| selenium 反爬虫之跳过淘宝滑块验证(2020/8) | 您所在的位置:网站首页 › 淘宝导出数据用什么系统打开 › selenium 反爬虫之跳过淘宝滑块验证(2020/8) |
selenium 反爬虫之跳过淘宝滑块验证(2020/8)
|
在处理问题的之前,给大家个第一个锦囊!
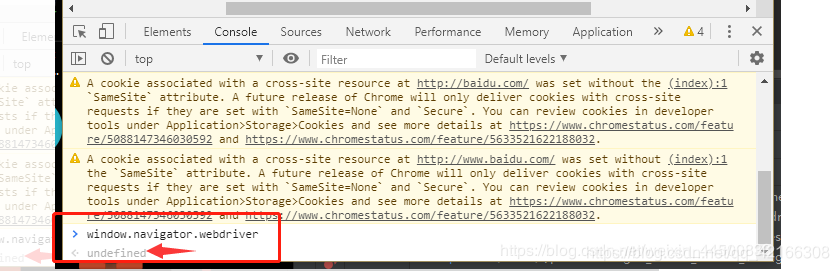
你需要将chorme更新到最新版版本84,下载对应的chorme驱动 链接:http://chromedriver.storage.googleapis.com/index.html 注意 划重点!!一定要做这一步,因为我用的83的chorme他是不行滴,~~~~~~~ 问题1.一周前我的滑块验证代码还是可以OK的,完全没问题!附代码 low一眼 url = "https://login.taobao.com/member/login.jhtml" browser.get(url) browser.maximize_window() # 最大化 # 填写用户名密码 user = '*****' password = '*******' time.sleep(8) iframe = browser.find_element_by_xpath('//div[@class="bokmXvaDlH"]//iframe') print(iframe) browser.switch_to.frame(iframe) browser.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys(id) browser.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys(password) time.sleep(2) # 获取滑块的大小 span_background = browser.find_element_by_xpath('//*[@id="nc_1__scale_text"]/span') span_background_size = span_background.size print(span_background_size) # 获取滑块的位置 button = browser.find_element_by_xpath('//*[@id="nc_1_n1z"]') button_location = button.location print(button_location) # 拖动操作:drag_and_drop_by_offset # 将滑块的位置由初始位置,右移一个滑动条长度(即为x坐标在滑块位置基础上,加上滑动条的长度,y坐标保持滑块的坐标位置) x_location = span_background_size["width"] y_location = button_location["y"] print(x_location, y_location) action = ActionChains(browser) source = browser.find_element_by_xpath('//*[@id="nc_1_n1z"]') action.click_and_hold(source).perform() action.move_by_offset(300, 0) action.release().perform() time.sleep(1) # 登录 browser.find_element_by_xpath('//*[@id="login-form"]/div[4]/button').click() print('登录成功\n')完全可以会很好的进入淘宝,游刃有余 2.淘宝爸爸一周后就给我泼凉水,增加了自己的反爬虫机制,出现如下错误。 1.首先很多熟悉JS的人都知道淘宝会检测window.navigator.webdriver(js检测特征之一),但是即使设置了"undefined"还是败下来,看看 4.可能大家觉得到这里就可以了,NO NO NO 这样子你还是登录不掉的。需要最后一个锦囊妙计!! 具体就是 你需要关闭chorme开发者模式,关闭自动测试状态,还需要将大家都熟知的把window.navigator.webdriver设为"undefined"。可能说的不太明白,图片帮你理解
加上这个代码会关闭“正受到自动测试软件的控制“的显示
加上这个代码可以关闭开发者模式 最后我们通过提前运行js的方法,把window.navigator.webdriver设为"undefined"! OK !!大功告成!!通过这么一步步下来,你会发现 我的天居然没有滑块!开森!! 需要具体完整代码的可以私聊我,翻滚吧,CODE君! |
 刚开始我以为是我频繁登录,导致淘宝的机器人识别我为代码进入。一般之前都是会在30分钟内解封。结果一天之后还是存在这个问题。查阅资料,翻了我的葵花宝典还是没有解决办法。后来看到一个文章,可能是淘宝再次更新了自己对selenium的验证,导致我不在成为漏网之鱼。唉唉唉,导致我3天没有解决。现在我把自己的坑和解决办法给大家分享一哈。成功的再次成为漏网之鱼,哈哈哈!
刚开始我以为是我频繁登录,导致淘宝的机器人识别我为代码进入。一般之前都是会在30分钟内解封。结果一天之后还是存在这个问题。查阅资料,翻了我的葵花宝典还是没有解决办法。后来看到一个文章,可能是淘宝再次更新了自己对selenium的验证,导致我不在成为漏网之鱼。唉唉唉,导致我3天没有解决。现在我把自己的坑和解决办法给大家分享一哈。成功的再次成为漏网之鱼,哈哈哈!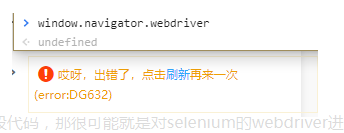 2.这时候细心的就需要观察一下他的全局JS,(这个是我参考别人的思路)你会发现淘宝爸爸在你浏览器内置的JS中有这么一段恐怖的代码
2.这时候细心的就需要观察一下他的全局JS,(这个是我参考别人的思路)你会发现淘宝爸爸在你浏览器内置的JS中有这么一段恐怖的代码 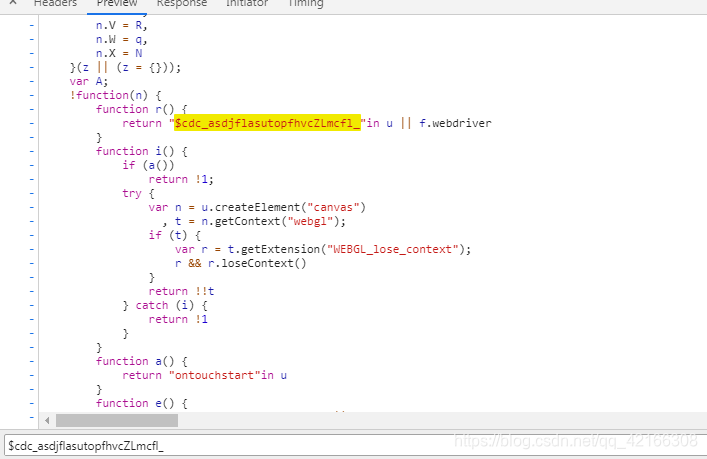 就是这个标黄色的东西,不会容易被发现的东西被检测到你是selenium进入,是不是特别坑!那我们接下来就需要干掉他。 3.这个时候仔细想一下,我们是通过什么打开浏览器呢?是的,知道的都会说webdriver.exe这个驱动。那我们就从他开始下手,当你打开webdriver.exe它后你会发现其中的问题! 注意:划重点!!!怎么打开和修改webdriver.exe。很多人都是乱码,之前我看到Windows系统采用nodepad++去打开就可以了,注意我的不行!你们可以试一下。(有的人是可以的,但是我的老师电脑不可以),然后我就找了一个办法,需要大家会一点vim操作,很简单的!准确的说就是Linux去解决,因为他不存在编码问题,不会像傻Windows,特别蠢!!开发人员最好还是用Linux系统吧! 经过我认真不负努力的搜索,诶找到一个靠谱的文章,哈哈!外国的‘知乎’ 文章链接:https://stackoverflow.com/questions/33225947/can-a-website-detect-when-you-are-using-selenium-with-chromedriver 就是他!
就是这个标黄色的东西,不会容易被发现的东西被检测到你是selenium进入,是不是特别坑!那我们接下来就需要干掉他。 3.这个时候仔细想一下,我们是通过什么打开浏览器呢?是的,知道的都会说webdriver.exe这个驱动。那我们就从他开始下手,当你打开webdriver.exe它后你会发现其中的问题! 注意:划重点!!!怎么打开和修改webdriver.exe。很多人都是乱码,之前我看到Windows系统采用nodepad++去打开就可以了,注意我的不行!你们可以试一下。(有的人是可以的,但是我的老师电脑不可以),然后我就找了一个办法,需要大家会一点vim操作,很简单的!准确的说就是Linux去解决,因为他不存在编码问题,不会像傻Windows,特别蠢!!开发人员最好还是用Linux系统吧! 经过我认真不负努力的搜索,诶找到一个靠谱的文章,哈哈!外国的‘知乎’ 文章链接:https://stackoverflow.com/questions/33225947/can-a-website-detect-when-you-are-using-selenium-with-chromedriver 就是他! 就是这段翻译后的操作。 注意 划重点 !!采用Linux系统的vim进去后你看到的也是乱码!!哈哈,but和Windows的乱码是不一样的,他会让你找到“$cdc_asdjflasutopfhvcZLmcfl_”这个字符串的,神奇吧。这就是Linux的强大!! 不会Linux命令的童鞋可以自己搜索一下,很简单的。修改后记得要保存哦!
就是这段翻译后的操作。 注意 划重点 !!采用Linux系统的vim进去后你看到的也是乱码!!哈哈,but和Windows的乱码是不一样的,他会让你找到“$cdc_asdjflasutopfhvcZLmcfl_”这个字符串的,神奇吧。这就是Linux的强大!! 不会Linux命令的童鞋可以自己搜索一下,很简单的。修改后记得要保存哦!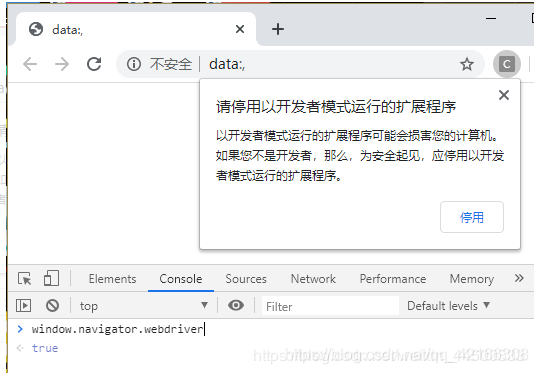
【本文地址】