| 生物统计学常用统计分析方法系列文章之十二:协方差分析(Analysis of Covariance,ANCOVA) | 您所在的位置:网站首页 › 可比性例子 › 生物统计学常用统计分析方法系列文章之十二:协方差分析(Analysis of Covariance,ANCOVA) |
生物统计学常用统计分析方法系列文章之十二:协方差分析(Analysis of Covariance,ANCOVA)
|
前边介绍了单因素方差分析、两因素方差分析、重复测量方差分析等,方差分析可谓其经典分析方法。而下边介绍的协方差分析也是方差分析的一种特殊类型,而它一大优势便是可以提高均值比较的精度,而它是怎么做到的呢? 所谓协方差分析(Analysis of Covariance,ANCOVA)就是在对两组或多组的均值进行比较时,对其他可能影响到反应值的某些连续性变量进行了调整,这些变量就叫做协变量(covariate)。在这里需要说明的是ANCOVA限定用于反应值和协变量可能存在线性关系的情况下。因此从这个意义上来说,ANCOVA其实是方差分析和简单线性相关的一个结合。理解了ANCOVA的概念,我们便可以看出把协变量纳入模型,作为变异来源的一部分,便可以降低误差项变异,从而提高了组间比较的精度。 ANCOVA是临床试验中应用最广泛的统计分析方法之一,比如: 1)在很多主要疗效变量为change from baseline的试验中,往往对baseline值进行调整 2)一些降血脂试验中,对年龄进行调整,等等 如果某个重要变量在各组间分布不同,ANCOVA显得尤为有用。我们在临床试验的统计分析中,往往要对病人的基线特征如年龄、基线数据等进行可比性的分析,如果基线变量在治疗组间不均衡时,这时我们在进行疗效分析时就需要对其进行调整。这时把这个变量当作协变量加以调整后的统计分析即ANCOVA的结果可能与未使用未调整的方差分析ANOVA的结果有明显的不同。 这里简单介绍一下协方差分析的思路。以最简单的ANCOVA模型为例,先看一下数据结构: 治疗组1:(X为协变量,Y为反应值,样本量为n1) 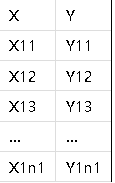 治疗组2:(X为协变量,Y为反应值,样本量为n2)  治疗组K:(X为协变量,Y为反应值,样本量为nk)  和ANOVA一样,ANCOVA假定样本独立,正态分布和方差齐性。另外还假定每组的回归斜率(regression slopes)是一样的。 然后我们来看一下ANCOA的一个简单的总结表:  如上表,大家可以看出与线性回归的方差分析模型相比,增加了GROUP效应,并且仍把X与Y的线性关系用模型中的协变量X来表达,然后通过GROUP的F值和协变量X的F值来分别检验GROUP效应和协变量效应。 这里结合一个简单的例子来进一步了解ANCOVA。 例1:一项比较A药和B药的临床试验中,已知主要疗效指标为Y (percent change from baseline),而基线某因素X可能对疗效Y有重要影响。主要数据如下表:  1. 对协变量X进行调整进行ANCOVA分析后的结果的总结如下表:  注:两个F值都是有统计学意义的,p0.05。 从上表我们得出的结论是两组疗效没有统计学差别。 同样的数据,采用不同的统计分析方法,一个是不调整协变量的ANOVA分析,另一个是对协变量进行调整的ANCOVA分析,最后的结论却截然相反,为什么会造成这种结果呢? 在同一个例子的数据中使用了ANCOVA和ANOVA分析,结果却截然相反。ANCOVA分析中治疗组间有显著性差别,而ANOVA分析则表明治疗组间没有显著性差别。为什么呢?也许有的同学可以一语中的地说,因为一个对协变量进行了调整,一个没有,而这个协变量对疗效具有显著影响。没错,这就是根本原因。但我们还是想从数据上来找一些端倪: (1)与ANOVA相比,ANCOVA中MSE的大大降低,致使治疗组间比较的精度(precision)大大增高。 正如前边所提的,ANCOVA把协变量纳入模型,作为变异来源的一部分,便可以降低误差项变异,从而提高了组间比较的精度。在这个例子中,MSE从277.6降到了93.7,由此带来的便是组间比较精度的提高。 (2)与未进行调整的组间均值的差异比较,ANCOVA在对X协变量进行调整后,治疗组间均值的差异大大增加。 在这个例子中,ANCOVA分析后建立的关系式是: A组:Y^=74.81-11.268X B组:Y^=64.59-11.268X 而协变量X在两组中的总体均数为6.8118, 把这个值带入上边的两个关系式便可以得出A组和B组调整后的均数。 我们对调整和未调整的治疗组的均数进行了总结,如下表:  从这个关系式中,我们可以看出X每增加1单位,Y会降低11.268。而A组和B组协变量X的均值分别为7.00和6.64。但ANCOVA中对两组疗效均数的计算则是基于同样的X值即两组总体均数6.8118,这个值比A组的实际X均数(7.00)小,而比B组实际X均数(6.64)大。通俗地理解如下: (1)本来A组X应该用7.00,结果用了6.818,由于在关系式中,我们发现Y与X是成反比的,因此X减小了,相应地Y会增大,这就出现了A组中Y的均值由-4.1增大变成-1.9的结果 (2)同样道理,本来B组X应该用6.64,结果用了6.818,因此X增大了,相应地Y会减小,这就出现了B组中Y的均值由-10.3减小成-12.2的结果 (3)由于A组Y均值变大,B组Y均值变小,这一正一反,结果就造成A组和B组Y均值之间的差异变得更大,而这个差异的变化足以使得两组间出现统计学差异。 其实我们进一步想来,如果A组和B组协变量X的均值差不多大的话,那么他们的总体均数应该和两组实际的均值差别不大,这样调整后的Y值变化也不会太大,那么两组Y值差异也不会变化太大,那么这种两组差异不大的变化就不足以出现结论相反的情况;但是如果A组和B组协变量X的均值差别较大,就和我们例子中的那样,就会可能出现结论相反的情况。这一点其实正好印证了前边提到的,当一些重要的基线变量在治疗组分布不均衡(即均值相差较大)时,把这个变量当作协变量加以调整后的统计分析即ANCOVA的结果可能与未使用未调整的方差分析ANOVA的结果有明显的不同。 最后,我们来看一下ANCOVA的SAS程序的实现: PROC GLM; CLASS TRT; MODEL Y= TRT X / SOLUTION; LSMEANS TRT / PDIFF STDERR; RUN; 解释: (1)SOLUTION选项:通过这个选项可以得出回归关系式的估计 (2)LSMEANS语句:可以得出协变量调整后的Y的均值 在进行ANOCOVA分析时,一个很重要的问题就是协变量的选择,在ANCOVA模型中纳入不同的协变量可能结果会有所不同。 例:一项比较降压药A和B的随机对照多中心试验,主要疗效指标为舒张压与基线相比的变化值(BPDCH)。对疗效可能有影响的协变量包括年龄(AGE)、基线舒张压(BPD0)。 下边我们来看看SAS程序构建的不同的模型和结果吧: 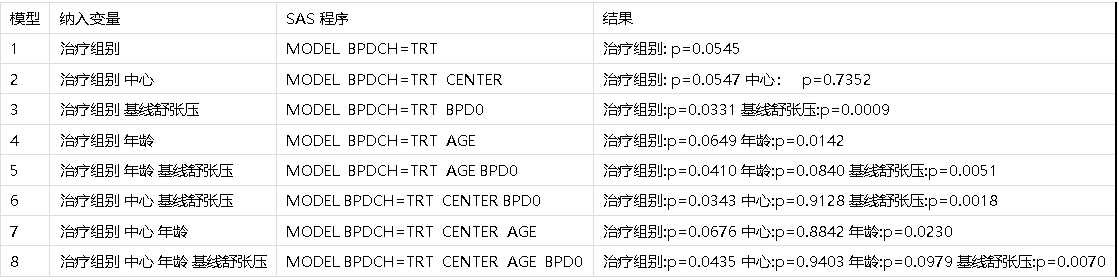 从上表中,我们可以看出: (1)不调整协变量的one-way ANOVA(模型1)和two-way ANOVA(模型2)的结果都显示治疗组别的p值都是在显著性水平的边界上,为0.05多一点。 (2)而仅把年龄当作唯一的协变量进行调整时,即模型4和模型7时,年龄都是具有显著性意义的,p值分别为0.0142和0.0230;而把基线舒张压也放进模型作为协变量调整时,即模型5和模型8时,年龄就没有显著意义了,p值分别为0.0840和0.0979;这说明什么呢?可能年龄和基线舒张压具有共线性。 (3)当基线舒张压作为协变量而年龄不是协变量时,即模型3和模型6时,治疗组间就有着明显的显著性差别,p值分别为0.0331和0.0343。 从上边不同模型得出不同的结果,这些都表明在研究设计阶段就建立一个适当的统计模型有多么重要,它直接关系着最后的结果和结论。 我们都知道如果统计分析方法没有事先规定好,在进行分析时就会产生bias,这个很好理解,就如上边这个例子,如果我没有事先规定好统计分析模型,而是在分析时不断地试来试去,一个一个模型地来试,这势必会产生偏倚。因此还是强调的那一点,避免偏倚,就是事先规定,如果这个方法是我事先规定的,那么就不会有闲话了。当然事先规定的统计分析方法应该是恰当的,对于统计方法的确定可以参考相关的以前的研究等方法。如果我们纳入了恰当的协变量,那么通过协变量的调整,就可以提高检验出组间差异的把握度,但是如果纳入了不恰当的协变量就可能会稀释组间的差异、出现共线性问题、以及不必要地降低误差项的自由度,从而降低检验把握度甚至得出不正确的p值。 |
【本文地址】