| 数模学习第八天 | 您所在的位置:网站首页 › 模糊集合例题 › 数模学习第八天 |
数模学习第八天
|
模糊子集概述
模糊子集及运算
设U是论域,称映射 A(x):U→[0,1] 确定了一个U上的模糊子集A,映射A(x)称为A的隶属函数,它表示x对A的隶属程度。(模糊集看起来像一个集合,它不确定元素是否属于这个集合,界线不分明) 使A(x) = 0.5的点x称为A的过渡点,此点最具模糊性. 当映射A(x)只取0或1时,模糊子集A就是经典子集,而A(x)就是它的特征函数. 可见经典子集就是模糊子集的特殊情形.  3.梯形隶属函数 3.梯形隶属函数  4.高斯形隶属函数 4.高斯形隶属函数  一般钟形隶属函数 一般钟形隶属函数   模糊模式识别
模糊模式识别
模式识别: 已知某类事物的若干标准模式,现有这类事物中的一个具体对象,问把它归到哪一模式,这就是模式识别.模式识别在实际问题中是普遍存在的.例如,学生到野外采集到一个植物标本,要识别它属于哪一纲哪一目;投递员(或分拣机)在分拣信件时要识别邮政编码等等,这些都是模式识别. Step1确定判别规则:事先必须要有一个一般规则, 一旦知道了x的值, 便能根据这个规则立即作出判断, 称这样的一个规则为判别规则. Step2确定判别函数:判别规则往往通过的某个函数来表达, 我们把它称为判别函数, 记作W(i; x). —分类器 Step3回代检验:一旦知道了判别函数并确定了判别规则,最好将已知类别的对象代入检验,这一过程称为回代检验,以便检验你的判别函数和判别规则是否正确. 择近原则:第二类模糊识别问题(确定与标准模式库中哪一个更接近)
不满足传递性的话,就需要自乘,直到某个值满足传递性。 目的就是将模糊相似矩阵变为模糊等价矩阵。 只有具有传递性的模糊等价矩阵才能做模糊聚类分析。 下面做模糊聚类分析的分类方法。 Step1:数据标准化
2000A题DNA聚类分析 各DNA序列中每种氨基酸的摩尔含量多少是由序列的结构及其DNA分子的分子量等特征决定的,而其中大多数又是用于编码蛋白质,决定DNA的属性。因此,对DNA进行分类,充分统计DNA分子内每种氨基酸的绝对数,具有重要意义。 (1) 已知类别DNA序列的模糊分类 提取已知类别的20个DNA序列的A,T,C,G的百分含量构成如下矩阵:X = (xij)20×4,其中xi1, xi2, xi3, xi4分别表示第i个DNA系列中的A,T,C,G的百分含量. 采用切比雪夫距离法建立模糊相似矩阵,然后进行聚类,动态聚类图如下. 很多时候,人们不仅要从多种因素考虑,且一般只能用模糊语言描述。如显示器的舒适性,人员的政治立场坚定,某建设方案的社会影响等。 给定评价指标集合: %%%%%%%%%%%%%% 这就是对被评对象所做的单因素评价。然而,一般往往需要从几个方面来综合地评价某一事物,从而得到一个综合的评价结果。对多指标的综合评价,最终结果仍是评语集合V这一论域上的模糊子集,记作
|
 从上例可以看出: (1) 一个有限论域可以有无限个模糊子集,而经典子集是有限的; (2) 一个模糊子集的隶属函数的确定方法是主观的.
从上例可以看出: (1) 一个有限论域可以有无限个模糊子集,而经典子集是有限的; (2) 一个模糊子集的隶属函数的确定方法是主观的. ▽倒三角符号(上面缺一杠)表示取大
▽倒三角符号(上面缺一杠)表示取大 下面为内积与外积的分析
下面为内积与外积的分析 内积AB中先取小,取得0.4 0.6 0.8 0.8 0.6 0.4,再取大则为0.8 外积同理。 若更复杂呢?
内积AB中先取小,取得0.4 0.6 0.8 0.8 0.6 0.4,再取大则为0.8 外积同理。 若更复杂呢?  贴近度越大代表它越属于哪个模式
贴近度越大代表它越属于哪个模式  我们以一个例子来讲解贴近度分析与择近原则
我们以一个例子来讲解贴近度分析与择近原则  我们需要判别B(x)属于哪个品种,则分别计算A1,A2,A3,A4,A5与B的贴近度
我们需要判别B(x)属于哪个品种,则分别计算A1,A2,A3,A4,A5与B的贴近度

 如下图所示,>=0.3的为1
如下图所示,>=0.3的为1 
 若R满足(1)和(2)则为模糊相似矩阵; 若R满足(1)、(2)和(3)则为模糊等价矩阵。
若R满足(1)和(2)则为模糊相似矩阵; 若R满足(1)、(2)和(3)则为模糊等价矩阵。
 Step2:模糊相似矩阵建立方法
Step2:模糊相似矩阵建立方法 

 Step3:动态模糊聚类
Step3:动态模糊聚类 在模糊聚类分析中,对于各个不同的 入∈[0,1],可得到不同的分类,从而形成一种动态聚类图,这对全面了解样本分类情况是比较形象和直观的. 但在许多实际问题中,需要给出样本的一个具体分类,这就提出了如何确定最佳分类的问题. 可用F统计量确定分类,很多时候往往是通过经验确定分类。
在模糊聚类分析中,对于各个不同的 入∈[0,1],可得到不同的分类,从而形成一种动态聚类图,这对全面了解样本分类情况是比较形象和直观的. 但在许多实际问题中,需要给出样本的一个具体分类,这就提出了如何确定最佳分类的问题. 可用F统计量确定分类,很多时候往往是通过经验确定分类。 (2) 确定最佳分类(入 =0.913) 将20个已知DNA序列分成如下3类为最佳: A1 ={1,2,3,5,6,7,8 9,10}, A2 ={4,17}, A3 ={11,12,13,14,15,16,18,19,20}. 建立标准模式库:A1, A2, A3 (3) 未知DNA序列的模糊识别 采用格贴近度公式: 0(A, B) =[A ○B + (1 -A⊙B)]/2, 将隶属于A1的DNA序列归为A类,隶属于A3的DNA序列归为B类,隶属于A2的DNA序列归为非A,B类。
(2) 确定最佳分类(入 =0.913) 将20个已知DNA序列分成如下3类为最佳: A1 ={1,2,3,5,6,7,8 9,10}, A2 ={4,17}, A3 ={11,12,13,14,15,16,18,19,20}. 建立标准模式库:A1, A2, A3 (3) 未知DNA序列的模糊识别 采用格贴近度公式: 0(A, B) =[A ○B + (1 -A⊙B)]/2, 将隶属于A1的DNA序列归为A类,隶属于A3的DNA序列归为B类,隶属于A2的DNA序列归为非A,B类。 和评语集合:
和评语集合: 
 如对教材进行评价,假如评价科学性(u1)、实践性(u2) 、适应性(u3) 、专业性(u4)等方面,则评价指标集为U={u1,u2,u3,u4} 若评价结果划分为“很好” (v1) 、“好” (v2) 、“一般” (v3) 、“差” (v4)四个等级,评语集则为V={v1,v2,v3,v4} 若16%的人说“很好”,42%的人说“好”, 39%的人说“一般”, 3%的人说“差”,则评价结果可用模糊集描述
如对教材进行评价,假如评价科学性(u1)、实践性(u2) 、适应性(u3) 、专业性(u4)等方面,则评价指标集为U={u1,u2,u3,u4} 若评价结果划分为“很好” (v1) 、“好” (v2) 、“一般” (v3) 、“差” (v4)四个等级,评语集则为V={v1,v2,v3,v4} 若16%的人说“很好”,42%的人说“好”, 39%的人说“一般”, 3%的人说“差”,则评价结果可用模糊集描述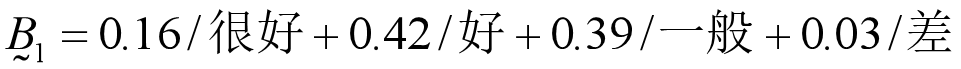 可简记为向量形式 B1=[0.16,0.42,0.39,0.03]
可简记为向量形式 B1=[0.16,0.42,0.39,0.03]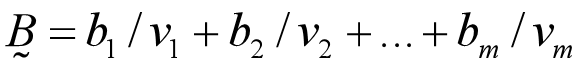 也可简记为m维向量模式。 实际评价工作中,考虑到不同评价因素重要性的区别,评价因素集合是因素集U这一论域上的模糊子集,记作:
也可简记为m维向量模式。 实际评价工作中,考虑到不同评价因素重要性的区别,评价因素集合是因素集U这一论域上的模糊子集,记作: 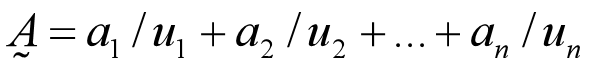 也可简记为n维向量形式。
也可简记为n维向量形式。  以上分析,我们可以得出模糊综合评价的步骤: 1.设定评价指标集U; 2.设定评语集V; 3.确定评价指标权重集 ; 4.用民意测验方法请专家实施评价; 5.建立评价矩阵 ; 6.按数学模型进行综合评价; 7.归一化处理,得出具有可比性的综合评价结果。 以下的矩阵计算,我们做出例子:
以上分析,我们可以得出模糊综合评价的步骤: 1.设定评价指标集U; 2.设定评语集V; 3.确定评价指标权重集 ; 4.用民意测验方法请专家实施评价; 5.建立评价矩阵 ; 6.按数学模型进行综合评价; 7.归一化处理,得出具有可比性的综合评价结果。 以下的矩阵计算,我们做出例子:
 则得出结论为较好。
则得出结论为较好。【本文地址】