| 批量提取html文字,批量提取网页内容(全自动) | 您所在的位置:网站首页 › 怎么抓取网页文字 › 批量提取html文字,批量提取网页内容(全自动) |
批量提取html文字,批量提取网页内容(全自动)
|
默认记录上一次的xpath 方便多次提取 自动模式下 进入手动提取也会显示上次的xpath 标题就是要提取的纯文本 网址就是要提取的属性(自己看源码 要提取东西为等号后面的 直接就在xpath后面加@等号前面的单词 例如href=“网址” 就写成@href >< 里面的内容直接就用标题提取 看下面的例子) 简单的xpath提取教程: 发现问题的请反馈一下
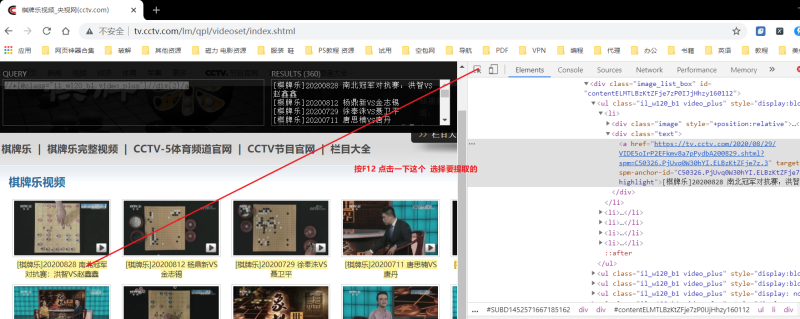
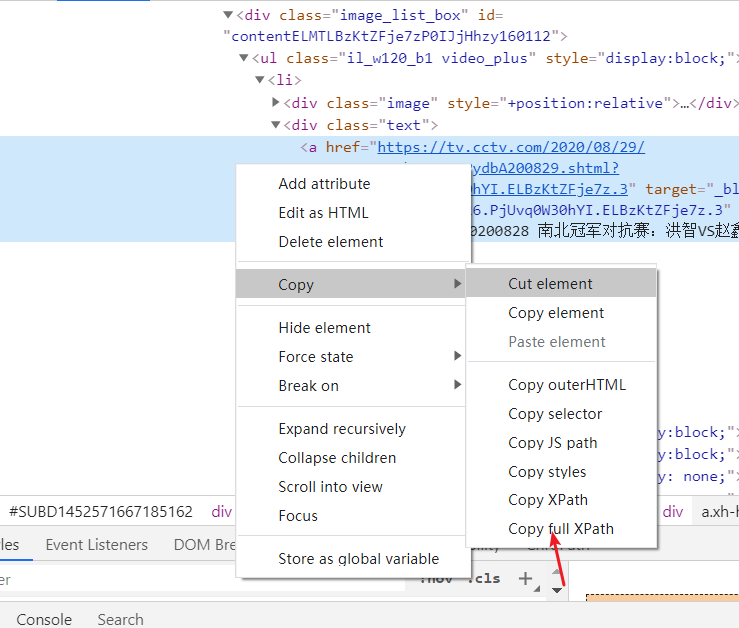
右键复制 复制第一个标题的xpath 再复制第二个标题的xpath
第一个标题:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]/ul[1]/li[1]/div[2]/a 第二个标题:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]/ul[1]/li[2]/div[2]/a 找前面相同的部分 相同的:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div |
【本文地址】
公司简介
联系我们