| 机器学习之 | 您所在的位置:网站首页 › 常数回归模型 › 机器学习之 |
机器学习之
|
一、Logistic回归介绍:
Logistic回归是一种常用的统计模型,被广泛应用于二分类问题的预测和分析中。它的主要目标是根据输入特征的线性组合来预测一个离散的输出变量。与线性回归不同,Logistic回归通过使用Sigmoid函数将线性函数的输出映射到0和1之间的概率值,从而实现对输出的概率预测。 Logistic回归在许多领域中都有应用,例如金融领域的信用评分,医学领域的疾病预测,市场营销中的用户分类,以及自然语言处理中的情感分析等。它的应用范围涵盖了数据挖掘、机器学习和统计分析等领域,并且由于其简单性和可解释性,它依然是许多实际问题中的首选模型之一。 总之,Logistic回归是一种适用于二分类问题的模型,通过使用Sigmoid函数进行预测,并在各种领域中发挥着重要作用。 二、假设与模型表达 1.假设Logistic回归模型假设因变量(输出变量)服从伯努利分布,即属于两个类别中的一个。同时,它假设自变量(输入特征)与因变量之间存在线性关系,并且这种关系可以用一个逻辑函数进行描述。 假设现在有一些数据点,我们利用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作为回归,如下图所示:
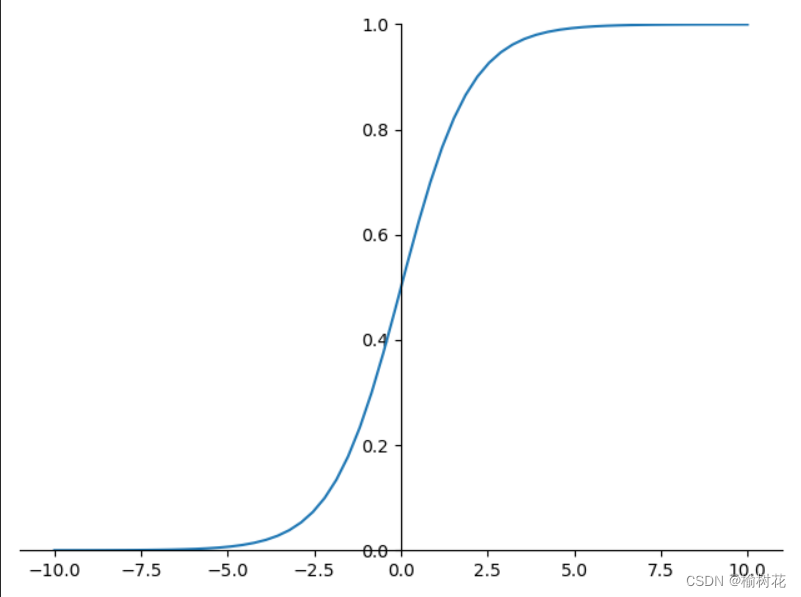
Logistic回归模型首先构建一个线性函数,其形式为: ( z = b_0 + b_1x_1 + b_2x_2 + ... + b_nx_n ) 其中,( z ) 表示线性组合的结果,( b_0 ) 是截距,( b_1, b_2, ..., b_n ) 是特征的系数,( x_1, x_2, ..., x_n ) 是输入特征。 3.Sigmoid函数什么是sigmoid函数? Sigmoid函数是一种常用的激活函数,它将输入的值映射到一个介于0和1之间的输出值。它的数学表达式如下: 其中,z是输入特征的线性组合,可以表示为 z=w0+w1x1+w2x2+...+wnxn,其中 w0,w1,w2,...,wn 是模型的参数,x1,x2,...,xn 是输入特征。 Sigmoid函数的特点是输出值在输入趋近正无穷大时逼近1,在输入趋近负无穷大时逼近0。这使得Sigmoid函数在二分类问题中被广泛应用,可以将模型输出的连续值转化为概率值,用于表示样本属于某个类别的概率。 由于Sigmoid函数的导数具有良好的性质,它在训练神经网络中的反向传播算法中被广泛使用。其导数的计算方式为 为什么要用到Sigmoid函数? 首先,我们处理二分类问题。由于分成两类,我们便让其中一类标签为0,另一类为1。我们需要一个函数,对于输入的每一组数据,都能映射成0~1之间的数。并且如果函数值大于0.5,就判定属于1,否则属于0。而且函数中需要待定参数,通过利用样本训练,使得这个参数能够对训练集中的数据有很准确的预测。 Sigmoid函数图像如下: 将线性函数的输出 ( z ) 经过Sigmoid函数 ( h(z) ) 处理后,得到的 ( h(z) ) 即代表了样本属于某一类别的概率。通常当 ( h(z) ) 大于0.5时,我们将样本预测为第一类(例如标签为1),当 ( h(z) ) 小于等于0.5时,我们将样本预测为第二类(例如标签为0)。 三、参数估计与损失函数:通常通过最大似然估计或梯度下降等方法来确定Logistic回归模型的参数。 1.最大似然估计最大似然函数(Maximum Likelihood Function)在Logistic回归中起着非常重要的作用,它可以帮助我们估计模型参数并进行分类预测。 在Logistic回归中,我们希望根据输入特征预测一个样本属于两个类别中的哪一个。假设有 n 个样本和 m 个特征,我们可以将样本的特征向量表示为 x1,x2,...,xn,对应的标签为 y1,y2,...,yn。其中,yi∈{0,1} 表示第i 个样本的类别。 Logistic回归模型的输出可以表示为: 其中,θ 表示模型的参数向量。 假设我们已经确定了模型的参数 θ,那么对于给定的输入特征 xi,模型预测为正例(yi=1)的概率为 P(yi=1∣xi),预测为反例(yi=0)的概率为 1−P(yi=1∣xi)。因此,对于整个样本集合,其似然函数可以表示为: 其中,yi∈{0,1} 表示第 �i 个样本的类别。 总之,最大似然估计是一种常用的参数估计方法,它通过找到能使观测数据出现的概率最大化的参数值来确定模型的参数。最大似然函数在Logistic回归中扮演重要的角色,它提供了一种基于概率的方法来估计模型参数,并帮助我们进行分类预测。 2.梯度下降梯度下降法是一种常用的优化算法,可用于求解Logistic回归中的最优参数。它的作用是通过迭代更新参数来最小化(或最大化)目标函数,从而找到最优的模型参数。 梯度下降法在Logistic回归中的实现过程: 初始化参数:首先,我们需要初始化模型的参数向量 θ。可以随机初始化或设置为0向量。 计算梯度:计算对数似然函数关于参数向量 θ 的梯度。梯度表示目标函数在当前参数值处的变化率,用于指导参数的更新方向。 参数更新:使用梯度以及学习率(步长)来更新参数。学习率决定了每次迭代中参数更新的幅度。常见的更新公式为: 数据集:
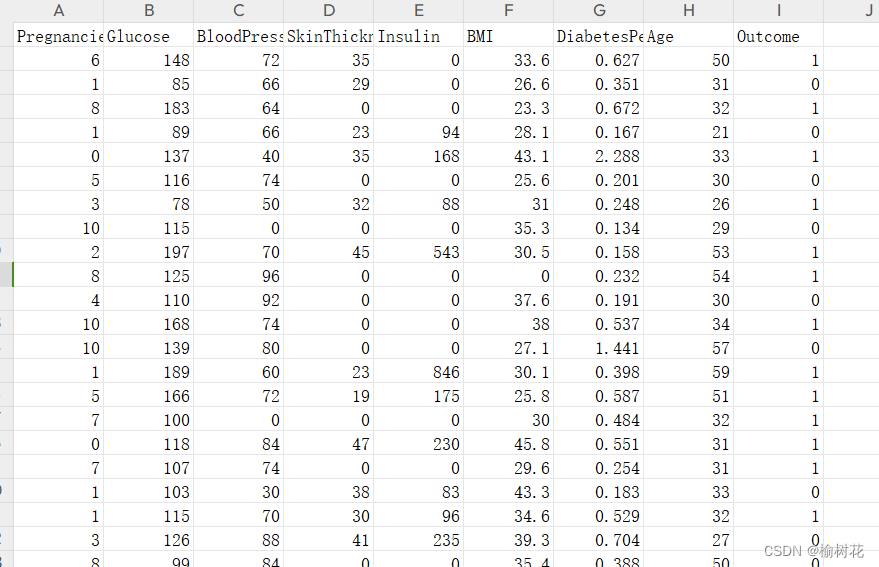
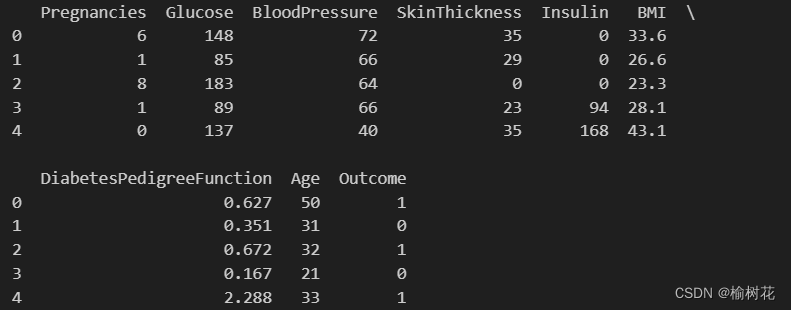
显示数据:
输出准确率与混淆矩阵:
模型准确率为0.824 五、logistic回归模型优缺点 优点:计算简单:逻辑回归模型只需要计算简单的线性加权和以及一个非线性激活函数,计算成本低。 可解释性强:逻辑回归模型可以提供每个特征的系数权重,使得模型的结果更具可解释性。 适用性广泛:逻辑回归模型可扩展到多类别分类问题,并且对于大规模数据集也适用。 不容易过拟合:逻辑回归模型在处理高维数据时,相对于其他算法会更加稳定,不容易出现过拟合的情况。 缺点:线性假设:逻辑回归模型基于线性假设,对于非线性的数据分类效果可能不如其他模型。 容易受到噪声影响:由于逻辑回归模型是基于概率进行分类的,因此如果输入特征中存在异常值或噪声,可能会导致模型效果下降。 需要独立特征:逻辑回归模型的输入特征需要尽可能独立,否则它们之间的相关性可能会导致结果偏差。 需要大量数据支持:逻辑回归模型需要足够的训练数据才能有效地学习特征权重,否则可能会导致欠拟合的情况。 |


【本文地址】