| Unicode,Emoji和emoji | 您所在的位置:网站首页 › 怎样制作emoji表情符号 › Unicode,Emoji和emoji |
Unicode,Emoji和emoji
|
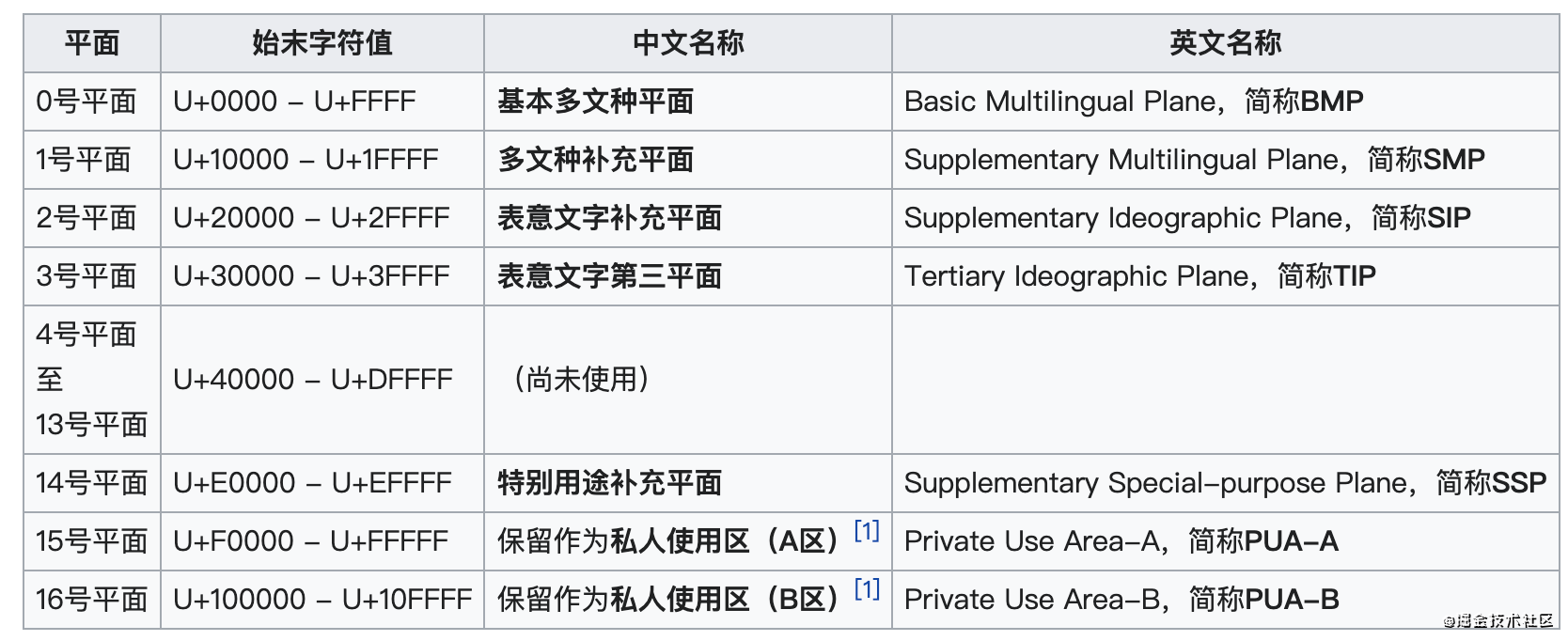
前些天在做一个翻译需求的时候,需要对全部是 emoji 表情的字符串不显示翻译按钮,虽然调用翻译接口后对 emoji 表情的翻译还是原来的 emoji 表情,并且我觉得这种效果更好,但是奈何 iOS 已经实现了这个功能,作为一个 Android 研发,已经习惯了向 iOS 低头,所以研究了一下,发现实现并没有想象的那么简单,要想做到完美需要极大的工作量,所以下面简单的对 Unicode,Emoji 以及一个处理 emoji 的 Java 开源库 emoji-java 进行简单的介绍整理,希望对你有所帮助。 Unicode之前在学校的时候,接触比较多的是 ASCII 码,ASCII 码使用一个字节(byte)表示一个字符,每一个字节有8位,所以最多能够表示28 = 256个字符,但是到现在为止才总共定义了128个字符,所以它真正用来表示字符的才有7位,通常第一位是0。ASCII 码用来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符。ASCII 码最多能够表示256个字符,这对二十六的大写字母和二十六个小写字母来说绰绰有余,但是对于我们博大精深的汉语以及其他的语言比如由汉语演化的日语韩语等来说,是远远不够的,所以需要一种新的编码方式和规范,Unicode因此而生。 Unicode,官方中文名称为统一码,也译名为万国码、国际码、单一码,是计算机科学领域的业界标准。它整理、编码了世界上大部分的文字系统,使得电脑可以用更为简单的方式来呈现和处理文字。在 Unicode 中,每一个字符都有其对应的编码,称为“码点”(code point)。表示一个Unicode的字符时,通常会写作“U+xxxxx”,其中 x 表示一组十六进制的数字。比如:U+4E25,U+1F600, U+1F601。 Unicode 将用途或意思相近的码点编排到同一组,称为平面(plane),而每个平面拥有65536(即216)个码点,目前 Unicode 共有17个平面但只使用了少数几个平面。
如果每个字符都能在 Unicode 中找到其对应的码点,那处理起来应该不会有太大的问题,但是在 Unicode 中存在“组合字”的概念,使用者可以通过组合多个码点,“拼”出一个完整的字,例如,Á 实际可以由U+0041(“A”)与U+0301 (“◌́” )组合而成。在不同的环境里,U+0301可能会展示成不同的样子,不过如果你的软件支持,它应该会很像是一个拼音二声的样子。 Emoij了解了 Unicode 之后,我们就可以来看看 Emoji 这种特殊的字符。 表情符号(英语:emoji,日语:絵文字/えもじ emoji),是使用在网页和聊天中的形意符号,最初是日本在无线通信中所使用的视觉情感符号(图画文字)。表情意指面部表情,图标则是图形标志的意思,可用来代表多种表情,如笑脸表示笑、蛋糕表示食物等。在中国香港除“表情图标”外,也有称作“绘文字”或“emoji”。在中国台湾 LINE 软件中,emoji又被叫做“表情贴”。在中国大陆,emoji通常直称“emoji”或称“表情符号”。 2010年10月发布的Unicode 6.0版首次收录emoji编码,其中582个emoji符号,66个已在其他位置编码,保留作相容用途的emoji符号。在Unicode 9.0 用22区块中共计1,126个字符表示emoji,其中1,085个是独立emoji字符,26个是用来显示旗帜的区域指示符号以及 12 个(#, * and 0-9)键帽符号。 当然,目前收录的这些 emoji 都有其唯一对应的码点,但是前面说过,Unicode 中存在“组合字”的概念,我们可以通过组合码点去“拼凑”出一个文字,显然 emoji 作为 Unicode 中的一份子也是支持这种特性的。 在 Unicode 中,可以使用U+200D零宽连字(ZWJ)将两个emoji连起来,使其看起来像是一个emoji。(不支持的系统会忽略零宽连字) 例如U+1F468男人、U+200D ZWJ、U+1F469女人、U+200D ZWJ、U+1F467女孩(👨👩👧)在系统支持的情况下会显示为一个男人一个女人和一个女孩组成的家庭emoji,而不支持的系统则会顺序显示这三个emoji(👨👩👧)。 除了不同 emoji 的组合,emoji 还支持肤色的控制。Unicode 8.0中加入了5个修饰符,用来调节人形表情的肤色。这些叫做emoji菲茨帕特里克修饰符(EMOJI MODIFIER FITZPATRICK)类型-1-2、-3、-4、-5和-6(U+1F3FB ~ U+1F3FF):🏻 🏼 🏽 🏾 🏿。对应了菲茨帕特里克度量对人类肤色的分类。没有后缀肤色代码的emoji会显示非真实的通用肤色例如亮黄色(█)、蓝色(█)或灰色(█)。非人形表情则不受修饰符影响。在Unicode 9.0中菲茨帕特里克修饰符可以和86个人形emoji一起使用。
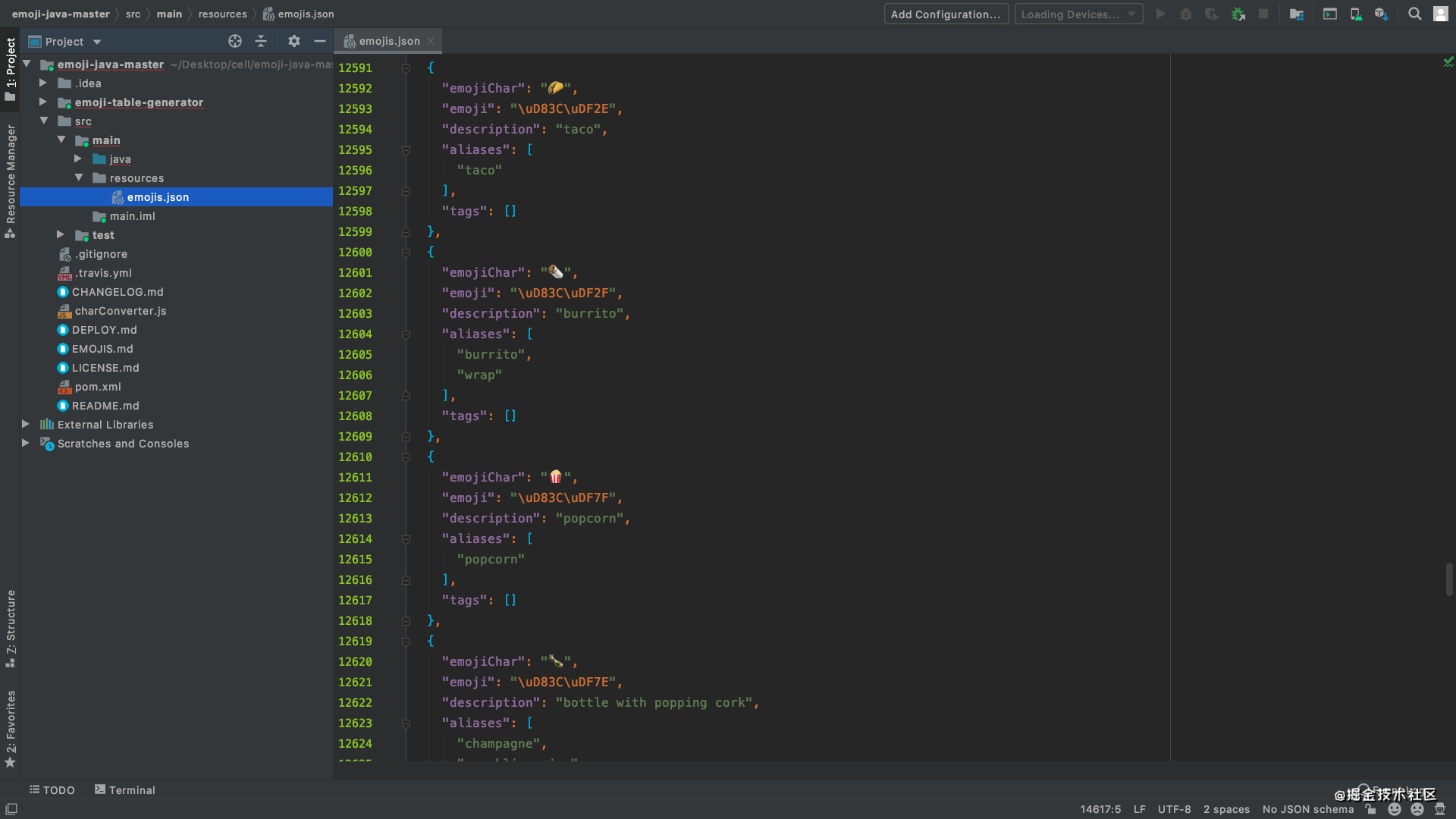
通过上面的了解,我们对 emoji 和 Unicode 有了一定的了解,但是当我们在项目中去处理 emoji 时,还是较为复杂的,一是因为 emoji 在 Unicode 中的码点较为分散,并没有集中在某一区域,如果需要尽可能正确的找出在字符串中的每一个 emoji ,需要较多的判断条件;二是因为 Unicode 能够进行组合,如果对单独字符的码点进行判断,容易出现漏盘错判的现象。 在开头说了,之所以研究这个问题是因为我在项目开发中有这个需求,第一时间我查找了很多的资料,但都无法进行完美的判断处理,总会有些 emoji 无法被识别,这些方法大都是对其码点值进行判断,所以出现遗漏也情有可原,毕竟 emoji 在 Unicode 中不是集中的。最终我找到了一个 Java 的开源库 —— emoji-java( Github 地址),他几乎可以识别和处理现有的所有 emoji,至于为什么它能够做到如此的全面准确,后面再说,先介绍一下它的主要用法。 1.添加依赖 Maven com.vdurmont emoji-java 5.1.1Gradle compile 'com.vdurmont:emoji-java:5.1.1'2.主要方法 getForTag //返回给定标签的所有表情符号 getForAlias //返回别名的表情符号 getAll //返回所有表情符号 isEmoji //检查字符串是否是表情符号 containsEmoji //检查字符串是否包含任何表情符号 getAllTags //返回可用的标签 getAll //返回所有表情符号示例: String str = "An 😀awesome 😃string with a few 😉emojis!"; Collection collection = new ArrayList(); collection.add(EmojiManager.getForAlias("wink")); // This is 😉 System.out.println(EmojiParser.removeAllEmojis(str)); System.out.println(EmojiParser.removeAllEmojisExcept(str, collection)); System.out.println(EmojiParser.removeEmojis(str, collection)); // Prints: // "An awesome string with a few emojis!" // "An awesome string with a few 😉emojis!" // "An 😀awesome 😃string with a few emojis!"了解了基本用法之后,我们来看看 emoji-java 的实现原理,实际上在 emoji-java 中有一个 json 文件,其中存储了目前所有的 emoji,如图。
它几乎包含了所有的emoji,包括进行组合的emoji,然后通过 EmojiLoader 类解析这个 json 文件转换为 Emoji 对象。 public static List loadEmojis(InputStream stream) throws IOException { JSONArray emojisJSON = new JSONArray(inputStreamToString(stream)); List emojis = new ArrayList(emojisJSON.length()); for (int i = 0; i emojis.add(emoji); } } return emojis; }Emoji 类的结构如下: public class Emoji { private final String description; private final boolean supportsFitzpatrick; private final List aliases; private final List tags; private final String unicode; private final String htmlDec; private final String htmlHex; }其所有的操作都是基于 emoji 类进行的,它还有一个叫做Fitzpatrick的枚举类,主要内容就是上面说的5个肤色的修饰符。 public enum Fitzpatrick { /** * Fitzpatrick modifier of type 1/2 (pale white/white) */ TYPE_1_2("\uD83C\uDFFB"), /** * Fitzpatrick modifier of type 3 (cream white) */ TYPE_3("\uD83C\uDFFC"), /** * Fitzpatrick modifier of type 4 (moderate brown) */ TYPE_4("\uD83C\uDFFD"), /** * Fitzpatrick modifier of type 5 (dark brown) */ TYPE_5("\uD83C\uDFFE"), /** * Fitzpatrick modifier of type 6 (black) */ TYPE_6("\uD83C\uDFFF"); }在进行字符串匹配时,它是通过树的形式进行匹配的,因为 emoji 是可以连接的,所以通过树的形式向下遍历可以组合出一个完整的emoji。 但是我觉得这个方法还是过于繁琐,如果有更好的方法欢迎大家进行补充。 参考: 从Unicode到emoji 维基百科 emoji-java |

【本文地址】