| 朴素贝叶斯的适用场景 | 您所在的位置:网站首页 › 朴素贝叶斯算法的应用领域 › 朴素贝叶斯的适用场景 |
朴素贝叶斯的适用场景
|
贝叶斯定理 (Bayes’ Theorem)
Bayes’ Theorem gives us the posterior probability of an event given given what is known as prior knowledge. 给定已知的先验知识,贝叶斯定理为我们提供了事件的后验概率。 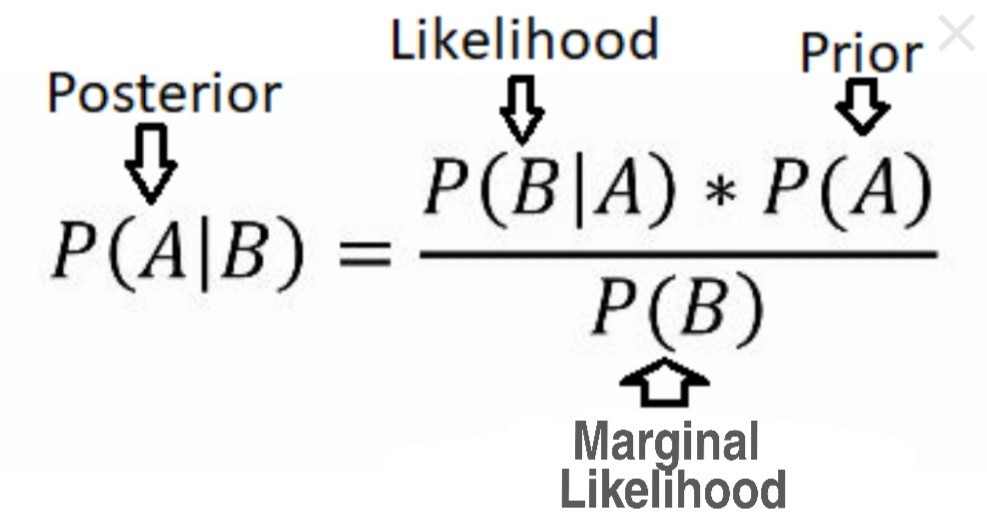
Prior probability is nothing but the proportion of dependent (binary) variable in the data set. It is the closest guess you can make about a class, without any further information or you can say how probable is A before observing B. 先验概率不过是数据集中因变量(二进制)的比例。 这是您对一堂课的最接近的猜测,无需任何其他信息,或者您可以在观察B之前说出A的可能性。 Likelihood is the probability of classifying a given observation as one kind in presence of some other variable. In other words how probable is B when given that A is true or happened. 可能性是在存在某些其他变量的情况下将给定观察分类为一种的概率。 换句话说,当给定A为真或发生时,B有多大的可能性。 Marginal likelihood is, how probable is the new datapoint under all the possible variables. 边际可能性是,在所有可能的变量下,新数据点的可能性是多少。 
Naive Bayes Classifier is a Supervised Machine Learning Algorithm. It is one of the simple yet effective algorithm. Naive Bayes algorithm classify the object or observation with the help of Bayes Theorem. 朴素贝叶斯分类器是一种监督式机器学习算法。 它是一种简单而有效的算法。 朴素贝叶斯算法借助贝叶斯定理对物体或观测进行分类。 Naive Bayes is a classification technique based on an assumption of independence between predictors which is known as Bayes’ theorem. In simple terms, a Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature. 朴素贝叶斯是一种基于预测变量之间独立性的假设的分类技术,称为贝叶斯定理 。 简而言之,朴素贝叶斯分类器假定类中某个特定功能的存在与任何其他功能的存在无关。 The most common question that comes in our mind by the name of this algorithm. 该算法的名称是我们脑海中最常见的问题。 问:为什么朴素贝叶斯这么“朴素”? (Q. Why is naive Bayes so ‘naive’ ?)Naive Bayes is so ‘naive’ because it makes assumptions that are virtually impossible to see in real-life data and assumes that all the features are independent. 朴素贝叶斯之所以如此“朴素” ,是因为它做出了在现实生活中几乎看不到的假设,并且假设所有功能都是独立的。 朴素贝叶斯算法 (Naive Bayes Algorithm)Let’s take an example and implement the Naive Bayes Classifier, here we have a dataset that has been given to us and we’ve got a scatterplot which represents it. We just have two columns and observation or data points are classified into two different categories in red and green. So the X-axis represents Age, while Y-axis represents Salary. The category of people who walks to their work is in red and in green is the category of people who drives to their work. 让我们以一个示例并实现朴素贝叶斯分类器为例,这里有一个数据集已经提供给我们,并且我们有一个散点图表示它。 我们只有两列,观察点或数据点分为红色和绿色两个不同类别。 因此,X轴表示年龄,而Y轴表示薪水。 上班的人的类别为红色,而绿色为上班的人的类别。 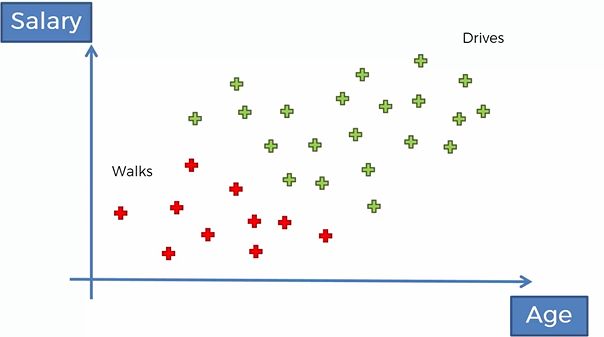
So now what happens if we make a new observation, a new data point into the set, how do we classify this new data point. We are going to classify the new datapoint by using Naive Bayes theorem to depict whether it belongs to the red or green point category, i.e., that new person walks or drives to work? 因此,现在如果我们进行新的观察,将新的数据点放入集合中,会发生什么情况,如何对新数据点进行分类。 我们将使用朴素贝叶斯定理(Naive Bayes theorem)描述新数据点,以描述它属于红点还是绿点类别,即,新人走路还是开车去上班? 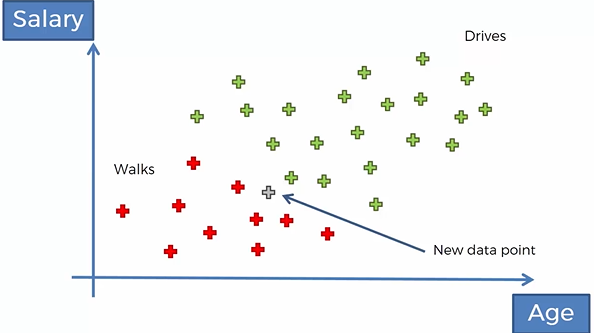
We are going to take the Bayes theorem and apply it twice. 我们将采用贝叶斯定理并对其应用两次。 We are going to calculate the probability or you can say posterior probability of the event that the person walks to work according to the given feature of the new data point. 我们将计算概率,或者您可以说根据新数据点的给定特征,该人走路上班的事件的后验概率。 X in the function here which represents the feature of that data point. For example, that person’s age maybe is like 26 years old and the salary $ 2900 per year. So these are the feature of the observation we are only working with two variables just for simplicity but in reality, there can be many many more features. 函数中的X代表该数据点的特征。 例如,该人的年龄可能约为26岁,年薪为2900美元。 因此,这些是观察的特征,为简单起见,我们仅使用两个变量,但实际上,可以有许多其他特征。 

So in order to calculate the Posterior Probability, we are going to calculate the Prior Prabability i.e. P(Walk), which is the total number of walker divided by the total number of observations. 因此,为了计算后验概率,我们将计算先验概率,即P(Walk),即步行者总数除以观察总数。 In the next step, we are going to calculate the marginal likelihood or the evidence. The first thing we are going to do is to select a radius and we’re going to draw a circle around the new observation or data point and then we are going to look at all the points that are inside the circle, Anybody who falls somewhere in that vicinity is going to be deemed similar to the new data point that we’re adding to our dataset. 在下一步中,我们将计算边际可能性或证据。 我们要做的第一件事是选择一个半径,然后围绕新观测值或数据点绘制一个圆,然后我们将查看圆内的所有点,任何落入某处的人该附近的区域将被视为与我们要添加到数据集中的新数据点相似 。 The Marginal Likelihood is the number of similar observations divided by the total number of observations. 边际可能性是相似观察数除以观察总数。 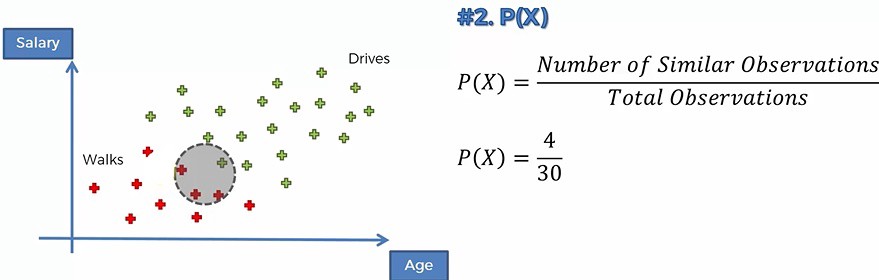
The likelihood is the randomly selected data point from the dataset from the red dots is somebody who exhibits features similar to the point that we are adding to our dataset or in other words, a randomly selected redpoint falls into the circle area. Now Likelihood and P(X|Walks) is the Likelihood that somebody who walks exhibits feature X. 可能性是从红点中从数据集中随机选择的数据点是某人,其特征类似于我们要添加到数据集中的点,换句话说,随机选择的红点落入了圆圈区域。 现在, 可能性和P(X | Walks)是行走的人展示的特征X的可能性。 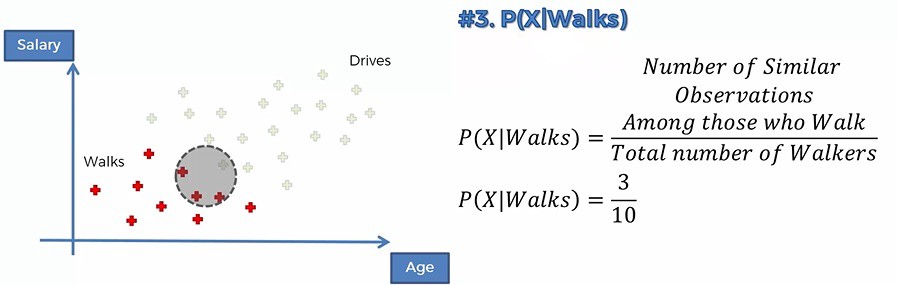
Now we have calculate the Posterior Probability by using the value Prior probability, Marginal likelihood and the Likelihood and got the value of Posterior Probability as 0.75 i.e. 75% is the probability that new data point would be classified as a person who walks to the work and 25%(1–0.75) is the probability that a new data point would be classified as a person who drives to work as this is a binary classification. If this was not a binary classification, then we need to calculate for a person who drives, as we have calculated above for the person who walks to the work. 现在我们已经使用后验概率,边际可能性和似然性的值计算了后验概率,并且后验概率的值为0.75,即75%是新数据点将被归类为上班的人的概率,并且25%(1-0.75)是将新数据点归类为开车的人的概率,因为这是二进制分类。 如果这不是二进制分类,那么我们需要为开车的人计算,就像我们上面为走路的人计算的那样。 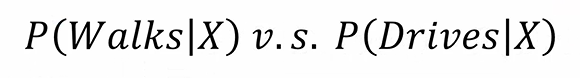
Now we will compare the probability of both the category and the new data point will fall under the category which has a greater probability than the other. 现在,我们将比较类别和新数据点都属于该类别的概率,该类别的概率要大于另一个类别。 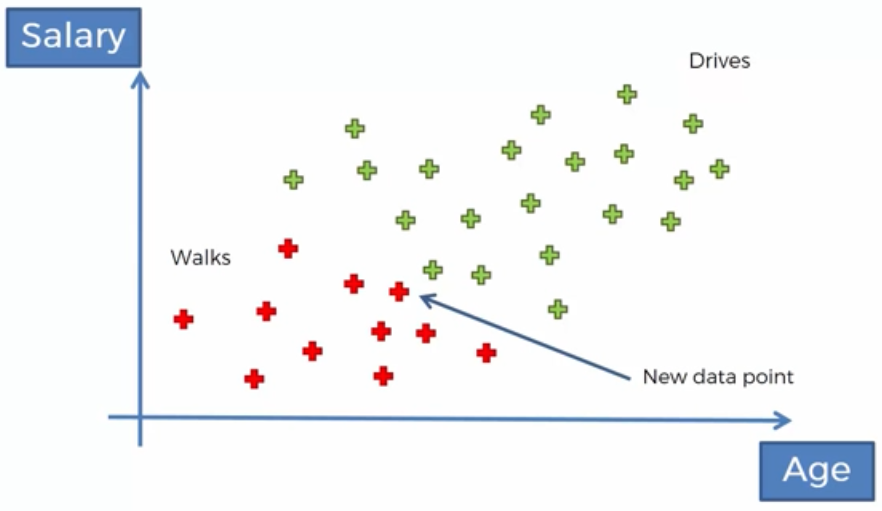
So Finally, we classified the new data point,a person who walks to work as a redpoint. 因此,最后,我们将新数据点归类为一个步行上班的人。 This is how Naive Bayes Classifier Works. 这就是朴素贝叶斯分类器的工作方式。 Naive Bayes Classification Algorithm is highly efficient and not biased by the Outliers. Naive Bayes algorithm works on Non-Linear data problems and used when we want to rank our predictions by their Probability. 朴素贝叶斯分类算法非常高效,并且不受异常值的影响。 朴素贝叶斯算法可用于处理非线性数据问题,并在我们要根据其概率对预测进行排名时使用。 |
【本文地址】