| 爬虫终于找到了知乎/B站 Top100大V,关注! | 您所在的位置:网站首页 › 健康大v都有谁 › 爬虫终于找到了知乎/B站 Top100大V,关注! |
爬虫终于找到了知乎/B站 Top100大V,关注!
|
经常逛知乎、B站,作为吃瓜群众也很好奇这两个网站「头部用户」是哪些人。 为了满足各位好奇心,先上名单后上爬虫思路和代码。
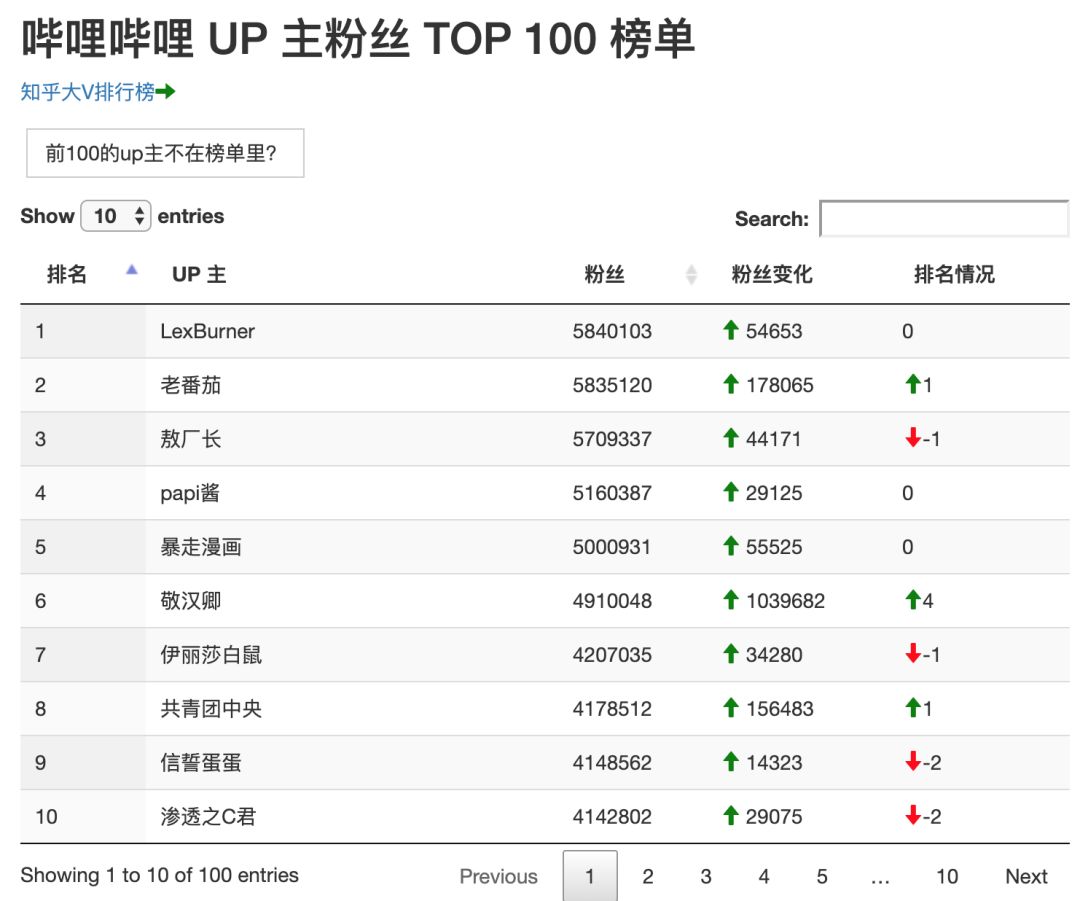
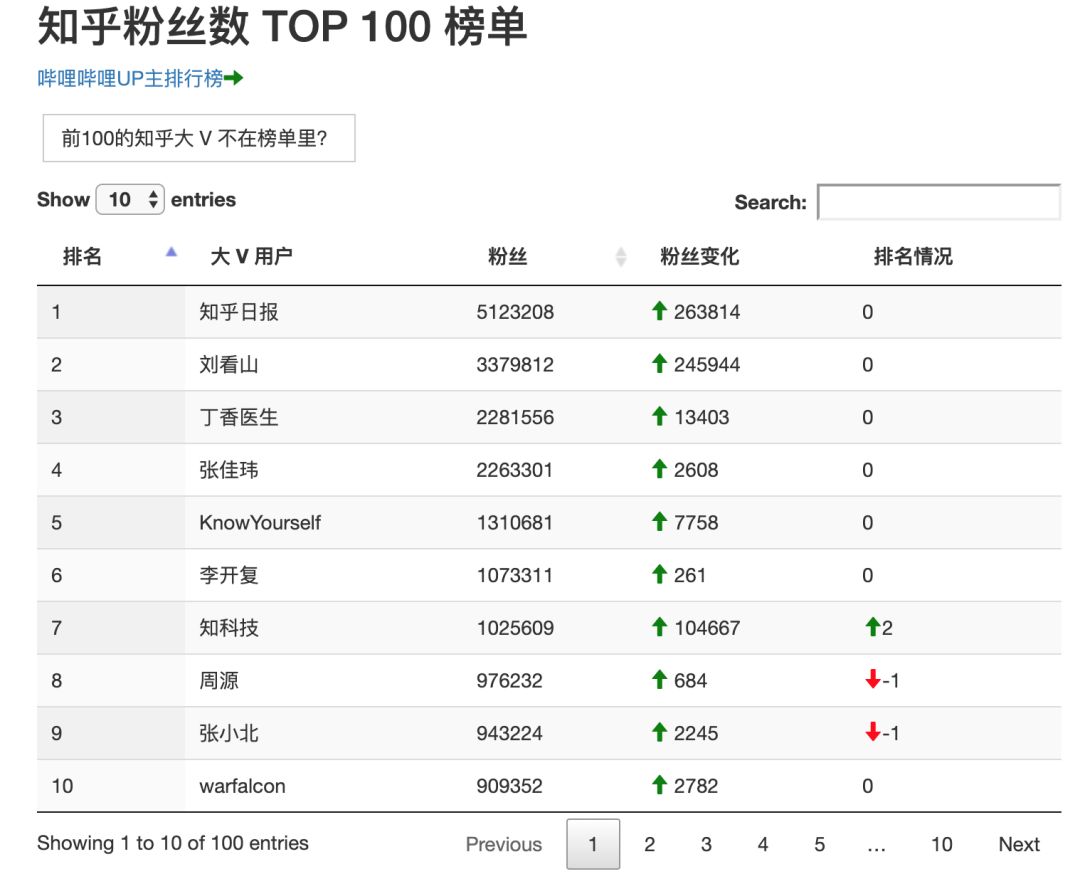
居然是他们。 体验网页: http://rank.python666.cn/ 下面说说爬取和可视化思路: 这两个平台的被关注数都是公开的数据,不像微信公众号。所以只要你一个个用户翻过去,就可以找出哪些用户的“粉丝”更多。但显然,我们不可能人工来做这样的事情,这两个平台的账号数都已过亿。我们需要借助程序来做这件事。 即使用程序,上亿个用户每个都查一下,假设1秒钟查10个,也需要查100多天。所以我们需要改进下“算法”:知乎上选取几个大V用户(实际上我们就是从“张佳玮”一个号开始),只去查他们关注的用户,如果发现里面有超过1万粉的大V,就加入到大V队列末尾,直到遍历完整个队列。再对所有找到的用户进行排序。因为通常来说,一个大V总会被其他大V所关注,所以这样就几乎包括了所有大V。 B站上也是类似,但是选取了今年播放数超50万视频的UP主,以他们作为最初的大V队列。之后再通过他们关注的人进行数据更新。 当然,这种方法也存在遗漏的可能,比如或许存在某个大V,因为某些原因恰好没有被我们所抓取的队列总任何一个用户所关注,那么他就不会存于排行榜中。虽然从统计学的角度来说,这个概率很小。但我们也为此做了一个弥补,就是一旦你发现某个大V不在列表中,可以通过页面上方的输入框提交他的主页链接,那么我们就会收录在队列中,下次更新时就会增加进去。 有了这个排行,平台上的大V都有谁就一目了然了。更进一步,你还可以从细节看出些有意思的东西。举几个例子: B站UP主“敬汉卿”,上周因为名字被某公司恶意抢注的事件,得到较多关注,粉丝涨了100多万 本期B站排名第69的“罗汉解说”,上周上升24名。对这位UP主我不熟悉,看了下也是因为一个维权相关的视频受到了关注 知乎上现在排名最前和涨幅最猛的是几个自家账号:知乎日报、刘看山、知科技。丁香医生超张佳玮成知乎一哥,而他俩则远高于后面一位。 知乎榜上只有一位用户的关注是负增长:无耻采铜。老知乎用户应该知道他,也是有一些历史遗留八卦在其中。此账号65万关注,但现在已没有任何回答。 通过数据的整理和可视化,经常会让人发现一些平常注意不到的信息。这个排行工具只是个练手的小程序,功能还简陋,也没做移动端适配。不过对于需要运营知乎账号的新媒体从业者,或者榜上的创作者们,类似的工具还是很有用处的。普通用户也可以从榜上去发掘一些宝藏作者/UP主。 这个案例对于想要做爬虫的同学来说是个比较好的套路案例。类似的方法,你可以用在监控商品价格波动、新品上架、库存量变化、番剧更新、明星的微博等等需求中。尽管现在有很多工具可以完成类似的工作,但如果遇到工具不能满足的时候,如果自己可以动手用几行代码解决,那就很能增加你的竞争力了。 此项目实现有一点特殊的地方在于,它的数据是另一个分析项目的副产品,是使用 scrapy 抓取的。因此在本案例中,我们以原始数据的形式直接给出。具体 scrapy 抓取部分的代码会在后续项目中提供。 此项目用 django 搭建了展示的页面,前端展示使用了 Datatables 表格插件。定时抓取是通过 Linux 下的 cronjob 功能来实现(windows 可以使用计划任务),抓取时使用了 requests 模块。 源代码及文档: https://github.com/spiderbeg/bili_rank |
【本文地址】