| 通过opencv实现简单的人脸识别 | 您所在的位置:网站首页 › 人脸识别怎么操作 › 通过opencv实现简单的人脸识别 |
通过opencv实现简单的人脸识别
|
文章目录
通过opencv实现简单的人脸识别1.环境配置2.收集数据集3.人脸数据的处理4.通过神经网络训练模型5.进行人脸识别6.总结
通过opencv实现简单的人脸识别
网上有很多通过opencv实现的简单人脸识别,本文于其他文章差别不大,仅为作者复现代码后的一个学习记录。实现的过程大致为收集人脸数据集,通过神经网络训练出模型,然后将实时人脸放到模型中进行识别,其实就是解决一个简单的二分类问题。所以它的实用性其实并不高,但是对于初入计算机视觉的小白们,这是理解如何通过神经网络训练出模型的一个好机会。 1.环境配置 1.window,ubantu环境均可 2.python3.6,3.7版本均可 3.opencv最新版即可(直接pip) 4.scipy(我是1.3.1版本,一般不用额外装) 5.sklearn 6.Keras 7.tensorflow(建议1.4.0左右的版本) 2.收集数据集
收集数据的第一步就是打开摄像头,下述写了几个通过opencv打开摄像头的基本函数。 cv2.namedWindow(window_name) #窗口名字 cv2.VideoCapture(camera_id)#camera_id=0内置摄像头,也可以为本地视频路径 ok, frame = cap.read()#返回两个值(1.当前帧是否有效 2.当前帧截取的图片) cap.release() #关闭摄像头 cv2.destroyAllWindows() #释放全部窗口classfier = cv2.CascadeClassifier() 打开摄像头后,我们通过opencv内置的级联分类器CascadeClassifier进行捕捉人脸的步骤。 classfier = cv2.CascadeClassifier("D:/anaconda/Lib/site-packages/cv2/data/haarcascade_frontalface_alt2.xml") 可以看到分类器后面有一个xml文件的路径,当下载opencv后,找到anaconda的安装路径,然后根据上面给定的路径找一般都能找到。这个xml文件是opencv官方共享的具有普适性的训练数据,然后通过这些数据可以获得一个良好的人脸分类器。官方也共享了笑脸分类器,眼镜分类器等,有兴趣的可以在官方网址了解其他文件的作用,将xml文件路径改了试一试。 (官方网址:https://github.com/opencv/opencv/tree/master/data/haarcascades) classfier.detectMultiScale() 得到人脸分类器的目的是获得视频中人脸的位置,并通过cv2.rectangle()对视频中捕捉的人脸进行画框。 classfier.detectMultiScale(const Mat& image, vector& objects,double scaleFactor=1.1, int minNeighbors=3,int flags=0, Size minSize=Size(), Size maxSize=Size()) 1.image表示的是分类器检测到的每一帧的图片作为输入 2.object表示检测到的人脸目标序列,一般可不写 3.scaleFactor默认为1.1,表示每次检测到的人脸目标缩小的比例 4.minNeighbors默认为3,表示检测过程中目标必须被检测三次才能被确定为人脸(分类器中是有个窗口对全局图片进行扫描的,即扫描过程中,窗口中出现了三次人脸可以确定该目标为人脸) 5.flag默认为0,一般可不写 6.minSize表示可截取的最小目标大小 7.maxSize表示可截取的最大目标大小 该函数输出的结果是人脸的位置(x,y,w,h),x,y指人脸位置的左上角坐标,w,h指长宽收集人脸数据 在对一些核心函数有了解之后,我们开始进行人脸数据的收集。首先就是创建一个face文件夹,该文件夹中再新建两个文件夹分别命名为自己的姓名和other。 机器学习中有一个很重要的概念叫有监督学习,而有监督学习中有细分两类问题:分类问题和聚类问题。**分类问题一般用于识别,回归问题一般用于检测。而在制作简单人脸识别的过程中,涉及到了两次的分类,一次的回归。**第一次的分类在上一步收集人脸数据时,识别视频中的人脸(知道是脸,但是不知道是谁的脸),第二次的分类在识别视频中的人脸是谁;回归用在上一步收集人脸时回归出人脸的位置。 在完成上一步骤后,我们已经解决了一个分类问题和一个回归问题,就剩下识别人脸是谁这个步骤,也是制作人脸识别最核心的步骤。 本步骤目的就是将收集到的图片进行一定的预处理,接下来介绍一下该步骤的几个函数。 def resize_image(image, height = ImageSize, width = ImageSize) 参数介绍:image指输入图片,height,width指最后输出图片的长宽,这里我们设置为64 x 64 函数目的:将图片填充为正方形,然后调整为64 x 64
附上该步骤完整代码(命名为load_dataset) import os import random import sys import cv2 import numpy as np from sklearn.model_selection import train_test_split ImageSize = 64 def resize_image(image, height = ImageSize, width = ImageSize): top,bottom,left,right = (0,0,0,0) h, w, _ = image.shape #print(h, w, _) longest = max(h, w) #print(longest) if h |
 我们接触到的人脸识别系统首先都需要有个录脸的过程,收集数据集这个步骤就类似于录脸。目的在于收集我们的人脸数据,让计算机可以对你的人脸进行训练。
我们接触到的人脸识别系统首先都需要有个录脸的过程,收集数据集这个步骤就类似于录脸。目的在于收集我们的人脸数据,让计算机可以对你的人脸进行训练。 一个文件夹下收集的人脸必须是同一个人的(所以完成这件事需要两个人),收集两份人脸的目的为了用于二分类,以提高模型的精度。每个文件夹下收集1000张图片(总共2000张),在收集过程中人脸分类器可能会将的灯,标志等错误录入,这时就需要手动删除这些错误图片,防止后面训练时造成误差。
一个文件夹下收集的人脸必须是同一个人的(所以完成这件事需要两个人),收集两份人脸的目的为了用于二分类,以提高模型的精度。每个文件夹下收集1000张图片(总共2000张),在收集过程中人脸分类器可能会将的灯,标志等错误录入,这时就需要手动删除这些错误图片,防止后面训练时造成误差。  附上该步骤完整代码(命名为face_capture)
附上该步骤完整代码(命名为face_capture)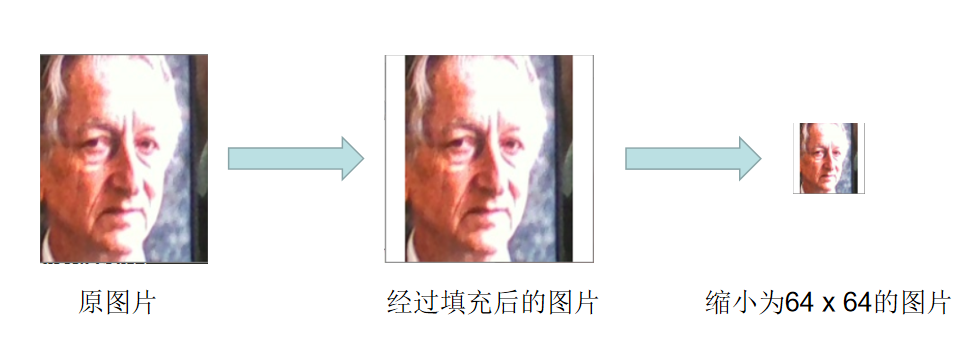


【本文地址】