| 哈工大计算机网络实验一:HTTP代理服务器(Java语言实现) | 您所在的位置:网站首页 › 哈工大威海ftp › 哈工大计算机网络实验一:HTTP代理服务器(Java语言实现) |
哈工大计算机网络实验一:HTTP代理服务器(Java语言实现)
|
目录
1 总体思路1.1 基本理论简述1.2 具体实现的思路1.3 环境及项目结构
2 主函数部分(ProxyServer)2.1 主循环2.1.1 读取并解析http请求首部2.1.2 网页钓鱼的实现2.1.3 网站过滤的实现2.1.4 过滤用户的实现2.1.5 代理服务器真正开始处理报文收发
3 传数线程(ProxyThread)4 带缓存机制的传输线程4.1 参数作用4.2 run()重写(缓存实现)4.2.1 判断是否缓存命中4.2.2 命中情况4.2.3 不命中情况
末尾
1 总体思路
1.1 基本理论简述
虽然无论如何代理服务器都会收到请求后再向目标服务器发送请求,但是如果缓存内容仍然是最新的话,目的服务器返回的确认消息很小,也不会耽误时间。 所以缓存机制还大大提高了效率。 注:这里并未给出代理服务器向目标服务器发送带有“if-modified-since”字段的请求,原因是发生了我没有解决的错误。o(╥﹏╥)o 1.2 具体实现的思路事实上,我们在浏览器地址栏上输入我们想访问的网址,到浏览器展示给我们丰富的页面,即使我们只访问一次,浏览器还是会发送许许多多的请求。 浏览器首先向服务器请求的是一个网页的骨架(html文件),然后逐渐发现“骨架”中的引用(视频,图片,其他文件等)需要再次请求。。。
那么很容易想到一个死循环( while(true){…} )在每轮循环,我们都只处理来自浏览器的一个请求。循环体中,我们对请求报文做一些解析用来提取一些必要的信息,然后建立与目标服务器的连接后,监听浏览器到服务器的数据传送,同时监听服务器到浏览器的数据传送。 下图就是程序的简要流程,不难看出,一实三虚,即为一次循环。 浏览器 代理服务器 目标服务器 第 1 个请求 相应的处理(有/无) 监听 监听 第 2 个请求 相应的处理(有/无) 监听 监听 第 3 个请求 相应的处理(有/无) 监听 监听 ....... 第 n 个请求 浏览器 代理服务器 目标服务器在Java中socket网络编程,慕课里也讲过,socket是点对点的,代理服务器程序在一次循环中,分别与浏览器客户端,目标服务器维持一个socket连接,那么数据流就可以在这条通路上传输。 整体思路就明朗起来了。 1.3 环境及项目结构我是使用idea创建了一个maven项目(但没有引入依赖,也不用打包成jar文件,所以其实空项目也行),创建maven项目点红箭头那里。 下面是我的项目结构:
在看之前最好对java中io流有基本的了解:吃透javaIO,这里,报文交换是由数据流的传输IO操作实现的。 resources目录下是我的两个返回页面,用于表示网站/用户过滤。 2 主函数部分(ProxyServer) public class ProxyServer { public static void main(String[] args) { System.out.println("是否过滤本地ip?(1:是/2:否)"); boolean enable=false; int choice= new Scanner(System.in).nextInt(); if(choice==1)enable=true;//这里是为了实现过滤ip设置的,我这里将本机ip作为被过滤的ip ServerSocket serverSocket = null; try { serverSocket = new ServerSocket(8080);//主套接字,用来监听 } catch (IOException e) { e.printStackTrace(); } int index=0;在进入大循环体之前,由于我将本机地址作为过滤对象,故在开头设置判断逻辑。 并且先设置主套接字,来接听客户端的连接请求,它在每次循环的开头,都要监听浏览器的一个请求,创建一个子套接字。 2.1 主循环 while (true) { index++;//index用于唯一标识每一次请求 System.out.println(index); try { Socket socket = serverSocket.accept();//这里得到了与浏览器相连的子套接字 OutputStream output = socket.getOutputStream(); InputStream in = socket.getInputStream(); socket.setSoTimeout(1000 * 60);//超过该时间,socket自动关闭 StringBuilder requestText = new StringBuilder();//之后要发给服务器的http请求报文 String line = ""; BufferedReader input = new BufferedReader(new InputStreamReader(in)); int temp = 1;//获取请求方法时,要用到,因为请求方法在报文第一行 String type = "", host = "",URL="";//所思即所得 int port = 80; String endAddress="";我们在正式解析http请求报文之前,要做以上准备工作,包括与浏览器端socket的创建,变量的赋值等。 接下来,我们就能逐行“阅读”请求报文的内容了↓(这里我只读取了请求头部信息,用来获取目的主机地址,端口号,以及请求路径。 2.1.1 读取并解析http请求首部 while ((line = input.readLine()) != null) {//逐行处理该次请求报文的文本内容 System.out.println(line); if (temp == 1) { type = line.split(" ")[0]; URL=line.split(" ")[1]; } if (type == null || type.equals("")) continue;//获取请求方法 if(line.isEmpty())break;//遇到空行,代表首部结束 String[] s1=line.split(": "); for(int i=0;i//发现对4399的请求,直接将报文改成下面的,完成“引导” endAddress="www.hit.edu.cn"; requestText= new StringBuilder("GET http://www.hit.edu.cn/ HTTP/1.1\n"+ "Host: www.hit.edu.cn\n" + "Proxy-Connection: keep-alive\n" + "Upgrade-Insecure-Requests: 1\n" + "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.53\n" + "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\n" + "Accept-Encoding: gzip, deflate\n" + "Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6\n"); } 2.1.3 网站过滤的实现不难发现,我们只要获知了此次请求的首部信息,过滤就很简单了 if (endAddress.split(":").length > 1) {//代表包含端口号 port = Integer.valueOf(endAddress.split(":")[1]); } host = endAddress.split(":")[0];//获取目的主机号和端口号 requestText.append("\n");//表示一个请求报文的结束,否则服务器不知道 if(endAddress.contains("www.baidu.com")){//将百度作为过滤对象 requestText=new StringBuilder(); BufferedInputStream fileInput=new BufferedInputStream(new FileInputStream("D:\\JAVA\\HIT_network_lab1\\src\\main\\resources\\error.html")); int length=-1; byte[] bytes=new byte[1024]; while((length=fileInput.read(bytes))!=-1){ output.write(bytes,0,length); } output.flush(); }只要看端地址是否是对应过滤网站的端地址,进行字符串匹配就行。这里我返回一个html页面。 2.1.4 过滤用户的实现 if(enable&&socket.getInetAddress().getHostAddress().equals("192.168.124.1")){ requestText=new StringBuilder(); BufferedInputStream fileInput=new BufferedInputStream(new FileInputStream("D:\\JAVA\\HIT_network_lab1\\src\\main\\resources\\error2.html")); int length=-1; byte[] bytes=new byte[1024]; while((length=fileInput.read(bytes))!=-1){ output.write(bytes,0,length); } output.flush(); }用户过滤也是同样的思路 2.1.5 代理服务器真正开始处理报文收发程序大部分时间是运行这一部分的。 if (host != null && !host.equals("")) { Socket proxySocket = new Socket(host, port);//与服务器的socket OutputStream proxyOut = proxySocket.getOutputStream(); InputStream proxyIn = proxySocket.getInputStream(); proxySocket.setSoTimeout(60 * 1000);//超过该时间,socket自动关闭 if (type.equals("CONNECT")) { output.write("HTTP/1.1 200 Connection Established\r\n\r\n".getBytes()); output.flush(); } else {//如果是http请求则直接转发报文 proxyOut.write(requestText.toString().getBytes("utf-8")); proxyOut.flush(); } new ProxyThread(in, proxyOut).start();//监听客户端发送給服务器的数据 if(type.equals("GET")){//由于connect请求过多,我只缓存了get请求的对象。 new ProxyThreadWithCache(proxyIn,output,URL,index).start();//如果是get请求,则先看是否有缓存,没有则请求并缓存,有则直接返回 }else{ new ProxyThread(proxyIn,output).start(); } } }catch(IOException e){ e.printStackTrace(); } } } }到这里可以发现,java网络传输其实是socket在传送字节流。 而且到这里,才终于创建了与目标服务器的socket。 这里,可以解释为什么当请求方法是connect时要这样操作。如果不是connect,而是get,那么世界将我们之前准备的请求报文,一字节不落地传给目的服务器。 然后,我们就要开启两个线程来传递数据: 该实现类除了输入流和输出流两个属性,就是重写run(),完成将输入的数据输出。 @Override public void run() { try { while (true) { BufferedInputStream bis = new BufferedInputStream(input); byte[] buffer =new byte[1024]; int length=-1; while((length=bis.read(buffer))!=-1) { output.write(buffer, 0, length); } output.flush(); try { Thread.sleep(10); //避免此线程独占cpu } catch (InterruptedException e) { e.printStackTrace(); } } }这种先将数据读入字节数组,再读出几乎是流到流传输的标准写法了。 然后是一些异常捕获处理 catch (SocketTimeoutException e) { try { input.close(); output.close(); } catch (IOException e1) { System.out.println(e1); } }catch (IOException e) { System.out.println(e); }finally { try { input.close(); output.close(); } catch (IOException e) { e.printStackTrace(); } } } } 4 带缓存机制的传输线程 4.1 参数作用 public class ProxyThreadWithCache extends Thread{ //这个线程负责代理服务器向客户端返回数据,如果有缓存,直接将缓存数据返回,如果没有就将服务器传来的数据发送给客户端,同时缓存(这很不对) InputStream input; OutputStream output; String URL; int index; public ProxyThreadWithCache(InputStream input,OutputStream output,String URL,int index){ this.input=input; this.output=output; this.URL=URL; this.index=index; } 属性名作用input字节输入流output字节输出流URL需要该变量来确定是否命中index把请求序号拿来,我这里用户缓存文件命名 4.2 run()重写(缓存实现) 4.2.1 判断是否缓存命中 @Override public void run(){ try { boolean hasFile=false; String name=index+".txt"; File file=new File("D:\\JAVA\\HIT_network_lab1\\src\\main\\Cache"+"\\"+name); File directory=new File("D:\\JAVA\\HIT_network_lab1\\src\\main\\Cache"); for(File file0:directory.listFiles()){ BufferedReader fileReader=new BufferedReader(new InputStreamReader(new FileInputStream(file0))); if(fileReader.readLine().equals(URL)){ hasFile=true; file=file0; } }//判断是否有相应缓存需要说明的是,缓存对象时,我是将相应的URL放在文件第一行用来标识这是哪一个请求对应的响应对象。 所以这里判断缓存是否命中,也就是遍历缓存目录,读取第一行,如果url匹配则命中,并拿到文件。否则不命中。 4.2.2 命中情况 if(hasFile){//如果缓存存在,则直接将缓存返回给客户端 System.out.println(URL+"路径对应的请求对象缓存命中"); BufferedInputStream inputStream=new BufferedInputStream(new FileInputStream(file)); String pad=URL+"\r\n"; inputStream.read(pad.getBytes()); while(true){ int length=-1; byte[] bytes=new byte[1024]; while((length=inputStream.read(bytes))!=-1){ output.write(bytes,0,length); } output.flush(); try{ Thread.sleep(10); }catch(InterruptedException e){ e.printStackTrace(); } } }直接将拿到的缓存文件返回给客户端。 4.2.3 不命中情况 else{//如果缓存不存在,则将服务器传来的数据传给客户端并且缓存 System.out.println(URL+"路径对应的请求对象缓存未命中"); System.out.println(1); FileOutputStream outputStream=new FileOutputStream(file); String pad=URL+"\r\n"; outputStream.write(pad.getBytes("utf-8"));//将URL作为缓存文件的第一行 while(true){ BufferedInputStream inputStream=new BufferedInputStream(input); int length=-1; byte[] bytes=new byte[1024]; while((length=inputStream.read(bytes))!=-1){ outputStream.write(bytes,0,length); output.write(bytes,0,length); } output.flush(); outputStream.flush(); try{ Thread.sleep(10); }catch(InterruptedException e){ e.printStackTrace(); } } }不命中的话,既要将数据输送给浏览器相连的socket,并且还要缓存在文件中。 并且我还将url写入缓存文件第一行,作为缓存文件与请求的对应。 catch (IOException e) { System.out.println(e); }finally { try { input.close(); output.close(); } catch (IOException e) { e.printStackTrace(); } }及时关闭流,避免资源浪费。 末尾这样的缓存机制是有问题的,因为缓存在本地的对象可能out了,这样代理服务器其实应该向远程服务器请求以确认对象是否最近更新。 我在4.2.2之前加上了一段代码,用来实现这一机制: if(hasFile) { /**********************************/ BufferedReader fileReader = new BufferedReader(new InputStreamReader(new FileInputStream(file))); String line = null, Date = "", newDate = ""; while ((line = fileReader.readLine()) != null) { String[] s = line.split(": "); for (int i = 0; i String[] s = line.split(": "); for (int i = 0; i file.delete(); hasFile = false; } else hasFile = true; /**********************************/ }但好像有些问题,我去掉了,暂时没有继续研究。 当然我的代码很乱,代码重复严重。并且性能一般,希望能提供一些思路,敬请指教。 |
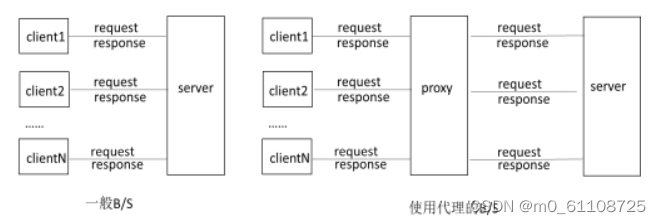 代理服务器作为原客户端(浏览器)与目的服务器的中间代理,主要的功能有:1:接受并解析浏览器发来的请求;2:如果缓存中存在请求对应的响应对象,则向目的服务器“询问”目的对象的最新更新时间,并以此来判断缓存中的对象是否过时;3:如果“过时”,则正常向服务器请求最新对象并缓存。否则可以直接将缓存中的数据返回。
代理服务器作为原客户端(浏览器)与目的服务器的中间代理,主要的功能有:1:接受并解析浏览器发来的请求;2:如果缓存中存在请求对应的响应对象,则向目的服务器“询问”目的对象的最新更新时间,并以此来判断缓存中的对象是否过时;3:如果“过时”,则正常向服务器请求最新对象并缓存。否则可以直接将缓存中的数据返回。
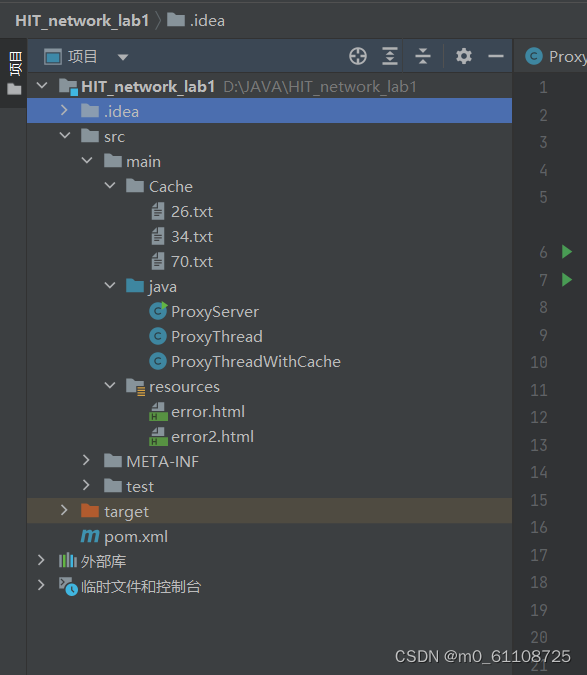 其中,Cache目录保存http响应对象作为缓存(选做2用的),一个文件对应一个请求对象。 java目录下,ProxyServer类是主类,包含着main方法。 ProxyThread类是线程类的子类(一个特定功能的线程),主要是将数据从输入流传到输出流。 ProxyThread类也是线程类的子类,顾名思义,除了将数据从输入传到输出,还有缓存的响应功能。其具体细节会在下文讲述。
其中,Cache目录保存http响应对象作为缓存(选做2用的),一个文件对应一个请求对象。 java目录下,ProxyServer类是主类,包含着main方法。 ProxyThread类是线程类的子类(一个特定功能的线程),主要是将数据从输入流传到输出流。 ProxyThread类也是线程类的子类,顾名思义,除了将数据从输入传到输出,还有缓存的响应功能。其具体细节会在下文讲述。 一次循环,也就是一个请求的处理,结束了。
一次循环,也就是一个请求的处理,结束了。【本文地址】