| 注意力之双线性模型注意力 | 您所在的位置:网站首页 › 双曲线模型化为线性模型公式 › 注意力之双线性模型注意力 |
注意力之双线性模型注意力
|
本文主要针对两篇论文:双线性注意力网络模型和深度模块化注意力进行总结,加上自己对其的理解。若有不足,还望指出。 论文地址: 双线性注意力网络 深度模块化注意力 项目地址: 双线性注意力网络 深度模块化注意力 0. 写在前面首先我们要知道什么是注意力机制和什么是双线性模型 0.1 注意力机制注意力一词来源与我们自身的视觉系统,现实生活中,我们观察事物倾向于将信息集中进行分析而忽略掉图像中的无关信息。同样,在计算机视觉研究领域中,也存在类似情况,例如VQA任务,可能只有图像中的个别对象与我们的答案有关,同样,在问题中可能只有个别个单词与我们的图像有关。注意力机制就将这种关系进行了整合,允许模型动态的去关注输入的特定部分,从而有效的提高模型的效率。 它的一个重要假设就是:学习得到的注意力权重体现了当前需输出的数据与输入序列的某些位置的相关性。权重越大,相关性越高。 如图:对图像字幕任务中生成的文本有显著影响的相关图像区域(高注意权重) 堆叠注意力就是一种多层的注意力,通过多步推理定位与问题相关的图像区域进行答案预测。具体步骤如下: 第一步:使用问题向量(q1)来查询第一视觉注意层的图像向量(v1),将问题图像和检索到的图像向量(与问题相关的图像区域)结合形成查询向量(u1),第二步:用第一步得到的查询向量u1继续来查询第二视觉注意层的图像向量v2,将第一视觉注意层的查询向量和与其相关的图像区域的图像向量结合形成新的查询向量u2。 由此,较高级别的注意层,将更关注图像中与答案相关的区域。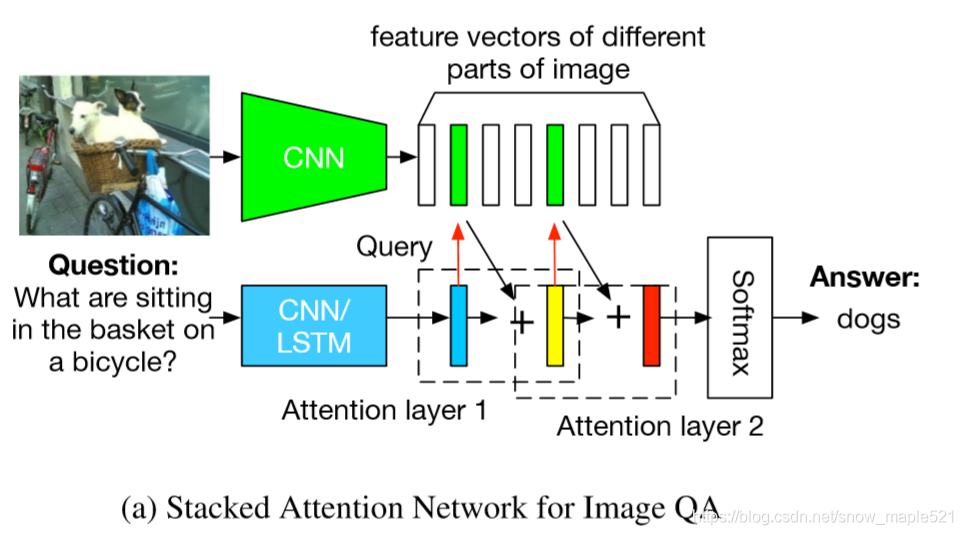  0.3 分层注意力机制(Hierarchical Attention Model)HAM
0.3 分层注意力机制(Hierarchical Attention Model)HAM
分层注意力机制也是一种多层注意力机制,它是对输入序列进行多次抽象,这样使得低层抽象的上下文向量成为下一次抽象的查询状态。一个典型应用就是对文本进行结构化分层进行抽取。 文本是由不同的句子组合而成的,而每个句子又包含不同的单词,HAM能够对文章这种自然的层次化结构进行抽取,具体如下: 第一步:就是对文章中的每个句子建议一个注意力模型,这个注意力模型输入的是每个句子的基本单词,从而得到句子的特征表示。第二步:将句子的特征表示输入到后续的注意力模型中来构建整段文本的特征表示,最后得到的特征就是文本特征输入到分类器中进行最终的预测。 0.4 分层共同注意力(Hierarchical Co-Attention )分层共同注意力是在分层注意力上的基础上加了共同,与之不同的是,分层注意力只通过问题去关注图像,此模型在问题和图像之间具有自然的对称性,即图像可引导问题注意,问题可引导图像注意。 在问题特征处理上采用分层,首先将处理单词特征,再将单词特征作为输入处理短语特征,再将短语特征作为输出句子特征,最后用句子特征进行答案预测。 0.5 双线性模型双线性模型也有称为双线性池化,主要用于特征融合。 如果特征x和特征y来自两个特征提取器(例如VQA任务中,问题特征和图像特征),则被称为多模双线性池化(MBP), 如果来自同一个则交同源双线性池化(HBP)或者二阶池化。 原始的Bilinear Pooling存在融合后的特征维数过高的问题融合后的特征维数=特征x与特征y的维数乘积,一些论文作者尝试用PCA(主成分分析)进行降维,有的采用Tucker分解等 双线性池化基于Bilinear CNN Models for Fine-grained Visual Recognition
它的双线性模型B由四个部分组成 B = ( f A , f B , P , C ) B=(f_A,f_B,P,C) B=(fA,fB,P,C), f A 和 f B f_A和f_B fA和fB是特征函数,P是池化函数,C是分类函数,公式如下: 它的公式如下: 双线性模型指形如如下公式的操作: 把提取的特征送入全连接层再送入softmax层,公式等价是: 此概念出自《Hadamard product for low-rank bilinear pooling》,核心是Hadamard积(按元素乘)来实现bilinear model。为了减少双线性矩阵W的秩,用低秩矩阵UV的乘积来近似,把上面公式写成如下:(低秩双线性模型) 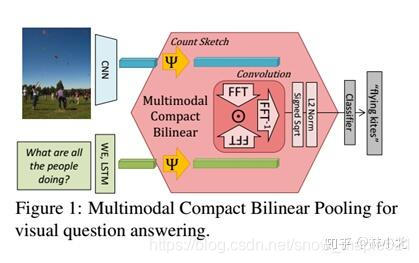 
这里
Ψ
\Psi
Ψ是一个sketch函数(一种降维方式), 作者指出,虽然协同注意力网络能够有选择的关注问题关键词和图像关键区域,但是却忽视了两者的交互带来的计算量。所以作者提出将协同注意力扩展为双线性注意力,如果问题中涉及多个关键词,那么就会对每个关键词使用视觉注意力来查找视觉关键区域。 因此作者提出双线性注意力网络,结构如下图: 公式如下: 两个多通道的输入X和Y,为了减少两个输入通道,引入双线性注意力图A, 双线性注意力模型图如下表示: |


 公式理解:就是将图像中的同一位置上的两个特征进行乘,然后得到矩阵B,再对矩阵B进行sum pooliing池化得到矩阵
ξ
\xi
ξ,再对
ξ
\xi
ξ向量化,得到双线性向量x,再对x进行归一化操作,得到融合后的特征z,再将z用于分类和预测。
公式理解:就是将图像中的同一位置上的两个特征进行乘,然后得到矩阵B,再对矩阵B进行sum pooliing池化得到矩阵
ξ
\xi
ξ,再对
ξ
\xi
ξ向量化,得到双线性向量x,再对x进行归一化操作,得到融合后的特征z,再将z用于分类和预测。 忽视归一化操作,HBP特征如下表示:
忽视归一化操作,HBP特征如下表示: 
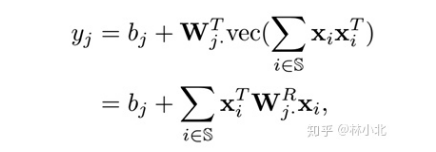 W
j
W_j
Wj是全连接层的参数矩阵需要学习的,
W
j
R
W^R_j
WjR是与之对应的,所以直接对
W
j
R
W^R_j
WjR进行学习。就是双线性模型与双线性池化差不多的原因。
W
j
W_j
Wj是全连接层的参数矩阵需要学习的,
W
j
R
W^R_j
WjR是与之对应的,所以直接对
W
j
R
W^R_j
WjR进行学习。就是双线性模型与双线性池化差不多的原因。 如果需要扩大矩阵
U
i
和
V
i
U_i和V_i
Ui和Vi,再采用了池化矩阵P(低秩双线性池化),控制输出即可
如果需要扩大矩阵
U
i
和
V
i
U_i和V_i
Ui和Vi,再采用了池化矩阵P(低秩双线性池化),控制输出即可 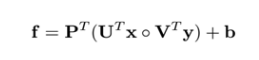

 MCB模块的工作:加了attention之后的框架如下:
MCB模块的工作:加了attention之后的框架如下:  这是一共用了两次的MCB模块,第一个融合了文本和图像的特征来提出图像的attention,第二个是将图像的attention特征与文本特征再一次融合,并将结构送入全连接网络,再送入softmax分类器得到答案。
这是一共用了两次的MCB模块,第一个融合了文本和图像的特征来提出图像的attention,第二个是将图像的attention特征与文本特征再一次融合,并将结构送入全连接网络,再送入softmax分类器得到答案。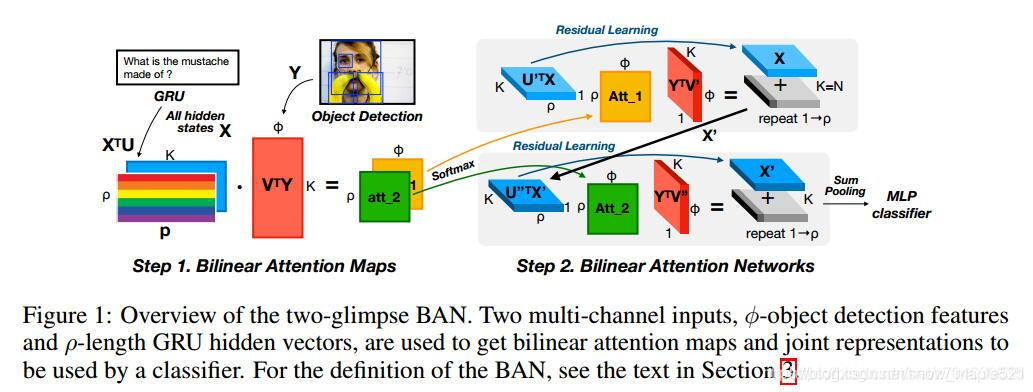
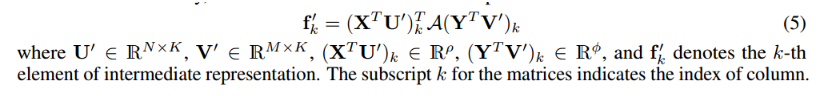 其中A是一个双线性权重矩阵,上式还可以如下表示:
其中A是一个双线性权重矩阵,上式还可以如下表示: 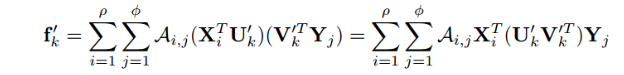 我们将双线性注意力网络函数表示如下:
我们将双线性注意力网络函数表示如下: 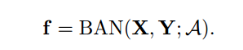
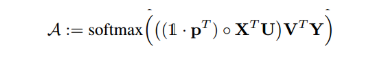 可以看出A中的每个元素都是经过低秩池化得到,
可以看出A中的每个元素都是经过低秩池化得到, 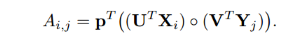 多重双线性池化注意力分布图由softmax输出图如下表示:
多重双线性池化注意力分布图由softmax输出图如下表示: 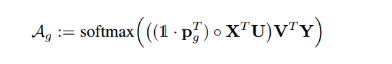
【本文地址】