| hashCode()到底有什么用,为啥一定要和equals()重写 | 您所在的位置:网站首页 › 数组的位置叫什么 › hashCode()到底有什么用,为啥一定要和equals()重写 |
hashCode()到底有什么用,为啥一定要和equals()重写
|
hashcode()方法常搭配equals()方法使用。 hashcode()和equals()方法一样,都是定义在Object顶层父类中,子类可以进行重写。
但有一个问题就是效率太低了,每次都得遍历整个数组。假设数组中有一万个对象,那每次操作都比较一万次。此时时间复杂度为O(n)。
这样无论是存储元素还是获取元素,通过数组下标就只用操作一次,时间复杂度为O(1)。 确定索引位置就能大幅提高效率。不过现在还有一个很大的问题,那就是哈希码是可能会重复的。毕竟哈希码只是通过一定的逻辑计算出来的逻辑数值,那两个不同的对象完全有可能哈希码会相同。这就是我们常说的哈希冲突。 当要存储的对象和已经存储的对象发生哈希冲突时,我们首先要做的,就是判断这两个对象是否相等,如果相等,那么就算作重复元素,那么就不用存储了。如果不相等,那再将新对象想别的方法存储起来。 因为hashCode方法用来定位索引位置以提高效率的同时可能会发生哈希冲突。当哈希冲突时,我们就得通过equals()方法来判断冲突的对象是否相等。 如果只重写了hashCode(), 那哈希冲突发生时,即使两个对象相等,也不会被判定为重复。进而导致数组里会存储一大堆重复对象。 如果只重写了equals(), 那两个相等的对象,内存地址可不会相等,这样还是会造成重复元素的问题。 所以两个方法最好一起重写。 最后总结一下,hashCode方法用来在最快时间内判断两个对象是否相等,并定位索引位置。不过可能会出现误差。equals方法用来判断两个对象是否绝对相等。hashCode()方法用来保证性能,equals方法用来保证可靠。 参考资料:【每天一个技术点】hashCode()到底有什么用,为啥一定要和equals()重写 |
 hashCode()方法是native方法,如果没有重写,那它通常会将内存地址转换为int数值进行返回,我们用hashCode()获取到的这个int数值就是哈希码,也叫散列码。
hashCode()方法是native方法,如果没有重写,那它通常会将内存地址转换为int数值进行返回,我们用hashCode()获取到的这个int数值就是哈希码,也叫散列码。 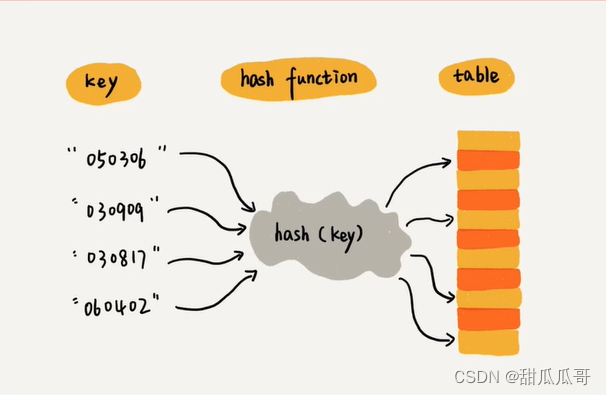 它的作用就是确定对象在哈希表中的索引位置,只要搞懂了哈希表的机制,也就能搞懂hashCode()了。
它的作用就是确定对象在哈希表中的索引位置,只要搞懂了哈希表的机制,也就能搞懂hashCode()了。 哈希表的基本原理,假设现在有这么一个需求,我想让一批对象能够存储起来,不允许存储重复的对象,并且能够随时获取对象。
哈希表的基本原理,假设现在有这么一个需求,我想让一批对象能够存储起来,不允许存储重复的对象,并且能够随时获取对象。 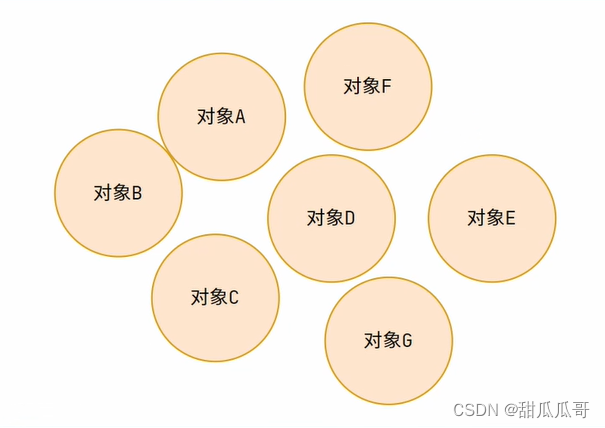 一说起存储,那自然就想到了数组,我们可以将对象挨个放入数组中。当判断对象是否重复存储时,或者当获取执行对象时,我们每次都得从头开始遍历数组,挨个和数组中的对象进行equals()比较,equals()结果为真,就代表找到了指定对象,这样确实满足了需求。
一说起存储,那自然就想到了数组,我们可以将对象挨个放入数组中。当判断对象是否重复存储时,或者当获取执行对象时,我们每次都得从头开始遍历数组,挨个和数组中的对象进行equals()比较,equals()结果为真,就代表找到了指定对象,这样确实满足了需求。 可以通过hashCode()来提高效率,hashCode()获取到的哈希码就派上用场了。我们在存放对象时,可以通过哈希码来和数组长度取余,这样就能得到数组存放的位置,比如数组长度为10,对象的哈希码为17,那17除以10会余7,我么就可以将这个对象存放在下标7的位置上。
可以通过hashCode()来提高效率,hashCode()获取到的哈希码就派上用场了。我们在存放对象时,可以通过哈希码来和数组长度取余,这样就能得到数组存放的位置,比如数组长度为10,对象的哈希码为17,那17除以10会余7,我么就可以将这个对象存放在下标7的位置上。 那两个哈希冲突的对象如何判断相等呢,当然是用equals()了,这里也就明白了,为什么hashCode()和equals()方法要同时重写。
那两个哈希冲突的对象如何判断相等呢,当然是用equals()了,这里也就明白了,为什么hashCode()和equals()方法要同时重写。【本文地址】