| 【计算机组成原理】一条指令的执行 | 您所在的位置:网站首页 › 指令的执行阶段需要多少个时钟周期 › 【计算机组成原理】一条指令的执行 |
【计算机组成原理】一条指令的执行
|
CPU的功能和基本结构
CPU由运算器和控制器组成,功能:指令控制、操作控制、时间控制、数据加工、中断处理 哪些硬件对程序员透明? 可见:通用寄存器、ACC、专用寄存器(PSW、PC)、基址寄存器 不可见:MAR、MDR、IR、暂存寄存器、微指令寄存器 控制器的三个主要部件:指令寄存器、程序计数器、操作控制器 指令执行过程指令周期 > 机器周期 > 时钟周期 周期不一定存在,如间址和中断,要满足条件(但存在就一定有内存存取操作) 完整的指令周期:取值(FE) ⇨ 间址(IND) ⇨ 执行(EX) ⇨ 中断(INT)。 无条件转移指令JMP,在执行时不需要访存,指令周期只包含取指阶段和执行阶段 具体过程(注:这是经典模型,但一般不考这个) 取指周期 任务:根据PC中的内容从主存中取出指令代码并存放在IR中; 是控制器固有的功能,不需要在操作码控制下自动完成; 指令字长=存储字长时,取指周期=机器周期 间址周期 任务:取操作数有效地址(当有效地址在寄存器内时不需要) 执行周期 任务:取操作数 步骤: ①根据地址去内存取出操作数;②运算,并放到目标地址的位置; 中断周期 任务:处理中断请求; 先修改栈顶指针,后存入数据; 检查中断信号,有中断才有这个周期(本质:断点存入某个存储单元) 指令执行方案 单指令周期 CPI = 1,不能用单总线结构; 指令周期取决于执行时间最长的指令的执行时间; 指令间串行执行; 多指令周期:串行执行,需要更多复杂对的硬件结构; 流水线方案:并行执行; 数据通路的功能和基本结构(CPU内部) 内部总线:同一部件,如CPU内部连接各寄存器和运算部件之间的总线; 外部总线:同一台计算机系统的各部件。 功能:控制信息的流动(通过MUX和三态门) 数据通路的基本结构: CPU内部单总线结构 一个时钟仅可传送一个数据 CPU内部三总线结构 一个时钟能传送多个数据 此时ALU可以不用暂存寄存器 专用数据通路方式 避免使用共享的总线,性能较高,但硬件量大 汇编(格式:OP 地址,地址) 解释:(地址)OP(地址)→地址(也就是说,→前面是数据类型,后面是地址类型) 结果存到目的操作数位置 控制器的功能和工作原理 硬布线控制器-RISC又称“组合逻辑控制器”(纯硬件) 输入 指令信息:指令经过译码产生 机器周期信号和节拍信号:时序系统产生 标志:执行单元的反馈信号 输出:一个机器周期内完成若干相容的微操作 控制方式 同步控制方式:统一的时钟信号 异步控制方式:没有统一的时钟信号,靠应答联络;快,但复杂 联合控制方式:大部分同步,小部分异步 设计步骤 ①分析操作序列,列出微操作命令的操作时间表 ②进行微操作信息综合:选择CPU控制方式:定长?节拍数?安排时序:哪个操作在哪个节拍 ③画出微操作命令的逻辑图:电路设计(先写出最简表达式) 特点:快,但复杂,改动困难 微程序控制器-CISC基本概念 指令 = 微程序 > 微指令 > 微操作 = 微命令 微周期:微指令的周期;一个微程序的周期对应一个指令周期 组成 微地址形成部件:由OP操作码形成初始微地址 顺序逻辑:根据CMDR下地址、标志和CLK生成微地址 微地址寄存器:CMAR / μPC 控制存储器CM 存放微程序,在CPU内部,由ROM实现 n条指令,至少n+1个微程序(公共的取指),可能还有公用的中断、间址(按题目描述) 除执行周期外的微指令序列通常公用 微指令寄存器:CMDR / μIR 微指令 格式 水平型:一条微指令定义多个相容的微命令(微指令长位数多,微程序短,快),充分利用并行 垂直型:一条微指令定义一个相容的微命令(微指令长位数少,微程序长,慢) 混合型:都有 编码方式/控制方式(水平型) 直接编码方式:每位0/1对应一个微命令,执行效率最高 字段直接编码方式:互斥性微命令放同一字段中;每一段要留出一个状态表示无命令 字段间接编码方式/隐式编码:用别的微命令来解释(两层译码) 地址形成方式 由下地址指出:断定方式 由操作码形成 增量计数器法:CMAR + 1 -> CMAR 分支转移:判别条件+转移地址 通过测试网络:顺序逻辑部件 设计步骤 分析微操作序列 写出对应微操作及节拍安排,注意每个微指令后特有的地址形成节拍 Ad(CMDR) -> CMAR OP(IR) -> 微地址形成部件 0 -> CMAR 确定微指令格式:操作码、下地址 编写微指令码点 其他 动态微程序设计:用EPROM 毫微程序设计:套娃 微程序控制器 硬布线控制器 工作原理 以微程序的形式存储在存储器 由组合逻辑电路即时产生 执行速度 慢 快 规则性 较规整 繁琐,不规整 应用场合 CISC RISC 易扩充性 易扩充修改 困难 异常和中断机制 基本概念实现多道程序、分时操作; 实现人机交互; 其具体处理过程由操作系统(和驱动程序)完成; 分类 异常/内中断 程序性中断/软中断 故障 Fault非法操作码、除0:终止进程 缺页、缺段:处理后回到断点继续执行 自陷/访管指令 Trap人为预先安排的一种“异常”事件,例:断点调试 要求操作系统服务时,如要求输入时 处理后返回到 下一条/[转移目标](自陷指令为转移指令时) 继续执行 自陷发生后CPU将进入操作系统内核程序执行; 硬故障中断 终止 Abort随机发生,不可恢复的致命错误造成的结果 断电、线路故障、存储器检验错、控制器出错 重启系统(非Abort引发的优先级很低) 中断/外中断分为可屏蔽中断和不可屏蔽中断 I/O中断外设请求CPU资源 注意:外设默认不等CPU处理完中断,连续工作 外部信号中断如Esc键 时钟中断修改与时间有关的所有信息 检测与响应 异常由CPU自己完成,不需要别人的信息; 由特定指令在执行过程中产生; 异常事件检测由CPU在执行每一条指令的过程中进行; 中断CPU需要通过总线获取中断源信息; 不和任何指令相关联,也不阻止任何指令的完成; 异常和中断响应过程关中断 保存断点和程序状态 识别异常和中断并转到相应的处理程序 异常:大多采用软件识别 软件识别:CPU设置一个异常状态寄存器 硬件:软件/硬件 硬件识别(向量中断) 异常或中断处理程序的首地址:中断向量 指令流水线同一时刻有多条指令在CPU的不同功能部件中并发执行,大大提高了功能部件的并行性和程序的执行效率。 基本概念可从两方面提高处理机的并行性 时间:流水线技术 空间:超标量处理机 指令集:RISC 表示方式 时空图:x时间 y阶段 流程图:x时间单元 y指令——分析影响因素(冲突) 装入时间和排出时间:第一个(最后一个)任务进入到输出的时间 分类 部件功能级(运算)、处理机级、处理机间 单功能(专门功能)、多功能 线性、非线性(有反馈) 性能指标 吞吐率 加速比:T(不用流水线) / T(用) 效率(设备利用率):时空图上的有效面积/总面积 基本实现五段式指令流水线(补充,重要) 特点 定长机器周期:取最长的那个 不用的阶段也消耗时间 过程 取指IF (Fetch):指令Cache 译码/读寄存器ID (Decode):寄存器,从寄存器堆中取操作数 执行/计算地址EX (Execute):ALU 访存M (Memory):数据Cache 写回WB (Writeback):寄存器,将指令写回寄存器堆中 指令类型 运算类指令:M阶段空段 Load(访存指令) ID阶段仅取出基址寄存器的值和偏移量 M阶段取出目的数到锁存器 WB阶段取出的数写回寄存器 Store(访存指令) ID阶段取出所有3个需要的数据 M阶段写回 WB阶段空段 条件转移:M段修改PC,WB空段——IF、ID、EX、M、WB 无条件转移:EX修改PC,M和WB空段——IF、ID、EX 常用相对寻址 (PC) + 指令字长 + (偏移量 * 指令字长) -> PCPC修改越早,越不容易控制冲突 结构冒险、数据冒险和控制冒险的处理 结构冒险(资源冲突)原因:有硬件资源竞争造成 解决——数据Cache、指令Cache分离 数据冲突原因:同步,多条指令重叠处理 前面的指令:写寄存器——WB,第五个段 后面的指令:读(同一个)寄存器——ID,第二个段; 分析思路: 一条一条指令从前往后分析,如果一条指令写了某个寄存器,则观察与之相邻的3条指令中,有没有哪条指令需要读同一个寄存器 当后面的指令和前面的指令中间,还有其他三条指令时,才不会发生数据冒险; 分类 写后读RAW:按序执行唯一可能遇到的 读后写WAR 写后写WAW 
解决 硬件阻塞(stall)、软件插入”NOP“(空指令) 数据旁路技术:设置专用通路 编译优化:调整指令顺序 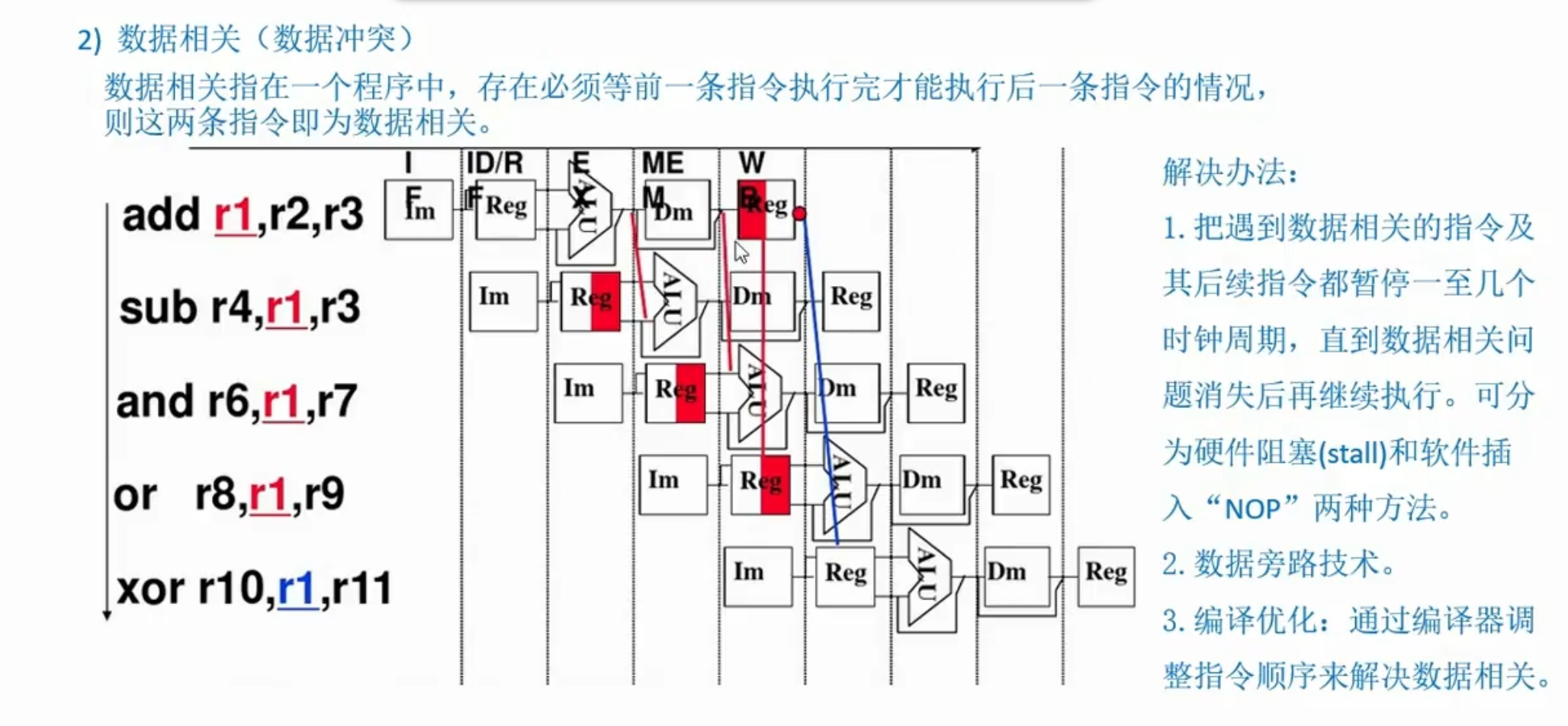 控制冲突
控制冲突
原因:转移(无条件转移call、ret,条件转移)、调用、返回会修改PC,造成断流 无条件转移 EX段修改PC; 解决方法:停两个周期,再取下一条指令(IF段),就不会发送控制冒险 条件转移 会先判断条件是否满足,在M段修改PC;在M段才可以确定是否需要转移; 解决方法:停三个周期,再取下一条指令(IF段),就不会发送控制冒险; 若未发生转移(不满足条件),则不会发生数据冒险; 解决 分支预测 静态预测:先默认默认yes,不是再退回 动态预测:根据历史情况 预取两个方向的目标指令 提前形成条件码 提高猜准率(对”分支预测“的优化)  考试:画流程图,分析阻塞原因和结果
考试:画流程图,分析阻塞原因和结果
数据相关 (RAW):后者的ID要等前者WB完 资源冲突(锁存器):前面被阻塞,后面的ID要等前面的ID结束才能开始 高级流水线技术 超标量(动态多发射)流水线技术原理 同时启动多条指令(多个功能部件),不能调整指令的执行顺序 任务:指令打包(推测+回退)和冒险处理 组成:指令预取、分派器、多个功能单元 特点 利用编译优化挖掘并行性 空间换时间 CPI = 1 超长指令字(静态多发射)技术由编译程序挖掘出指令间潜在的并行性,将多条能并行操作的指令合为一条(可达几百位) 超流水线技术原理:增加流水线级数(对应地缩短时钟周期),提高流水线主频 特点:CPI = 1,流水段越多,时钟周期越短,指令吞吐率越高 动态流水线把后面的挪到前面的空位 多种运算同时进行,模块利用率高 多处理器的基本概念 SISD、SIMD、MIMD、向量处理器的基本概念 单指令流单数据流结构——SISD特点:并发不能并行(就是普通的) 硬件:一处理器、一主存 不存在MISD(多指令处理单数据) 单指令流多数据流结构——SIMD特点: 多条数据做同一个操作(如显卡) 数据级并行技术 硬件: CU、主存仅一个,但执行单元多个 各执行单元有各自的寄存器组、局部寄存器、MAR 多指令流多数据流结构——MIMD特点 多指令多数据(如Intel i5多核处理器) 线程级并行、甚至以上 分类 多处理器系统(共享内存多处理器、多核处理器) 特点:可以用load访存同一个主存,通过主存交流 硬件:共享物理空间(同个主存) 多计算机系统 特点:只能通过”消息传递“交流 硬件:不共享物理空间(必须多个主存) 向量处理器(SIMD的变体)特点 数据对象是向量 删除并行计算、浮点数处理,常用于超算 硬件 多处理器、多向量寄存器 主存 主存采用”多端口同时读的“交叉多模块存储器 大容量、集中式 硬件多线程的基本概念 实现配备多个通用寄存器和PC, 线程切换时激活其中一个(省略了与存储器数据交换环节,大大减少了开销) 线程所需资源不冲突时,可以并行执行 细粒度多线程特点 多线程间指令不相关,可以乱序并发 每个时钟周期都切换线程 粗粒度多线程特点 引入流水线,线程切换开销大(清空整条流水线) 仅大开销阻塞时切换 同时多线程特点 指令发射槽并行 指令级并行 + 线程级并行(注:另俩仅有指令级并行) 多核处理器(Multi-core)的基本概念一个CPU有多个运算核心(处理器) 可以有各自Cache,也可以共享Cache 共享内存多处理器(SMP)的基M本概念和前者同一个东西,都是MIMD 具有共享的单一物理地址空间的多处理器 所有核共享主存和LLC(最低一级Cache) 统一存储访问多处理器——UMA每个处理器对所有存储单元的访问事件大致相同 非统一存储访问多处理器——NUMA某些访存请求要比其他快 NC-NUMA:不带高速缓冲 CC-NUMA:带有一致性高速缓冲 |
【本文地址】