| GPU运算能力对(2022.4.5更新) | 您所在的位置:网站首页 › 特斯拉显卡价格一览表 › GPU运算能力对(2022.4.5更新) |
GPU运算能力对(2022.4.5更新)
|
0. 简介
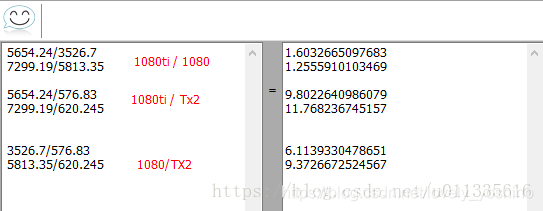
实验室最近出了一款芯片,想进行指标的对比,现在ai芯片加速器我记得峰值运算能力effiency已经达到了Tops(一般也就几或者十几,effiency一般分为ops/w,ops/mm^2,ops/s等等),于是想看看GPU的运算能力,进行相应参照。 大多数网站都会贴这一张图,其实也没有错,就是不够细致,我们更想知道它的具体ops登记,而不是宽泛的level级别的计算能力数字。nvidia的显卡越来越强,CUDA运算核心越来越多,甚至也开始了他自家的深度学习学院DLI(赚钱),它强大的并行性,使得现在显卡GTX系列,RTX3090,丽台,Tesla系列,P40系列,K4200系列以及TITAN X/V,TITAN XP等等产品一个个成为热点,狂赚一波。 1. CUDA GPUs最新信息见:https://developer.nvidia.com/cuda-gpus 1) CUDA-Enabled Tesla Products Tesla Workstation Products GPUCompute CapabilityTesla K803.7Tesla K403.5Tesla K203.5Tesla C20752.0Tesla C2050/C20702.0 Tesla Data Center Products GPUCompute CapabilityNVIDIA A1008.0NVIDIA A408.6NVIDIA A308.0NVIDIA A108.6NVIDIA A168.6NVIDIA A28.6NVIDIA T47.5NVIDIA V1007.0Tesla P1006.0Tesla P406.1Tesla P4 6.1Tesla M405.2Tesla M405.2Tesla K803.7Tesla K403.5Tesla K203.5Tesla K103.0 2) CUDA-Enabled Quadro Products Quadro Desktop Products GPUCompute CapabilityRTX A60008.6RTX A50008.6RTX A40008.6T10007.5T6007.5T4007.5Quadro RTX 80007.5Quadro RTX 60007.5Quadro RTX 50007.5Quadro RTX 40007.5Quadro GV1007.0Quadro GP1006.0Quadro P60006.1Quadro P50006.1Quadro M6000 24GB5.2Quadro M60005.2Quadro K60003.5Quadro M50005.2Quadro K52003.5Quadro K50003.0Quadro M40005.2Quadro K42003.0Quadro K40003.0Quadro M20005.2Quadro K22005.0Quadro K20003.0Quadro K2000D3.0Quadro K12005.0Quadro K6205.0Quadro K6003.0Quadro K4203.0Quadro 4103.0Quadro Plex 70002.0 Quadro Mobile Products GPUCompute CapabilityRTX A50008.6RTX A40008.6RTX A30008.6RTX A20008.6RTX 50007.5RTX 40007.5RTX 30007.5T20007.5T12007.5T10007.5T6007.5T5007.5P6206.1P5206.1Quadro P52006.1Quadro P42006.1Quadro P32006.1Quadro P50006.1Quadro P40006.1Quadro P30006.1Quadro P20006.1Quadro P10006.1Quadro P6006.1Quadro P5006.1Quadro M5500M5.2Quadro M22005.2Quadro M12005.0Quadro M6205.2Quadro M5205.0Quadro K6000M3.0Quadro M5500M5.0Quadro K5200M3.0Quadro K5100M3.0Quadro M5000M5.0Quadro K500M3.0Quadro K4200M3.0Quadro K4100M3.0Quadro M4000M5.0Quadro K3100M3.0Quadro M3000M5.0Quadro K2200M5.0Quadro K2100M3.0Quadro M2000M5.0Quadro K1100M3.0Quadro M1000M5.0Quadro K620M5.0Quadro K610M3.5Quadro M600M5.0Quadro K510M3.5Quadro M500M5.0 3) CUDA-Enabled NVS Products Desktop Products GPUCompute CapabilityNVIDIA NVS 8105.0NVIDIA NVS 5103.0NVIDIA NVS 3152.1NVIDIA NVS 3102.1 Mobile Products GPUCompute CapabilityNVS 5400M2.1NVS 5200M2.1NVS 4200M2.1 4) CUDA-Enabled GeForce Products GeForce Desktop Products Mobile Products GPUCompute CapabilityGeforce RTX 3060 Ti8.6Geforce RTX 30608.6GeForce RTX 30908.6GeForce RTX 30808.6GeForce RTX 30708.6GeForce GTX 1650 Ti7.5NVIDIA TITAN RTX7.5GeForce GTX 2080TI7.5GeForce GTX 20807.5GeForce GTX 20707.5GeForce GTX 20607.5NVIDIA TITAN Xp6.1NVIDIA TITAN X6.1GeForce GTX 1080TI6.1GeForce GTX 10806.1GeForce GTX 10706.1GeForce GTX 10606.1GeForce GTX TITAN X5.2GeForce GTX TITAN Z3.5GeForce GTX TITAN Black3.5GeForce GTX TITAN3.5GeForce GTX 980 Ti5.2GeForce GTX 9805.2GeForce GTX 9705.2GeForce GTX 9605.2GeForce GTX 9505.2GeForce GTX 780 Ti3.5GeForce GTX 7803.5GeForce GTX 7703.0GeForce GTX 7603.0GeForce GTX 750 Ti5.0GeForce GTX 7505.0GeForce GTX 6903.0GeForce GTX 6803.0GeForce GTX 6703.0GeForce GTX 660 Ti3.0GeForce GTX 6603.0GeForce GTX 650 Ti BOOST3.0GeForce GTX 650 Ti3.0GeForce GTX 6503.0GeForce GTX 560 Ti2.1GeForce GTX 550 Ti2.1GeForce GTX 4602.1GeForce GTS 4502.1GeForce GTS 450*2.1GeForce GTX 5902.0GeForce GTX 5802.0GeForce GTX 5702.0GeForce GTX 4802.0GeForce GTX 4702.0GeForce GTX 4652.0GeForce GT 7403.0GeForce GT 7303.5GeForce GT 730 DDR3,128bit2.1GeForce GT 7203.5GeForce GT 705*3.5GeForce GT 640 (GDDR5)3.5GeForce GT 640 (GDDR3)2.1GeForce GT 6302.1GeForce GT 6202.1GeForce GT 6102.1GeForce GT 5202.1GeForce GT 4402.1GeForce GT 440*2.1GeForce GT 4302.1GeForce GT 430*2.1 5) CUDA-Enabled TEGRA /Jetson Products GeForce Notebook Products GPUCompute CapabilityGeForce RTX 30808.6GeForce RTX 30708.6GeForce RTX 30608.6GeForce RTX 3050 Ti8.6GeForce RTX 30508.6GeForce GTX 20807.5GeForce GTX 20707.5GeForce GTX 20607.5GeForce GTX 10806.1GeForce GTX 10706.1GeForce GTX 10606.1GeForce GTX 9805.2GeForce GTX 980M5.2GeForce GTX 970M5.2GeForce GTX 965M5.2GeForce GTX 960M5.0GeForce GTX 950M5.0GeForce 940M5.0GeForce 930M5.0GeForce 920M3.5GeForce 910M5.2GeForce GTX 880M3.0GeForce GTX 870M3.0GeForce GTX 860M3.0/5.0(**)GeForce GTX 850M5.0GeForce 840M5.0GeForce 830M5.0GeForce 820M2.1GeForce 800M2.1GeForce GTX 780M3.0GeForce GTX 770M3.0GeForce GTX 765M3.0GeForce GTX 760M3.0GeForce GTX 680MX3.0GeForce GTX 680M3.0GeForce GTX 675MX3.0GeForce GTX 675M2.1GeForce GTX 670MX3.0GeForce GTX 670M2.1GeForce GTX 660M3.0GeForce GT 750M3.0GeForce GT 650M3.0GeForce GT 745M3.0GeForce GT 645M3.0GeForce GT 740M3.0GeForce GT 730M3.0GeForce GT 640M3.0GeForce GT 640M LE3.0GeForce GT 735M3.0GeForce GT 635M2.1GeForce GT 730M3.0GeForce GT 630M2.1GeForce GT 625M2.1GeForce GT 720M2.1GeForce GT 620M2.1GeForce 710M2.1GeForce 705M2.1GeForce 610M2.1GeForce GTX 580M2.1GeForce GTX 570M2.1GeForce GTX 560M2.1GeForce GT 555M2.1GeForce GT 550M2.1GeForce GT 540M2.1GeForce GT 525M2.1GeForce GT 520MX2.1GeForce GT 520M2.1GeForce GTX 485M2.1GeForce GTX 470M2.1GeForce GTX 460M2.1GeForce GT 445M2.1GeForce GT 435M2.1GeForce GT 420M2.1GeForce GT 415M2.1GeForce GTX 480M2.0GeForce 710M2.1GeForce 410M2.1 6) Tegra Mobile & Jetson Products Tegra Mobile & Jetson Products GeForce Notebook Products GPUCompute CapabilityJetson AGX Xavier7.2Jetson Nano5.3Jetson TX26.2Jetson TX15.3Jetson TK13.2Tegra X15.3Tegra K13.2Notes (*) 仅OEM产品 (**) GeForce GTX860和GTX870有两个版本,具体取决于SKU,请与OEM联系以确定系统中的版本 2. GPU算力计算以及选择 计算能力换算理论峰值 = GPU芯片数量GPU Boost主频核心数量*单个时钟周期内能处理的浮点计算次数 只不过在GPU里单精度和双精度的浮点计算能力需要分开计算,以最新的Tesla P100为例: 双精度理论峰值 = FP64 Cores * GPU Boost Clock * 2 = 1792 *1.48GHz*2 = 5.3 TFlops 单精度理论峰值 = FP32 cores * GPU Boost Clock * 2 = 3584 * 1.58GHz * 2 = 10.6 TFlop TFLOPS但是现在衡量计算速度的标准是TFLOPS**(每秒万亿次浮点运算),注意GPU它是浮点运算。 重点就是关注它的flops是怎么计算的。 这里先参考一下某博主写的粗浅见解: https://blog.csdn.net/wesley_2013/article/details/11910117 GPU设备的单精度计算能力的理论峰值计算公式:单精度计算能力的峰值 = 单核单周期计算次数 × 处理核个数 × 主频 例如: 以GTX680为例, 单核一个时钟周期单精度计算次数为两次(一般都是2),处理核个数 为1536, 主频为1006MHZ,那他的计算能力的峰值P 为 P = 2 × 1536 × 1006MHZ = 3.09TFLOPS 这里1MHZ = 1000000HZ, 1T为1兆,也就是说,GTX680每秒可以进行超过3兆次的单精度运算。 同样,双精度的处理核为64个,不难算出,GTX680的双精度运算能力为0.13TFLOPS。 同理 GPU设备的数据通信时间的计算公式:通信时间 = 通信量 ÷ 通信速度 例如,单个处理核的输入数据以4个4byte为例,输出为1个4byte,GTX680所有处理核100%利用的情况下,通信量为5× 4 × 1536 byte,GTX680的通信速度为192…2GB/S,所以它的通信时间为 ---------- 5× 4 × 1536 byte ÷ 192.2GB/S = 1.49e-7 s 如果这4个4byte的数据进行10次运算的话,以GTX680为例,他的主频为1006MHZ,也就是他每1e-9s为一个时钟周期,每个周期可进行两次单精度计算,也就是5个时钟周期即5e-9s可完成计算,为通信时间的几十分之一,故可忽略不计。所以,从内存访问看计算能力: 单精度计算能力 = 单核单精度符点计算次数 × 处理核个数 ÷ ( 通信时间 + 计算时间) 注:此处计算时间忽略不计 即 10 × 1536 ÷ 1.49e-7s = 103GFLOPS 即为普通PC10倍的计算速度。 SP总数=TPC&GPC数量每个TPC中SM数量每个SM中的SP数量;TPC和GPC是介于整个GPU和流处理器簇之间的硬件单元,用于执行CUDA计算。特斯拉架构硬件将SM组合成TPC(纹理处理集群),其中,TPC包含有纹理硬件支持(特别包含一个纹理缓存)和2个或3个SM,后面会有详细描述。费米架构硬件组则将SM组合为GPC(图形处理器集群),其中,每个GPU包含有一个光栅单元和4个SM。 单精度浮点处理能力=SP总数SP运行频率每条执行流水线每周期能执行的单精度浮点操作数; 该公式实质上是3部分相乘得到的,分别为计算单元数量、计算单元频率和指令吞吐量。 前两者很好理解,指令吞吐量这里是按照FMA(融合乘法和增加)算的,也就是每个SP,每周期可以有一条FMA指令的吞吐量,并且同时FMA因为同时计算了乘加,所以是两条浮点计算指令。以及需要说明的是,并不是所有的单精度浮点计算都有这个峰值吞吐量,只有全部为FMA的情况,并且没有其他访存等方面的限制的情况下,并且在不考虑调度效率的情况下,才是这个峰值吞吐量。如果是其他吞吐量低的计算指令,自然达不到这个理论峰值。 双精度浮点处理能力=双精度计算单元总数SP运行频率每个双精度计算单元每周期能进行的双精度浮点操作数。目前对于N卡来说,双精度浮点计算的单元是独立于单精度单元之外的,每个SP都有单精度的浮点计算单元,但并不是每个SP都有双精度的浮点单元。对于有双精度单元的SP而言,最大双精度指令吞吐量一样是在实现FMA的时候的每周期2条(指每周期一条双精度的FMA指令的吞吐量,FMA算作两条浮点操作)。 而具备双精度单元的SP数量(或者可用数量)与GPU架构以及产品线定位有关,具体为: 计算能力为1.3的GT200核心,第一次硬件支持双精度浮点计算,双精度峰值为单精度峰值的1/8,该核心目前已经基本退出使用。 GF100/GF110核心,有一半的SP具备双精度浮点单元,但是在geforce产品线中屏蔽了大部分的双精度单元而仅在tesla产品线中全部打开。代表产品有:tesla C2050,2075等,其双精度浮点峰值为单精度浮点峰值的一半; geforce GTX 480,580,其双精度浮点峰值为单精度浮点峰值的大约1/8左右。 其他计算能力为2.1的Fermi核心,原生设计中双精度单元数量较少,双精度计算峰值为单精度的1/12。 kepler GK110核心,原生的双精度浮点峰值为单精度的1/3。而tesla系列的K20,K20X,K40他们都具备完整的双精度浮点峰值;geforce系列的geforce TITAN,此卡较为特殊,和tesla系列一样具备完整的双精度浮点峰值,geforce GTX780/780Ti,双精度浮点峰值受到屏蔽,具体情况不详,估计为单精度峰值的1/10左右。 其他计算能力为3.0的kepler核心,原生具备较少的双精度计算单元,双精度峰值为单精度峰值的1/24。 计算能力3.5的GK208核心,该卡的双精度效能不明,但是考虑到该核心定位于入门级别,大规模双精度计算无需考虑使用。 所以不同核心的N卡的双精度计算能力有显著区别,不过目前基本上除了geforce TITAN以外,其他所有geforce卡都不具备良好的双精度浮点的吞吐量,而本代的tesla K20/K20X/K40以及上一代的fermi核心的tesla卡是较好的选择。 GPU信息对比 1080TI ~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ export CUDA_VISIBLE_DEVICES=0 ~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ ./batchCUBLAS -m1024 -n1024 -k1024 batchCUBLAS Starting... GPU Device 0: "GeForce GTX 1080 Ti" with compute capability 6.1 ==== Running single kernels ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00037980 sec GFLOPS=5654.24 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00894690 sec GFLOPS=240.026 @@@@ dgemm test OK ==== Running N=10 without streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x00000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00294209 sec GFLOPS=7299.19 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.07993412 sec GFLOPS=268.657 @@@@ dgemm test OK ==== Running N=10 with streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x40000000, 2) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00224590 sec GFLOPS=9561.78 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.05540895 sec GFLOPS=387.57 @@@@ dgemm test OK ==== Running N=10 batched ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x3f800000, 1) beta= (0xbf800000, -1) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00197387 sec GFLOPS=10879.6 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.05372214 sec GFLOPS=399.739 @@@@ dgemm test OK Test Summary 0 error(s) 1080 liu@iridescent:~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ export CUDA_VISIBLE_DEVICES=1 liu@iridescent:~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ ./batchCUBLAS -m1024 -n1024 -k1024 batchCUBLAS Starting... GPU Device 0: "GeForce GTX 1080" with compute capability 6.1 ==== Running single kernels ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00060892 sec GFLOPS=3526.7 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00993085 sec GFLOPS=216.244 @@@@ dgemm test OK ==== Running N=10 without streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x00000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00369406 sec GFLOPS=5813.35 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.09741306 sec GFLOPS=220.451 @@@@ dgemm test OK ==== Running N=10 with streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x40000000, 2) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00317717 sec GFLOPS=6759.12 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.07991505 sec GFLOPS=268.721 @@@@ dgemm test OK ==== Running N=10 batched ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x3f800000, 1) beta= (0xbf800000, -1) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00302100 sec GFLOPS=7108.51 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.07566714 sec GFLOPS=283.807 @@@@ dgemm test OK Test Summary 0 error(s) Jetson $ ./batchCUBLAS -m1024 -n1024 -k1024 batchCUBLAS Starting... GPU Device 0: "NVIDIA Tegra X2" with compute capability 6.2 ==== Running single kernels ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00372291 sec GFLOPS=576.83 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.10940003 sec GFLOPS=19.6296 @@@@ dgemm test OK ==== Running N=10 without streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x00000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.03462315 sec GFLOPS=620.245 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 1.09212208 sec GFLOPS=19.6634 @@@@ dgemm test OK ==== Running N=10 with streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x40000000, 2) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.03504515 sec GFLOPS=612.776 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 1.09177494 sec GFLOPS=19.6697 @@@@ dgemm test OK ==== Running N=10 batched ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x3f800000, 1) beta= (0xbf800000, -1) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.03766394 sec GFLOPS=570.17 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 1.09389901 sec GFLOPS=19.6315 @@@@ dgemm test OK Test Summary 0 error(s) 对比 1080ti 1080 Jetson Tx2 GFLOPS=5654.24 GFLOPS=3526.7 GFLOPS=576.83 GFLOPS=7299.19 GFLOPS=5813.35 GFLOPS=620.245
1、CUDA compute capability,这是英伟达公司对显卡计算能力的一个衡量指标; 2、FLOPS 每秒浮点运算次数,TFLOPS表示每秒万亿(10^12)次浮点计算; 3、另外,显存大小也决定了实验中能够使用的样本数量和模型复杂度。 当然了,网上也有很多贴吧或者论坛,视频,各种评测或者天梯图,讨论各种显卡的优劣,例如:RTX3090,RTX3080以及GTX2080ti的分析等,大家可以自行斟酌。 3.参考链接https://blog.csdn.net/p312011150/article/details/83989674 https://www.expreview.com/52443-3.html https://www.expreview.com/67453.html http://tieba.baidu.com/p/5388310468 http://k.sina.com.cn/article_2934331057_aee656b1001004rc9.html?cre=oldpagepc&mod=g&loc=15&r=0&doct=0&rfunc=72&tj=none https://bbs.csdn.net/topics/392311745 https://baijiahao.baidu.com/s?id=1597974095090413567&wfr=spider&for=pc https://cudazone.nvidia.cn/forum/forum.php?mod=viewthread&tid=7722&extra=page%253D1 https://blog.csdn.net/ZIV555/article/details/51753985 讲的比较详细的是下面这一篇,里面有一些我也不知道怎么就输出的信息,可能是某种软件吧: https://blog.csdn.net/enjoyyl/article/details/81529779#1080TI_33 |
 科学计算显卡的两个主要性能指标:
科学计算显卡的两个主要性能指标:【本文地址】