| 从300多个国内大模型中脱颖而出的Kimi是谁? | 您所在的位置:网站首页 › 人工智能的模型是会被误导的吗 › 从300多个国内大模型中脱颖而出的Kimi是谁? |
从300多个国内大模型中脱颖而出的Kimi是谁?
|
原创 巴九灵 “中国‘OpenAI’候选人的处女作。” 文 / 巴九灵(微信公众号:吴晓波频道) 大家注意 这款国产AI大模型叫Kimi 本名是Kimi人工智能助手 我们不妨叫它小K 这几天小K因为“工作压力”太大 彻底崩溃了 2月以来 它的访问量达305万 较上个月增长了107.6% 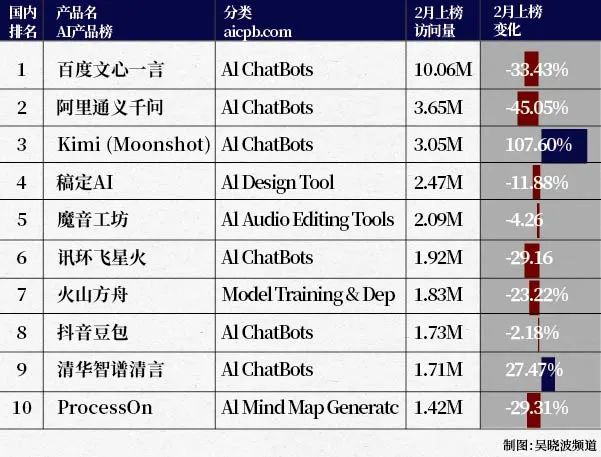 而小K的爆火 是从300多个国内大模型中 突围而出 它们个个来历不凡 有科技巨头选派的 有高等学府保送的 但小K所在的公司 成立却才刚满一年  与此同时 A股市场与小K有关的概念股 也涨得飞起 涨停板和玩儿似的 最离谱的是 就连给小K公司提供厕纸的公司 也跟着涨了 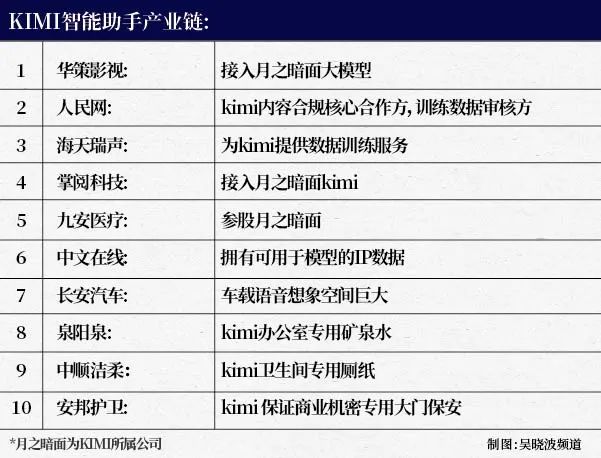 当然,还有很多人可能还没听说过它 可能会皱着眉头问:谁是Kimi? 今天我们就来聊聊它的故事 AI界的中国新星 “现在的小K 火爆程度简直就像是AI界的摇滚明星 200万字长文处理技术 简直就是时间的压缩饼干 让人吃了之后瞬间充满能量 想当年,成为专家得像马拉松一样 跑上数万小时 现在有了小K 就像是坐上了知识界的高速列车 10分钟就能飙到新领域的起点 轻松拿到初级专家的入场券” 如果你觉得以上的文字很浮夸 别急,这是小K对自己吹的“彩虹屁” 但“坐上知识界的高速列车” 这句话真的不是夸张 和ChatGPT类似 Kimi也是一款语言大模型 我们也可以通过输入框与它对话沟通 相对而言,Kimi术业有专攻 它擅长“吞食”长文本  简而言之,你给Kimi投喂一部 2500多页、接近200万字《哈利·波特》 它不会回扔你骂街 反而能告诉你具体的故事梗概 甚至书中的人物之间的关联 追求实用的网友,给了它一本 1980年到2023年的历届考研英语真题 它不仅分析出了往年题型的变化趋势 还挖掘出了高频词汇和短语 并预测了2024年可能出现的题型 2023年刚出道的小K 长文本处理能力就令人惊叹 它在对话框里 一口气不带喘地吞下20万汉字 并为用户精准瘦身内容 提炼核心内容 到了今年3月18日 它宣布可以进行200万汉字的 “马拉松阅读挑战” 创下迄今为止大模型界的最长纪录 这下,人们对小K的“超能力”更好奇了 3月22日 由于流量激增、日活破百万 小K的服务器彻底崩溃 崩了不要紧 要紧的是崩了以后 它的崩溃上了微博热搜 这下好了,更多人知道它了 小K的压力更大了  与市面上许多大模型相比 小K不似企业用的那种 距离普通人很远 也不像一些个人AI助手那么鸡肋 平时显得可有可无 相反小K特别实用 情商还很高 面对各种刁钻提问 或诗词文学作品点评时 它总能找到各种角度“花式”夸赞 情绪价值给人彻底拉满  中国“OpenAI”候选人的处女作 小K的母公司名叫月之暗面 去年3月才成立 创始人是三位90后 CEO杨植麟 是位1993年出生的广东汕头小哥哥 清华计算机系毕业 打上学那会儿就已经对AI情有独钟 技术牛到不行 因此被称作AI界的天才少年 后来,他跨越太平洋 去了卡内基梅隆大学语言技术研究所深造 师从苹果公司AI负责人以及谷歌首席科学家  读博期间,杨植麟的论文发表得飞起 覆盖了自然语言处理、文本分类 问答系统、半监督学习这些AI界的热门话题 让同行们刮目相看 不仅如此,多才的他还多艺 据传他还是一位摇滚鼓手! 去年夏天,硅谷极具影响力的科技媒体 The Information评出了 有可能成为“中国OpenAI”的五个候选 包括MiniMax、智谱AI 光年之外、澜舟科技以及杨植麟 其他都是公司 就他直接是一个个体 2023年3月,杨学霸回国创业 他的左膀右臂,是清华的老同学周昕宇 以及同样毕业于清华 卡内基梅隆的吴育昕  这样一支梦之队 给小K的技术创新和迭代速度 打下了坚实的基础 也让投资界的大佬们争相追捧 红杉资本、真格基金一上来 就砸了3亿美元的天使轮 2023年7月,也就是杨学霸创业的第四个月 美团龙珠领投了A轮 2024年2月 阿里、小红书这些新贵 带着红杉等老股东 又来了一轮超10亿美元的B轮 让月之暗面的估值飙升到25亿美元 一跃成为独角兽俱乐部里的AI新星  质疑小K,理解小K,成为小K 与ChatGPT相比 小K在中文处理、长文本处理 以及多客户端支持方面 具有明显优势 但在翻译特定领域内容 和避免宕机方面还有待改进 但小K的爆火 闪到了国内AI元老的眼 他们纷纷加大资源投入 在眼光方面的缺失 总可以用实力找补回来 360和阿里巴巴 一个宣布能处理500万字 一个说1000万字不在话下 百度的文心一言也不甘落后 打算把处理能力从3.2万字 提升到200万至500万字 更有AI大模型行业投资人直言 “长文本在技术圈里并不稀奇 并没有想象中那么难”  但小K的难而可贵之处 恰恰在于它通过一个朴素的方式 让大厂们看到了AI产品 在To C收费上的潜力 过去他们聊得更多的 都是To B端 有人总结了国内这一年多来 大模型的亮相方式 无非是这样一套标准动作 1.秀实力:公布模型参数量 2.秀胸怀:公布模型是开源还是闭源 3.秀成绩:公布各项测试的成绩 但对于普通大众来说 以上都只传达了一句话: “AI很厉害了,但与我无关” 但企业也有难言之隐 对于大模型公司来说 规模化、付费率和成本 构成了一个不可能三角 即便成功走向了To C 若要把产品做大做强 还得需要让用户“加钱” OpenAI去年就预测 要想不亏 GPT3.5和4模型的月付费率 每月得提升0.5% 如今小K的获客成本也不低 大约在10元一个人 算上后续的算力成本 每个人可能要到12—13块 这么一来,每天的推广成本就得小几十万 而且,用户越多 算力资源的耗损就越大 翻开新的魔术牌 随着人们对小K越来越熟悉 Kimi的热度也有些降温 至少股票是涨不动了 但Kimi的故事 似乎再次验证了 AI界的两个奇妙法则 法则一:创新的突破往往并不来自大公司 这一点OpenAI的出现 乃至过往许多突破者的故事 就已经说明了一切 法则二:伟大不能被计划 来自OpenAI的肯尼斯·斯坦利和乔尔·雷曼 在总结他们在人工智能领域的探索经验时 提出了这样一个结论 好东西从来都不是按照某个目标 刻意计划出来的 当巨头们开始困于大模型的标准范式 开始期望在宏大的愿景中 争夺时代的船票时 小公司往往只在一件事上动脑筋 “如何让更多人用上AI?”  最后,我们也让小K预测了下自己的未来 它的回答是: “我的未来就像是一场刺激的魔术秀 能不能翻开新的王牌 或者变出成本削减的魔术牌 会是它能否持续领跑的关键” 这话说得有点文艺也有点模糊 但又似乎在用另一种方式表达 “伟大不能被计划” *配图由midjourney生成 本篇作者 | 逸兴丨和风月半 | 配图 | 赵婕 原标题:《从300多个国内大模型中脱颖而出的Kimi是谁?》 阅读原文 |
【本文地址】