| 机器学习笔记:常用数据集之scikit | 您所在的位置:网站首页 › 在scikitlearn官网上下载股票数据 › 机器学习笔记:常用数据集之scikit |
机器学习笔记:常用数据集之scikit
|
目录 1. 前言 2. 来自真实世界的开源数据集 3. 函数接口 4. 使用代码示例 例1 kddcup99数据集 例2 20类新闻分类数据集 例3 带标签的人脸数据集 1. 前言机器学习算法是以数据为粮食的,所以机器学习开发的第一步就是数据的准备。数据预处理和特征工程是机器学习中不显眼(没有像算法开发那样亮丽)但是往往是涉及工作量最大的一部分。 对机器学习算法的学习和开发人员的一个福音是互联网上有很多开源的数据集,scikit-learn也内置了一部分简单的规模较小的数据(toy datasets,玩具数据集),并且为其它规模较大的数据集准备了相应的获取(下载)的API。这些数据集已经经过了适当的预处理,可以使得机器学习算法的学习和开发人员可以回避掉数据采集和处理的“吃力不讨好”的过程而聚焦于机器学习算法本身。 此外,scikit-learn还有自动生成面向各种机器学习问题的随机数据集的工具。这些随机生成的数据集虽然不是来源于实际测量,但是由于可以很简单地生成,而且其统计特征是受控的,所以对于机器学习的学习者或者机器学习算法的早期开发验证也是非常有用。 本系列简要介绍这几种数据集的生成、加载和/或获取方式,以及相应的基于scikit-learn的处理方法。 本文作为本系列的第二篇,介绍scikit-learn提供了接口函数可在线下载的开源数据集。 2. 来自真实世界的开源数据集有很多来自真实世界的开源数据集,虽然(由于比如说数据集大小或者版权等原因)没有直接集成到scikit-learn中,但是scikit-learn也提供了相应的获取(从各数据集的网络链接上下载)的API接口。这些API函数的统一以fetch_开头。 以下给出一些数据下载的示例代码,但是不对各用到的函数的参数进行具体描述,需要使用时可以自行查阅scikit-learn文档。详细参见: 7.2. Real world datasets — scikit-learn 1.0.1 documentation 老规矩,借用Pandas DataFrame和Jupyter Notebook的渲染生成这些开源数据集的列表如下: dataset = pd.DataFrame() dataset['数据集名称'] = ['Olivetti脸部图像数据集','kddcup99数据集','20类新闻分类数据集(文本)','20类新闻分类数据集(特征向量)','带标签的人脸数据集1','带标签的人脸数据集2','路透社新闻语料数据集','加州住房数据集','森林植被覆盖数据集','物种分布数据集'] dataset['模型类型'] = ['降维','分类','分类','分类','分类','分类','多分类','回归','多分类','分类'] dataset['数据大小(样本数*特征数)'] = ['400*64*64','???','18846*1','18846*130107','13233*5828','???','804414*47236','20460*8','581012*54','???'] dataset['API接口'] = ['fetch_olivetti_faces','fetch_kddcup99','fetch_20newsgroups','fetch_20newsgroups_vectorized','fetch_lfw_people','fetch_lfw_pairs','fetch_rcv1','fetch_california_housing','fetch_covtype','fetch_species_distributions'] dataset
(1) fetch_olivetti_faces(data_home=None, shuffle=False, random_state=0, download_if_missing=True, return_X_y=False) (2) fetch_20newsgroups(*, data_home=None, subset='train', categories=None, shuffle=True, random_state=42, remove=(), download_if_missing=True, return_X_y=False)'] (3) fetch_20newsgroups_vectorized(*, subset='train', remove=(), data_home=None, download_if_missing=True, return_X_y=False, normalize=True, as_frame=False) (4) fetch_lfw_people(*, data_home=None, funneled=True, resize=0.5, min_faces_per_person=0, color=False, slice_=(slice(70, 195, None), slice(78, 172, None)), download_if_missing=True, return_X_y=False) (5) fetch_lfw_pairs(*, subset='train', data_home=None, funneled=True, resize=0.5, color=False, slice_=(slice(70, 195, None), slice(78, 172, None)), download_if_missing=True) (6) sklearn.datasets.fetch_covtype(*, data_home=None, download_if_missing=True, random_state=None, shuffle=False, return_X_y=False, as_frame=False) (7) fetch_rcv1(*, data_home=None, subset='all', download_if_missing=True, random_state=None, shuffle=False, return_X_y=False) (8) fetch_kddcup99(*, subset=None, data_home=None, shuffle=False, random_state=None, percent10=True, download_if_missing=True, return_X_y=False, as_frame=False) (9) fetch_california_housing(*, data_home=None, download_if_missing=True, return_X_y=False, as_frame=False) 以下仅对一些公共的参数进行简要说明(需要进一步的详细信息请参考scikit-learn在线文档): data_home(str): 指定下载后数据存放目录路径。如果没有指定的话,缺省地存放地可以通过调用get_data_home()函数获取。通常Windows下是'C:/Users/Username/scikit_learn_data',而Linux系统下就是'~/scikit_learn_data'. download_if_missing(bool): fetch_xyz()函数被调用时,首先会去缺省的数据存放目录搜索,找到了就直接用。没有找到的话,如果本参数设置为True就下载,False的话就报告错误。 return_X_y(bool), 返回Bunch Object,还是返回(data.data, data.target). as_frame(bool), 返回的数据是不是变换为pandas DataFrame格式 shuffle(bool), 是否将数据进行shuffling(顺序打乱)处理。shuffling处理在数据使用时做也可以random_state(bool), 是否设置随机种子,缺省为None表示每次调用会得到不同的结果,如果希望得到相同的结果就设置为某个固定的整数即可。在shuffling处理,或者其它涉及到随机选择的处理中需要随机种子. 还有一些各数据集fetch函数特定的选项,这里不一一说明。用到时可以查找"https://scikit-learn.org/stable/datasets/real_world.html". 在以下示例中也会对碰到的做一些简要说明。 4. 使用代码示例 例1 kddcup99数据集以下命令下载kddcup99数据集的SA子集,并且只下载其中的10%。返回的数据分为数据样本X和标签y,并且都是以Pandas DataFrame格式返回。 from sklearn.datasets import fetch_kddcup99 X,y = fetch_kddcup99(subset='SA',percent10=True,return_X_y=True,as_frame=True) print(X.shape, y.shape) print(type(X), type(y.shape)) print('There are {} classes in this dataset'.format(len(set(y)))) X (100655, 41) (100655,) There are 13 classes in this dataset
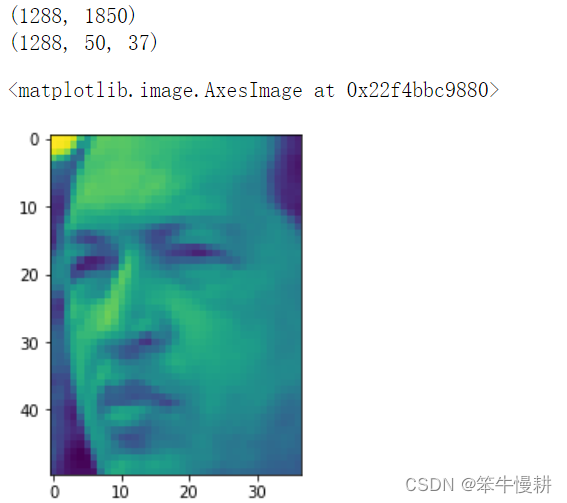
“fetch_20newsgroups_vectorized”与“fetch_20newsgroups”的区别在于前者在后者的基础上进一步进行向量化的处理,所以前者的数据维度要远远大得多。 from sklearn.datasets import fetch_20newsgroups newsgroups_train = fetch_20newsgroups(subset='train') from pprint import pprint pprint(list(newsgroups_train.target_names)) ['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x',...... print(newsgroups_train.filenames.shape) print(newsgroups_train.filenames[:5]) print(type(newsgroups_train.data),len(newsgroups_train.data)) print(newsgroups_train.data[0]) print(newsgroups_train.target.shape) print(newsgroups_train.target[:10]) (11314,) ['C:\\Users\\chenxy\\scikit_learn_data\\20news_home\\20news-bydate-train\\rec.autos\\102994',...] 11314 From: [email protected] (where's my thing) Subject: WHAT car is this!? Nntp-Posting-Host: rac3.wam.umd.edu Organization: University of Maryland, College Park Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw ...... have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ---- (11314,) [ 7 4 4 1 14 16 13 3 2 4]20newsgroups数据集有20个分类,可以在下载时选择只取其中一部分分类的样本,这个通过设置fetch_20newsgroups的'categories'参数来控制。 cats = ['alt.atheism', 'sci.space'] newsgroups_train = fetch_20newsgroups(subset='train', categories=cats) print(list(newsgroups_train.target_names)) print(len(newsgroups_train.data)) print(newsgroups_train.target.shape) ['alt.atheism', 'sci.space'] 1073 (1073,)为了方便统计分析,以文本方式出现的数据样本首先必须转换成数值向量的表示形式,这个可以通过sklearn.feature_extraction.text中工具来实现,以下例子从20newsgroups数据集的子集中提取出一元分词令牌的TF-IDF向量(TF-IDF vectors of unigram tokens)。 所提取的TF-IDF向量是非常稀疏的,如下例所示: vectors are very sparse, with an average of 159 non-zero components by sample in a more than 30000-dimensional space (less than .5% non-zero features): from sklearn.feature_extraction.text import TfidfVectorizer categories = ['alt.atheism', 'talk.religion.misc','comp.graphics', 'sci.space'] newsgroups_train = fetch_20newsgroups(subset='train',categories=categories) vectorizer = TfidfVectorizer() vectors = vectorizer.fit_transform(newsgroups_train.data) print(vectors.shape) print(vectors.nnz / float(vectors.shape[0])) (2034, 34118) 159.0132743362832后面这个结果159表示,平均每个样本的34118维向量中只有159个非零元素,即非零元素比例不到千分之五,名副其实的稀疏向量。 当然,上面这个向量化处理其实也不必自己手动地去做,因为scikit-learn提供了另外一个自动进行向量化处理的接口函数fetch_20newsgroups_vectorized(),如下所示: from sklearn.datasets import fetch_20newsgroups_vectorized newsgroups_train = fetch_20newsgroups_vectorized(subset='train') print(newsgroups_train.data.shape) print(newsgroups_train.data.nnz) (11314, 130107) 1787565与前面第一次调用newsgroups_train = fetch_20newsgroups(subset='train')的结果做对比,可以看出fetch_20newsgroups返回的数据newsgroups_train.data是一个列表,列表中每一项就是一个很长的字符串,表示一个语料样本。而fetch_20newsgroups_vectorized返回的是一个矩阵,其中每一行对应一个语料样本,只不过被变换成一个130107维的向量罢了。 例3 带标签的人脸数据集要注意带标签的人脸数据集1(fetch_lfw_people())与带标签的人脸数据集2(fetch_lfw_pairs())的区别。 前者是用于人脸识别( Face Recognition or Face Identification)任务的,给定一张照片,识别出TA是谁(对应于已经学习好的数据库中的哪个人,比如说匹配出其名字);后者是用于人脸验证(Face Verification)任务的,给定两张照片,确定它们是不是同一个人的照片之类的。 from sklearn.datasets import fetch_lfw_people lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4) # 对每个人至少取70张图片 for name in lfw_people.target_names: print(name) Ariel Sharon Colin Powell Donald Rumsfeld...与手写数字数据集一样,这个数据集由于是关于人脸的,所以既有一维向量表示的数据样本(lfw_people.data),也有二维图像表示的数据样本,可以用imshow()来显式对应的样本图片。 print(lfw_people.data.shape) print(lfw_people.images.shape) imshow(lfw_people.images[0])
上一篇:机器学习笔记:常用数据集之scikit-learn内置玩具数据集 下一篇:机器学习笔记:常用数据集之scikit-learn生成分类和聚类数据集 |


【本文地址】