| 机器学习中常见的六种分类算法(附Python源码+数据集) | 您所在的位置:网站首页 › 博弈有哪些分类方式和特点 › 机器学习中常见的六种分类算法(附Python源码+数据集) |
机器学习中常见的六种分类算法(附Python源码+数据集)
|
今天和大家学习一下机器学习中常见的六种分类算法,如K近邻、决策树、朴素贝叶斯、逻辑回归、支持向量机、随机森林 除了介绍这六种不同分类算法外,还附上对应的Python代码案例,并分析各自的优缺点。 01 K近邻(KNN)
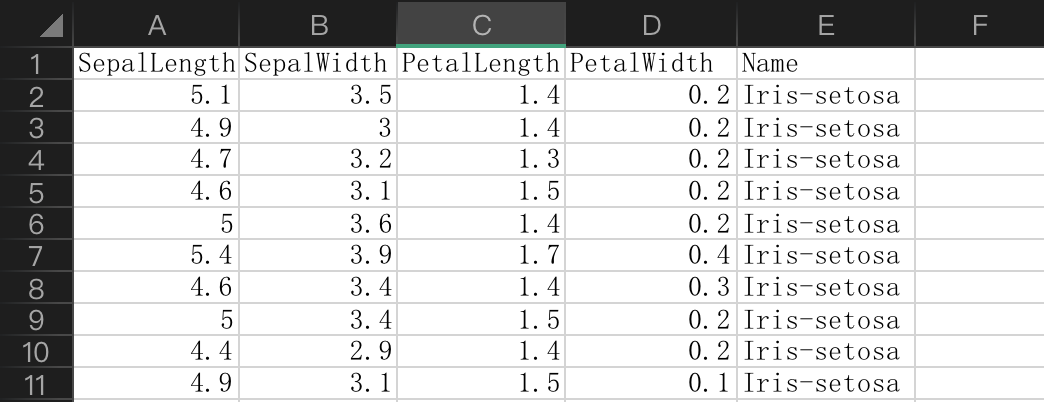
k-近邻算法KNN就是K-Nearest neighbors Algorithms的简称,它采用测量不同特征值之间的距离方法进行分类,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。 代码案例 数据集:iris.csv(文末会提供) import pandas as pd import numpy as np import operator # 导入数据 data = pd.read_csv("iris.csv")
前四列为特征,最后一列为类别 欧几里距离 # 计算两个数据点之间的欧几里德距离 def euclideanDistance(data1, data2, length): distance = 0 for x in range(length): distance += np.square(data1[x] - data2[x]) return np.sqrt(distance)KNN模型 # KNN 模型 def knn(trainingSet, testInstance, k): distances = {} sort = {} length = testInstance.shape[1] # 计算每行训练数据和测试数据之间的欧氏距离 for x in range(len(trainingSet)): dist = euclideanDistance(testInstance, trainingSet.iloc[x], length) distances[x] = dist[0] # 根据距离对它们进行排序 sorted_d = sorted(distances.items(), key=operator.itemgetter(1)) neighbors = [] # 提取前 k 个邻居 for x in range(k): neighbors.append(sorted_d[x][0]) classVotes = {} # 计算邻居中频率最高的类别 for x in range(len(neighbors)): response = trainingSet.iloc[neighbors[x]][-1] if response in classVotes: classVotes[response] += 1 else: classVotes[response] = 1 sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True) return (sortedVotes[0][0], neighbors)预测某数据的类别 # 定义一个测试数据 test_data = [[6.8,5.1,4.9,1.5]] test = pd.DataFrame(test_data) # 设置邻居数 = 3 k = 3 # 运行 KNN 模型 result, neigh = knn(data, test, k) # 预测类别 相邻的k个邻居 print("类别:",result,"相邻的k个邻居:",neigh)执行结果
总结 算法特点: 优点:精度高、对异常值不敏感、无数据输入假定 缺点:计算复杂度高、空间复杂度高 适用数据范围:数值型和标称型 02 决策树
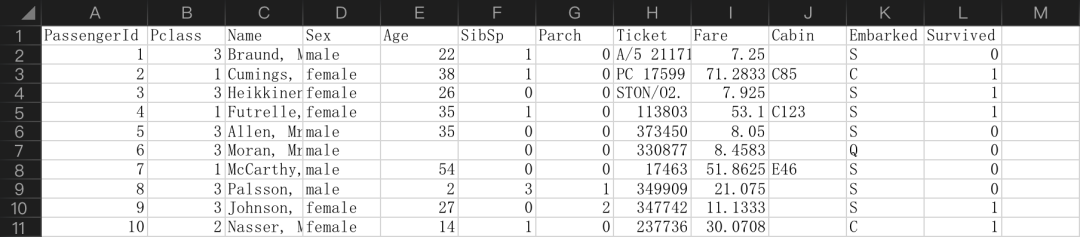
决策树(Decision Trees)是一种非参监督学习方法,即没有固定的参数,对数据进行分类或回归学习。决策树的目标是从已知数据中学习得到一套规则,能够通过简单的规则判断,对未知数据进行预测。 代码案例 数据集:train.csv(文末提供) from sklearn import tree from sklearn.model_selection import train_test_split import pandas as pd titanic = pd.read_csv("data/train.csv")
前面几列为特征,最后一列为类别 特征处理 ## 数据特征处理 titanic["Age"] = titanic["Age"].fillna(titanic["Age"].median()) titanic["Embarked"] = titanic["Embarked"].fillna("S") candidate_train_predictors = titanic.drop(['PassengerId','Survived','Name','Ticket','Cabin'], axis=1) categorical_cols = [cname for cname in candidate_train_predictors.columns if candidate_train_predictors[cname].nunique() |



【本文地址】
公司简介
联系我们