| 【学习笔记】空间统计(常用) | 您所在的位置:网站首页 › 概率统计模型有哪些方法 › 【学习笔记】空间统计(常用) |
【学习笔记】空间统计(常用)
|
1 空间统计简要介绍
1.1 简要介绍
(1)空间统计分析是统计分析理论在空间科学的应用和拓展,是统计学与地理学交叉的学科内容,也是当前地理信息科学空间分析由空间几何分析向地学建模发展的理论工具和技术方法。 (2)与传统的非空间统计方法不同,空间统计方法是将地理空间(邻域、区域、连通性 和&或 其他空间关系)直接融入到数学逻辑中。 1.2 解决什么问题空间统计分析解决的中心问题是如何以数学统计模型来描述和模拟空间现象和过程,换句话说就是将地理模型转换成数学统计模型,以便进行定量描述和计算机处理。 1.3 应用领域人口、医学、经济、土地变化,而我目标是想讲空间统计方法应用到地缘分析中。 1.4 理论基础(1)地理学第一定律:All things are related, but nearby things are more related than distant things. 它强调空间联系(Spatial Association )与空间以来(Spatial Dependence),可以简称为空间自相关 Refer:W.R.Tobler.1970. A Computer movie simulating urban growth in the Detroit region. Economic Geography 46:234-240 (2)地理学第二定律:空间局部异质性(Spatial Local Heterogeneity)和空间分层异质性(简称空间分异性,Spatial Stratified Heterogeneity)。前者是指该店属性值与周围不同,例如热点和冷点;后者是指多个区域之间互不相同,例如分类和生态分区。 Refer:GoodChild,M.F. 2003. The fundamental laws of GIScience. Paper presented at the SummerAssembly of the University Consortium for Geographic Information Science, Pacific Grove,CA,June 1.5 空间统计与数学统计关系(1)什么是空间相关性? 相关,就是指相互关系,分为正相关与负相关。正相关就是醉着自变量的增长,因变量也随之增长;负相关则相反。空间上的正相关,就是指随着空间分布位置(距离)的聚集,相关性也就越发显著;空间上的负相关是指,随着空间分布位置的离散,相关性变得显著。 (2)全局空间自相关(Global Moran’s I)、高低聚类(Getis-Ord Genral G)、局部空间自相关(Local Moran’a I)、热点分析(Getis-Ord Gi*)区别于联系? 简单来说,前两者是从总体上判断的分布状态(集聚、分散、随机),后者是从局部上识别要素分散的位置与程度。(简单理解为,前两者为全局空间相关性检验,后两者是局部异质性检验) 1.6 实践操作中遇到的问题(随时补充)(1)ArcGIS中没有局部空间自相关(Local Moran’s I),LISA去哪里了? ArcGIS中的局部空间局部空间自相关叫做聚类和异常值分析(Anselin Local Moran’s I),也就是LISA(Local Indications of Spatial Assocoation) 2. 空间统计分布(部分内容来自ArcGIS操作文档) 2.1 地理分布思考两个问题: (1)要素分布的地理中心在哪里? (2)要素分布是否有特定的方向? 2.1.1 标准距离测量要素在几何平均中心周围的集中或分散程度。 补充: 此工具需要使用投影数据来准确测量距离一个标准差圆大小会包含聚类中约63%的要素,两个约98%的要素,三个99%的要素可以根据可选的权重字段参数计算标准距离(权重字段应为数值型字段)案例分组字段参数用于在分析前对要素进行分组输出Output:各圆面的属性包括的CenterX(平均中心X坐标)、CenterY(平均中心Y坐标)和StdDist(标准距离,圆半径) 2.1.2 方向分布创建标准差椭圆来汇总地理要素的空间特征:中心区是、离散和方向趋势,公式如下: C = ( v a r ( x ) c o v ( x , y ) c o v ( y , x ) v a r ( y ) ) = 1 n ( ∑ i = 1 n x ~ i 2 ∑ i = 1 n x ~ i y ~ i ∑ i = 1 n x ~ i y ~ i ∑ i = 1 n y ~ i 2 ) C=\left( \begin{matrix} var\left( x \right)& cov\left( x,y \right)\\ cov\left( y,x \right)& var\left( y \right)\\ \end{matrix} \right) =\frac{1}{n}\left( \begin{matrix} \sum_{i=1}^n{\tilde{x}_{i}^{2}}& \sum_{i=1}^n{\tilde{x}_i\tilde{y}_i}\\ \sum_{i=1}^n{\tilde{x}_i\tilde{y}_i}& \sum_{i=1}^n{\tilde{y}_{i}^{2}}\\ \end{matrix} \right) C=(var(x)cov(y,x)cov(x,y)var(y))=n1(∑i=1nx~i2∑i=1nx~iy~i∑i=1nx~iy~i∑i=1ny~i2) 补充: 需要投影进行精确测量距离标准差圆包含依次为68%、98%、99%的要素可以根据可选的权重字段计算标准差椭圆(例如,获取按严重程度衡量的交通事故椭圆),权重字段为数值型字段案分组字段参数用于在分析前对要素进行分组输出Output:各圆面的属性值包括圆的CenterX、CenterY,XStdDist(一个标准距离的长轴)、YStdDist(一个标准距离的短轴)和Rotation(方向)。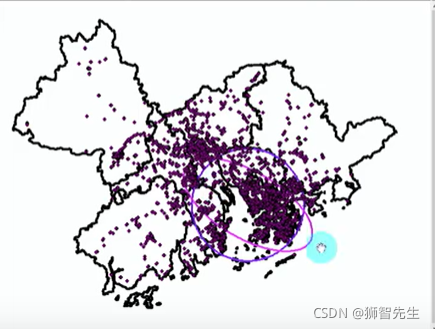 2.1.3 平均中心
2.1.3 平均中心
识别一组要素的地理中心(或密度中心),公式为: X ˉ = ∑ i = 1 n x i n , Y ˉ = ∑ i = 1 n y i n \bar{X}=\frac{\sum_{i=1}^n{x_i}}{n},\bar{Y}=\frac{\sum_{i=1}^n{y_i}}{n} Xˉ=n∑i=1nxi,Yˉ=n∑i=1nyi 加权中心,每个要素坐标乘以权重值。 补充: 需要投影以确保准确测量距离可以增加案例分组输出Output:平均中心是一个根据输入要素质心的平均x和y值构造的点。 2.1.4 线性方向平均值识别一组显得平均方向、长度和地理中心。 此工具输入必须是线要素类案例分组执行方向测量时,工具智慧考虑线要素的第一个点和最后一个点,而不会来考虑沿线的所有折点与标准差测量类似,圆方差(CirVar)值指示方向平均值矢量表示输入矢量集的好坏程度,圆方差的范围介于0到1之间。如果所有输入矢量具有完全相同(或非常相同的方向),则圆方差将很小;当输入矢量方向跨越整个罗盘时,圆方差将很大(接近1)。输出Output:CompassA 罗盘角(以正北方向为基准方向按顺时针旋转)DirMean 方向平均值(以整栋为基准方向按逆时针旋转)CirVar 圆方差(用于测量线方向或方位偏离方向平均值的程度)AveX和AveY 平均中心X和平均中心Y坐标AveLen平均线长度 2.1.5 中位数中心识别使数据集中要素之间的总欧氏距离达到最小的位置点。 2.1.6 中心要素识别点、线或面要素类中位于最中央的要素 补充: 案例分组与数据集中所有其他要素的距离累计最小的要素是位于最中心的要素;选择此要素并复制到新创建的输出要素类。多个要素可以共享与所有其他要素的最小累计距离。如果出现此情况,上述所有处于最中央位置的要素都将被复制到输出要素类。中心要素工具用于识别点、线或面要素类中处于最中央位置的要素。工具执行过程中会首先对数据集中每个要素质心与其他各要素质心之间的距离计算并求和。然后,选择与所有其他要素的最小累计距离相关联的要素,并将其复制到一个新创建的输出要素类中。输出Output:最中央位置的要素。 2.2 空间分析“分析模式”工具集中的工具都采用推论式统计,它们以零假设为起点,假设要素或与要素有关的指都表现为空间随机模式。然后它们再计算出一个p值用来表示零假设的正确概率。通常会先使用“分析模式”工具集中的工具进行初始分析,然后再进行更深入的分析。例如可以使用增量空间自相关工具来确定在哪个距离处促进空间聚类的过程最明显,这可能有助于您选择一个合适的距离(分析尺度)来深入研究热点(热点分析)。 2.2.1 多距离聚类确定要素(或与要素相关联的值)是否显示某一距离范围内具有统计显著性的聚类或离散。 2.2.2 空间自相关(莫兰指数)【重要】空间自相关工具同时根据要素位置和要素值来度量空间自相关,在给定一组要素及相关属性的情况下,该工具评估所表达的模式是聚类模式、离散模式还是随机模式。该工具通过计算Moran’s I 指数值,z得分和p值来对该指数的显著性进行评估。p值是根据遗址分布的曲线得出的面积近似值。 I = n S 0 ∑ i = 1 n ∑ j = 1 n w i , j z i z j ∑ i = 1 n z i 2 I=\frac{n}{S_0}\frac{\sum_{i=1}^n{\sum_{j=1}^n{w_{i,j}z_iz_j}}}{\sum_{i=1}^n{z_{i}^{2}}} I=S0n∑i=1nzi2∑i=1n∑j=1nwi,jzizj 其中, z i z_i zi是要素 i i i的属性与其平均值 ( x i − x ˉ ) \left( x_i-\bar{x} \right) (xi−xˉ)的偏差, w i , j w_{i,j} wi,j是要素 i i i和 j j j之间的空间权重, n n n等于要素总数, S 0 S_0 S0是所有空间权重的聚合: S 0 = ∑ i = 1 n ∑ j = 1 n w i , j S_0=\sum_{i=1}^n{\sum_{j=1}^n{w_{i,j}}} S0=i=1∑nj=1∑nwi,j 统计的zi得分按以下形式计算: z I = I − E [ I ] V [ I ] z_I=\frac{I-E\left[ I \right]}{\sqrt{V\left[ I \right]}} zI=V[I] I−E[I] “空间统计分析与传统的统计分析,最大的区别就在于空间统计学吧空间信息和空间关系都直接整合到了算法之中…常见的空间关系概念化包括了距离、行程时间、固定距离、K最邻近,邻接等,具体使用哪个,取决于要测量的对象是什么…度量不同的研究对象,选择的概念就不同。” 空间自相关结果解释: (1)什么是零假设? Null hypothesis,指进行统计检验时预先建立的假设,零假设的内容一般是希望证明其错误的的假设,因为纯随机(完全随机)是无法预测也无法找到模式的。大多数统计检验在开始都确定一个零假设。模式分析工具的零假设是完全空间随机性(CSR),它或者是要素本身的完全空间随机性,或者是与这些要素关联的值的完全空间随机性。 模式分析工具所返回的z得分和p值可帮助判断是否可以拒绝零假设。通常,将运行其中一种模式分析工具,并希望z得分和p值表明可以拒绝零假设,这就意味着:输入的要素表现出来的统计意义上的显著性聚类或离散模式,而不是随机模式。 (2)z得分与p值 p值,p-value,probability,表示概率,碎玉模式分析工具来说,p值表示所观察到的空间模式是由某一随机过程创建而成的概率,当p很小时,意味着所观测道德空间模式不太可能产生于随机过程(小概率事件),因此可以拒绝零假设。 z得分,z-score,便是标准差的倍数,例如,如果工具返回的z得分为+2.5,我们就会说结果是2.5倍标准差。z得分越高,聚类程度就越高。如果z得分接近灵,则表明研究区域内不存在明显的聚类。z得分为正表示高值的聚类,z得分为负表示低值的聚类。 使用Getis-Ord General G 统计可度量高值或低值的聚类程度,实际上就是测量研究区域高值或者低值的密度。 公式为: G = ∑ i = 1 n ∑ j = 1 n w i , j x i x j ∑ i = 1 n ∑ j = 1 n x i x j , ∀ i ≠ j G=\frac{\sum_{i=1}^n{\sum_{j=1}^n{w_{i,j}x_ix_j}}}{\sum_{i=1}^n{\sum_{j=1}^n{x_ix_j}}},\forall i\ne j G=∑i=1n∑j=1nxixj∑i=1n∑j=1nwi,jxixj,∀i=j 其中, x i x_i xi、 x j x_j xj是要素i,j的属性值, w ( i , j ) w_(i,j) w(i,j)是它们的空间权重, n n n等于要素的总数目, ∀ i ≠ j \forall i\ne j ∀i=j表示任意的要素i,j不能作为相同要素出现。 补充: 工具使用投影进行精确计算General G方法,对平均数非常敏感,在利用Genaral G的时候,最好先进行直方图探索,数据分布越接近钟形曲线,那么使用General G的效果就越好;极值越多效果就越不明显。 2.2.4 平均最近邻根据每个要素与其最邻近要素之间的平均距离计算其最近邻指数,可以比较多份数据的聚集程度高低。平均最近邻工具可测量每个要素的质心与其最邻近要素质心位置之间的距离,然后计算所有这些最近领距离的平均值,如果该平均距离小于假设随机分布中的平均距离,则会将所分析的要素分布视为聚类要素。如果该平均距离大于假设随机分布中的平均距离,则会将要素视为分散要素,平均最近邻比率通过观测的平均距离除以期望的平均距离计算得出。公式为: A N N = D ˉ O D ˉ E ANN=\frac{\bar{D}_O}{\bar{D}_E} ANN=DˉEDˉO D ˉ O = ∑ i = 1 n d i n \bar{D}_O=\frac{\sum_{i=1}^n{d_i}}{n} DˉO=n∑i=1ndi D ˉ E = 0.5 n A \bar{D}_E=\frac{0.5}{\sqrt{\dfrac{n}{A}}} DˉE=An 0.5 其中, D ˉ O \bar{D}_O DˉO是每个要素与最邻近要素之间的观测平均距离, D ˉ E \bar{D}_E DˉE是随机模式下制定要素间的期望平均距离, n n n表示要素数量, A A A表示面积(最小外接四边形或指定的四边形)。 2.2.5 增量空间自相关(Incremental Spatial Autocorrelation)增量空间自相关工具为一系列增大的距离运行空间空间自相关(Global Moran’s I)工具,同时测量个距离空间聚类的程度。聚类的程度由返回的z得分确定。 补充: 需要投影以进行精确测量。测量一系列距离的空间自相关,并选择性创建这些距离及其相应z得分的折线图。z得分反应空间聚类的程度,具有统计显著性的峰值z得分表示促进空间过程聚类最明显的距离。这些峰值距离通常为具有“距离范围”或“距离半径”参数的工具所使用的的合适值。此工具有助于为具有这些参数(热点分析或点密度)的工具选择合适的距离阈值或半径。当显示多个具有统计显著性的峰值时,鞠磊在这些距离处均很明显。选择与感兴趣的分析比例对应的峰值距离;通常为遇到的第一个具有统计显著性的峰值。 3 聚类分布制图 3.1 分组分析根据要素属性和可选的空间时态约束对要素进行分组。给定要创建的组数,它将寻找一个能够使每个组中的所有要素都尽可能相似但哥哥组之间尽可能不同的解。 3.2 聚类和异常值分析(局部莫兰指数 Anselin Local Moran’s)给定一组要素(输入要素类)和一个分析字段(输入字段),聚类和异常值分析工具可识别具有高值或者低值的要素的空间聚类,还可识别空间异常值。 公式为: I i = x i − X ˉ S i 2 ∑ j = 1 , j ≠ i n w i , j ( x j − X ˉ ) I_i=\frac{xi-\bar{X}}{S_{i}^{2}}\sum_{j=1,j\ne i}^n{w_{i,j}\left( x_j-\bar{X} \right)} Ii=Si2xi−Xˉj=1,j=i∑nwi,j(xj−Xˉ) 其中, x i x_i xi是要素类i的属性, X ˉ \bar{X} Xˉ是对应属性的平均值, w ( i , j ) w_(i,j) w(i,j)是要素i和j之间的空间权重,并且: S i 2 = ∑ j = 1 , j ≠ i n ( x j − X ˉ ) n − 1 S_{i}^{2}=\frac{\sum_{j=1,j\ne i}^n{\left( x_j-\bar{X} \right)}}{n-1} Si2=n−1∑j=1,j=in(xj−Xˉ) 最近关于GIS的展望 空间本体与认知计算Spatial Ontology and Cognitive Computing空间人工智能系统Geospatial Artificial Intelligence Systems地理信息感知与智能服务Perception of Geographical Information and Intelligent Services物联网与智慧城市Internet of Things and Smart Cities自动驾驶与高精地图Autopilot and High-Precision maps地理计算与虚拟地理环境Geospatial Computing and Virtual Geographic Environments地图综合与智能制图Map Generalization and Intelligence in Cartography地图(集)设计与创意Map(Atlas) Design and Creativity智慧海洋与海洋制图Smart Ocean and Mapping全球环境变化分析Analysis of Global Environmental Change月球与行星制图Lunar and Planetary Cartography |
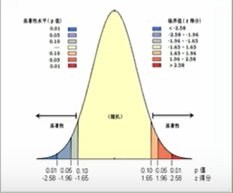 补充:正态分布中间位置的值代表了预期的结果。但在z得分的绝对值很大而概率很小时(出现在正态分布的两端),就会查看其中存在的不寻常现象并且这也非常有趣。例如,对于热点分析工具,不寻常意味着出现了具有统计显著性的热点或冷点。
补充:正态分布中间位置的值代表了预期的结果。但在z得分的绝对值很大而概率很小时(出现在正态分布的两端),就会查看其中存在的不寻常现象并且这也非常有趣。例如,对于热点分析工具,不寻常意味着出现了具有统计显著性的热点或冷点。【本文地址】