| 【Paper Reading】Encoding Recurrence into Transformers(ICLR 2023) | 您所在的位置:网站首页 › 文章communication和paper › 【Paper Reading】Encoding Recurrence into Transformers(ICLR 2023) |
【Paper Reading】Encoding Recurrence into Transformers(ICLR 2023)
 Motivation Motivation本文的主要工作是将RNN中循环动力(recurrent dynamics)以一个可忽略的损失集成到了transformer当中。RNN和Transformer都是经典的神经网络模型,他们的优势和劣势总结如下: ProsConsRNN• 能够处理包含时序信息的数据• 梯度消失问题• 很难实现并行训练transformers• 能够处理长程依赖关系• 可以并行训练• 时序信息通常被忽略• 需要大量的样本来学习 横轴从左到右代表数据的循环特征越来越弱,纵轴从下往上代表数据规模越来越大。 横轴从左到右代表数据的循环特征越来越弱,纵轴从下往上代表数据规模越来越大。上图在数据规模和数据的循环特性两个维度上来评价RNN和transformer两种模型。从图中可以看出,即使很少的数据规模,RNN也可以很好地处理带有循环特性的数据。只要数据量足够大,transformer既可以处理带有循环特性的信息,也可以处理不带有循环特性的信息。所以有动机将二者结合起来,本文提出的RSA(Self-Attention with Recurrence)可以很好地结合二者的优点。 Related Work将RNN结合到transformer中的工作已经有非常多了,但是大部分的结合也导致了transformer失去并行训练的能力,结合了二者优点的同时也结合了二者的缺点。 RNMT+ Attentive Recurrent Network(ARN) Attentive Recurrent Network(ARN) R-transformer R-transformer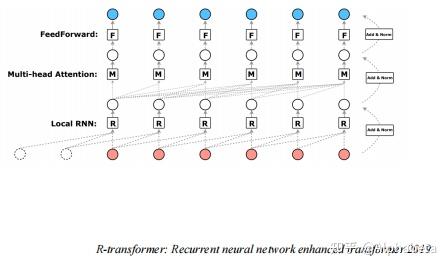 上面几种结合的方式都没有很好地避免RNN无法并行训练的缺点,下面几个工作一定程度上避免了这个问题,但是没有很好地利用RNN的特性,在更精细的粒度(token-level)上是没有考虑循环特征的。 Feedback Transformer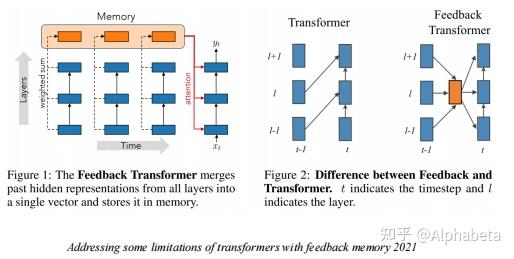 Transformer-XL Transformer-XL TLB: Temporal Latent Bottleneck TLB: Temporal Latent Bottleneck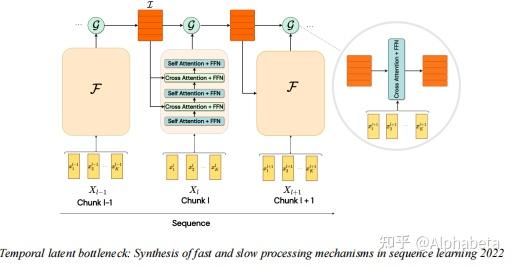 BRT: Block-Recurrent Transformer BRT: Block-Recurrent Transformer  如上图所示,像Transformer-XL,是在segment-level考虑循环特性,TLB和BRT在chunk-level考虑循环特性,而本文的RSA能够实现在Token-level上考虑循环特性。 MethodREM:Recurrence Encoding Metrics本节首先证明,RNN可以以一个近似可忽略的损失,转化为多头自注意力(MHSA)的形式。首先对于一个RNN模型,其形式为: h_t = g(W_hh_{t-1}+W_x x_t + b) 。当激活函数 g 是线性的,那么RNN的形式转换为: h_t = W_hh_{t-1}+W_x x_t = \sum_{j=0}^{t-1}W_h^jW_xx_{t-j} ,其中 b 没有表达更多信息,简单起见可以忽略。RNN难以并行计算的关键问题就在 W_h^j 这个矩阵的指数运算上。接下来的讨论都基于激活函数为线性的假设,本文提及的“可忽略的损失”就来源于将RNN线性化,作者在附录中对损失进行了讨论。  Lemma 1 (Theorem 1 in Hartfiel (1995)). Real matrices with R distinct nonzero eigenvalues are dense in the set of all d × d real matrices with rank at most R, where 0 < R ≤ d. 根据上述引理,任意一个秩为 R 的 d\times d 大小的矩阵,可以假定其 R 个特征值都是非零的。那么记 W_h 有 r 个实数特征值 \lambda_1,...,\lambda_r ,有 2s(R = r+2s) 个复数特征值 \gamma_1cos(i\theta),\gamma_1sin(i\theta),...,\gamma_scos(i\theta),\gamma_ssin(i\theta) ,我们可以对 W_h 进行特征分解,得到 W_h = BJB^{-1} ,那么 W_h^j = BJ^jB^{-1} ,将其带入 h_t 中,得到:  其中 G_k^R 和 W_x 都是参数矩阵,我们可以简化成一个 W_x^R 得到 h_t^R(\lambda)=\sum_{j=1}^{t-1}\lambda^jW_x^Rx_{t-j} ,后面复数对应的两部分也同理。可以看到,我们将 h_t 分成了 r+2s+1 部分,这在之后的MHSA中刚好对应 r+2s+1 个头。最关键的是,我们将原本的 W_h^j 转换成了 \lambda^j ,实数的指数完全可以实现并行计算。 接下来进一步在形式上进行转换,我们将 h_t 的计算写成矩阵形式。首先定义矩阵 P^R_{mask} 如下,其中 f_t(\lambda) = \lambda^t 。  那么就有, (h_1^R,h_2^R,...,h_T^R )'= P^R_{mask}V = [softmax(QK')+P^R_{mask}]V = SA^R ,其中 Q 和 K 都是全零的矩阵,复数部分同理。我们成功将RNN以可忽略的损失转到成了MHSA的形式,图示如下:  PE包含三种形式的矩阵,其中实数特征值代表的矩阵中的数值呈指数衰减,复数特征值代表的矩阵中的数值呈正余弦周期性变化,分别代表了随时间指数衰减的特征和周期性变化的特征。 RSA:Self-Attention with Recurrence经过如上讨论,很自然,我们可以使用门控机制把非零的 Q 和 K加入进来,同时也是将RNN加入到了transformer当中,如下:   Implementation Bidirectional RNNs Implementation Bidirectional RNNs 当需要将双向RNN的特征加入transformers当中时,可以将 P 矩阵转置相加,得到新的 P 矩阵。  Dilated REM variants. Dilated REM variants.作者还引用了RNN中一个经典的dilated方法,使得RNN结构能够表达更长跨度的信息。  More discussions on REMs More discussions on REMs最终的RNN以一个参数矩阵 P 的形式加入到了MHSA当中,其参数是指数关系关联起来的,是否可以使用完全参数矩阵来使模型自己学习循环特征?作者给出的解释是,这样更加general但是less effective。 Experiments 作者在Time Series Forecasting、Regular language、Code 和 Natural Language,四种任务上进行了实验。首先,因为使用了门控机制,在四种任务上transformer对于RNN信息的使用是不同的,在Time Series Forecasting和Regular language任务上, P 起到了相当重要的作用,而Code 和 Natural Language中 P 几乎不起作用,这是符合直觉的,因为四种任务的时间序列特性递减,在最终的实验中,该方法的提升程度也递减。 |
【本文地址】