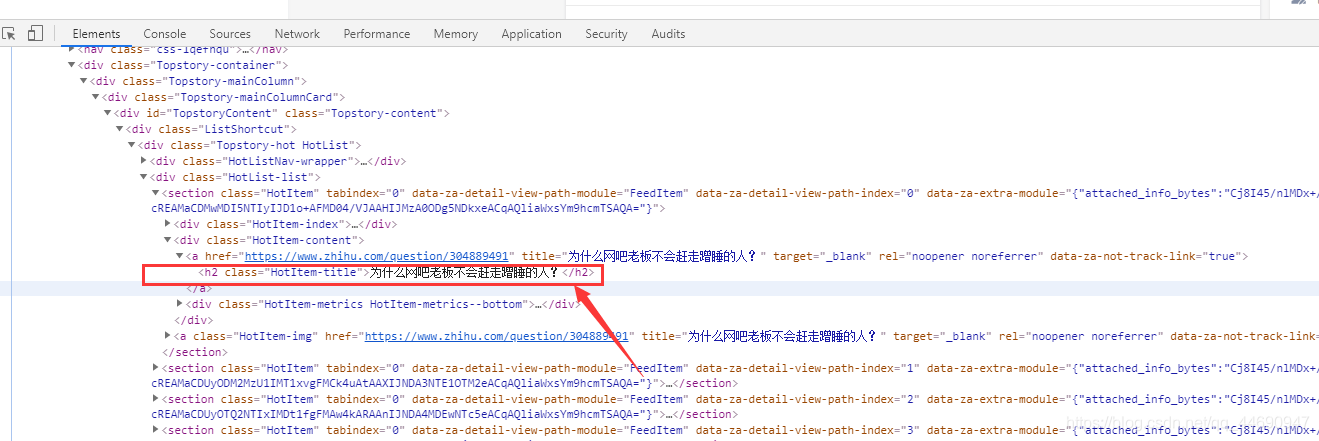 接下来用pyquery直接提前就是了,代码如下
接下来用pyquery直接提前就是了,代码如下 3.4 处理数据并保存到文件
3.4 处理数据并保存到文件 3.5 源码如下
3.5 源码如下【本文地址】