| 离散选择模型DCM简介及R实例 | 您所在的位置:网站首页 › 概率判别模型介绍 › 离散选择模型DCM简介及R实例 |
离散选择模型DCM简介及R实例
|
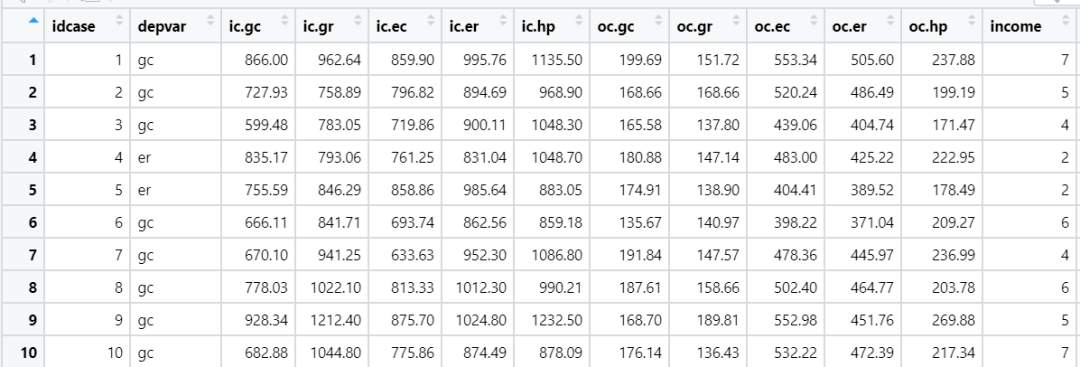
在实际应用中,IIA假设限制条件是很难满足的,而且多项Logit模型假设被调查者的偏好系数是固定值,忽略了被调查者偏好的差异性。如果Hausman检验发生不符合IIA假设时,需选择多项式Probit模型、混合Logit模型(随机参数Logit模型)等模型进行研究分析。 条件logit模型 当解释变量为方案相关的属性时,则被调查者在 个选项中选择第 个方案的概率也可以表达为: 条件Logit模型的估计方法与多项Logit 模型类似,但在条件Logit模型中,方案的一个属性 对于不同方案效应的影响是一致的的,系数 变化与方案无关。在条件Logit模型中自变量类型为随个体和方案而变的方案属性,在分析中数据集格式为几行数据对应一个样本,如有3个方案(mode=1,2,3)被调查者进行选择(choice=1,已选;choice=0,未选),3个方案对应不同消耗时间(time)和费用(price)数据集格式下图所示: id mode choice time price 1 1 0 45 50 1 2 1 60 45 1 3 0 50 48 混合Logit模型 混合Logit模型又称随机参数Logit模型,它考虑了随机偏好差异,能处理更为复杂的相关性,不受限于IIA假设。一般模型中自变量类型包含了个人属性和随个体和方案而变的方案属性。在混合Logit模型中效用分为三部分,包括 固定效用项、 随机效用项和 误差项,具体效用表现形式为: 其中误差项 允许选择项之间存在相关性,满足个体选择偏好差异。 常见的分布形式有正态分布、对数正态分布、均匀分布等。可以根据不同的情形假设不同的分布形态。如对于无限多分类变量往往假设服从正态分布;均匀分布适用性广,对于参数的符号等没有要求,尤为适用于二分类变量。混合Logit模型中选择概率为: 其中 指系数 分布的参数, │ 为某种分布的概率密度函数,即该模型的选择概率可以看作是多项Logit模型选择概率的加权平均值,具体权重由 │ 决定。 │ 的分布形式通常为上述的几种,可根据实际情况选择合适的分布形式。待估参数 � ,其均值 代表所有被调查对象对于某个选项的平均偏好,标准差 代表这种偏好的变异程度,标准差是否有统计学意义表示了这种偏好在被调查者中的总体变异是否存在。 模型拟合优度的判断 (1)伪 McFadden's ,也称伪 ,是基于与似然比检验相似思路去判断模型的常见拟合优度指标。伪 范围在0到1之间,越接近1,模型的拟合效果越好。在实际分析中如果侧重影响因素的分析,可以不太注重这个指标。 (2)模型预测准确率 可以根据预测对的样本数量除以总样本数量的值进行判断。 (3)AIC与BIC指标 AIC和BIC等指标也用于评判模型拟合优度,一般AIC和BIC越小表明模型的拟合优度越高,多用于比较多个模型的优劣。 R实例 常见的离散选择模型软件有NLOGIT、SAS、Stata、SPSS、R等,在R中可以使用mlogit函数进行分析。以Heating为例,该数据是关于加州900名被调查者在房屋五种供暖系统方案(gc,gr,ec,er,hp)的选择,这个数据中包含了被调查者收入(income)等基本信息以及根据其房屋特征等计算每个方案的安装的成本(ic)、每年运营的成本(oc)等变量。 1. 加载软件包,读取数据 library(mlogit)data("Heating", package = "mlogit")
2. 整理数据格式 将关于供暖系统中各个方案属性的变量整理为所需的格式,即整理为几行方案选择数据对应一个样本。 H |
【本文地址】