| 案例四 ajax动态加载页面数据爬虫 | 您所在的位置:网站首页 › 爬虫淘宝数据 › 案例四 ajax动态加载页面数据爬虫 |
案例四 ajax动态加载页面数据爬虫
|
需求:
爬取https://spa3.scrape.center/电影名称,电影分类,上映时间和评分 直接在浏览器请求https://spa3.scrape.center/,并查询网页源码,发现数据并不在页面内。 只需要构造一般常规的请求头,通过requests发送常规的get请求即可获取到数据,最后将响应对象解析为json,并转换为python dict类型处理即可。 合理请求头 headers = { 'Accept': 'application/json, text/plain, */*', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive', 'Pragma': 'no-cache', 'Referer': 'https://spa3.scrape.center/', 'Sec-Fetch-Dest': 'empty', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Site': 'same-origin', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36', 'sec-ch-ua': '"Google Chrome";v="111", "Not(A:Brand";v="8", "Chromium";v="111"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', } |
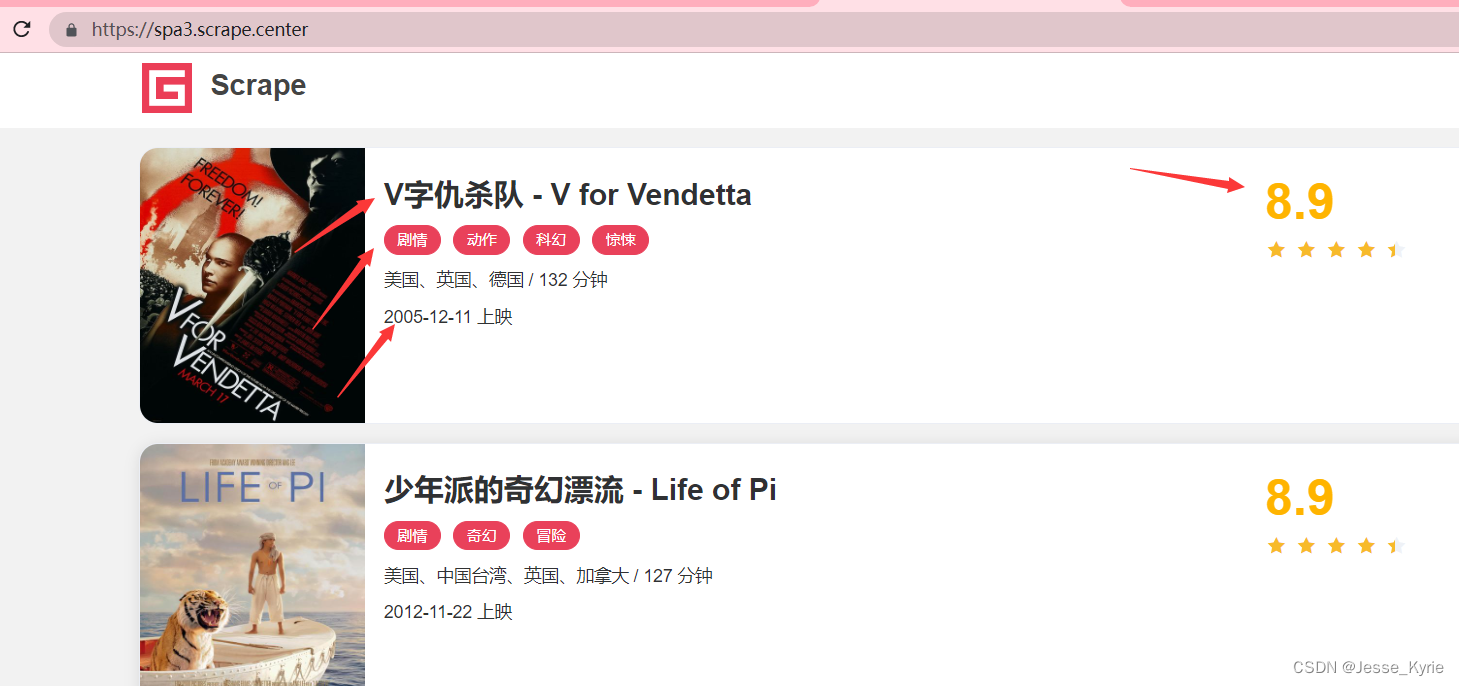
 我由此推测数据为异步接口加载,最后渲染到页面内。则需要通过chrome浏览器抓包分析,定位数据接口。
我由此推测数据为异步接口加载,最后渲染到页面内。则需要通过chrome浏览器抓包分析,定位数据接口。 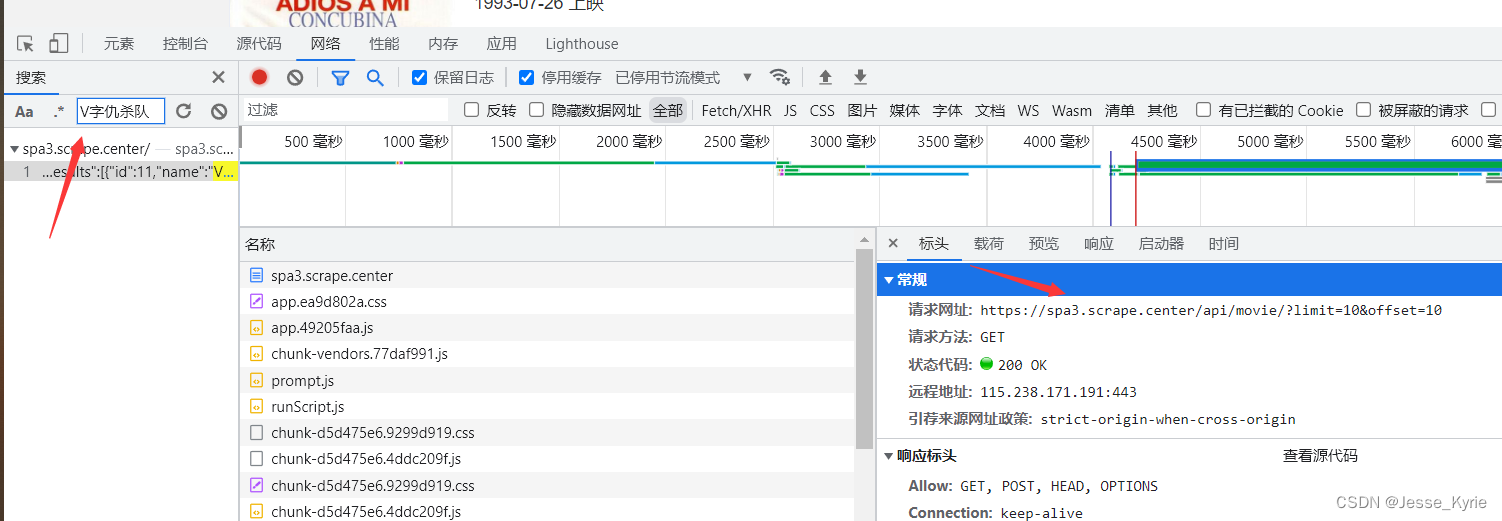 数据接口为https://spa3.scrape.center/api/movie/?limit=10&offset=10 GET接口,无特定防爬。只需要常规请求即可获得数据。
数据接口为https://spa3.scrape.center/api/movie/?limit=10&offset=10 GET接口,无特定防爬。只需要常规请求即可获得数据。【本文地址】
公司简介
联系我们