| YOLO V5目标检测 | 您所在的位置:网站首页 › yolo网络特点 › YOLO V5目标检测 |
YOLO V5目标检测
|
一、YOLO V5的主要组成部分
本文参考: 睿智的目标检测56——Pytorch搭建YoloV5目标检测平台 YOLOv5网络详解 YOLO V5模型主要由三个部分组成,分别为Backbone、FPN、Yolo Head。 Backbone就是yolov5的主干提取网络,在官方给的论文之中使用的是CSPDarknet,当然我们也可以将主干网络进行更换,比如更换成swin-transformer等。不过本篇笔记还是以CSPDarknet为主。backbone的作用就是将输入进来的图片进行特征提取,被提取特征可以被称为特征层,是输入图片的特征集合。在主干部分输出,我们会得到三个特征层进行下一步网络的构建。 FPN可以被称为YoloV5的加强特征提取网络,在主干部分获得的三个特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的特征层被用于继续提取特征。在YoloV5里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。 Yolo Head是YoloV5的分类器和回归器,通过Backbone和FPN,我们已经可以获得三个加强过的特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点是否有物体与其对应。 二、网络结构解析下面就是YoloV5网络的整体架构。 1、使用了残差网络Residual,CSPDarknet中的残差卷积可以分为两个部分,主干部分是一次1X1的卷积和一次3X3的卷积;残差边部分不做任何处理,直接将主干的输入与输出结合。 残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。 2、使用CSPnet网络结构,CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:主干部分继续进行原来的残差块的堆叠;另一部分则像一个残差边一样,经过少量处理直接连接到最后。 图片经过Backbone之后,会输出三个特征层。三个特征层位于主干网络的不同位置,分别位于中间层,中下层、底层,当输入的图片为(640,640,3)的时候,三个特征层的shape分别为feat1=(80,80,256)、feat2=(40,40,512)、feat3=(20,20,1024)。 1、feat3=(20,20,1024)的特征层进行1次1X1卷积调整通道后获得P5,P5进行上采样UmSampling2d后与feat2=(40,40,512)特征层进行结合,然后使用CSPLayer进行特征提取获得P5_upsample,此时获得的特征层为(40,40,512)。 2、P5_upsample=(40,40,512)的特征层进行1次1X1卷积调整通道后获得P4,P4进行上采样UmSampling2d后与feat1=(80,80,256)特征层进行结合,然后使用CSPLayer进行特征提取P3_out,此时获得的特征层为(80,80,256)。 3、P3_out=(80,80,256)的特征层进行一次3x3卷积进行下采样,下采样后与P4堆叠,然后使用CSPLayer进行特征提取P4_out,此时获得的特征层为(40,40,512)。 4、P4_out=(40,40,512)的特征层进行一次3x3卷积进行下采样,下采样后与P5堆叠,然后使用CSPLayer进行特征提取P5_out,此时获得的特征层为(20,20,1024)。 特征金字塔可以将不同shape的特征层进行特征融合,有利于提取出更好的特征 3、利用Yolo Head获得预测结果在经过FPN特征金字塔之后,我们就可以获得三个加强特征层,这三个加强特征层的shape分别为(20,20,1024),(40,40,512),(80,80,256),然后我们利用这三个shape的特征层传入Yolo Head获得预测结果。 对于每一个特征层,我们可以用一个1*1的卷积来调整通道数,最终的通道数和需要区分的种类个数相关,在YoloV5里,每个特征层上的每个特征点都存在3个先验框。 **如果使用的是voc训练集,类则为20种,最后的维度应该为75 = 3x25,**三个特征层的shape为(20,20,75),(40,40,75),(80,80,75)。 最后的75可以拆分成3个25,对应3个先验框的25个参数,25可以拆分成4+1+20。 前4个参数用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框; 第5个参数用于判断每一个特征点是否包含物体; 最后20个参数用于判断每一个特征点所包含的物体种类。 **如果使用的是coco训练集,类则为80种,最后的维度应该为255 = 3x85,**三个特征层的shape为(20,20,255),(40,40,255),(80,80,255) 最后的255可以拆分成3个85,对应3个先验框的85个参数,85可以拆分成4+1+80。 前4个参数用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框; 第5个参数用于判断每一个特征点是否包含物体; 最后80个参数用于判断每一个特征点所包含的物体种类。 三、预测结果的解码 1、获得预测框和得分经过整个YoloV5网络我们可以获得三个特征层的预测结果,shape分别为**(N,20,20,255),(N,40,40,255),(N,80,80,255)**的数据。 但是这个预测结果并不对应着最终的预测框在图片上的位置,还需要解码才可以完成。在YoloV5里,每一个特征层上每一个特征点存在3个先验框。 **每个特征层最后的255可以拆分成3个85,对应3个先验框的85个参数,**我们先将其reshape一下,其结果为(N,20,20,3,85),(N,40.40,3,85),(N,80,80,3,85)。 其中的85可以拆分成4+1+80。 前4个参数用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框; 第5个参数用于判断每一个特征点是否包含物体; 最后80个参数用于判断每一个特征点所包含的物体种类。 以(N,20,20,3,85)这个特征层为例,该特征层相当于将图像划分成20x20个特征点,如果某个特征点落在物体的对应框内,就用于预测该物体。 得分筛选就是筛选出得分满足confidence置信度的预测框。 非极大抑制就是筛选出一定区域内属于同一种类得分最大的框。 下图是经过非极大抑制的。 |

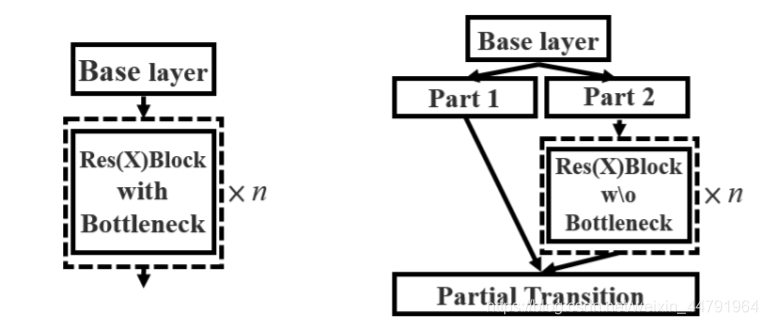 3、使用SiLU激活函数,SiLU是Sigmoid和ReLU的改进版。SiLU具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数。 f(x)=x⋅sigmoid(x)
3、使用SiLU激活函数,SiLU是Sigmoid和ReLU的改进版。SiLU具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数。 f(x)=x⋅sigmoid(x)  4、SPPF结构是将输入串行通过多个5x5大小的MaxPool层进行特征提取,提高网络的感受野。
4、SPPF结构是将输入串行通过多个5x5大小的MaxPool层进行特征提取,提高网络的感受野。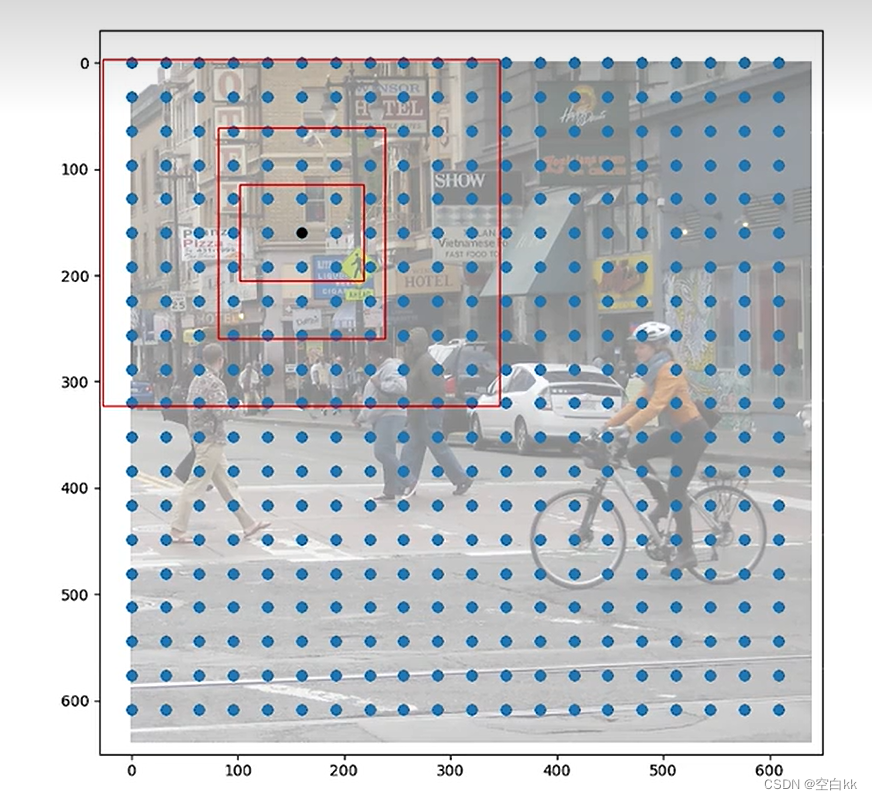 如下图所示,蓝色的点为20x20的特征点,此时我们对左图黑色点的三个先验框进行解码操作演示: 1、进行中心预测点的计算,利用Regression预测结果前两个序号的内容对特征点的三个先验框中心坐标进行偏移,偏移后是右图红色的三个点; 2、进行预测框宽高的计算,利用Regression预测结果后两个序号的内容求指数后获得预测框的宽高; 3、此时获得的预测框就可以绘制在图片上了。
如下图所示,蓝色的点为20x20的特征点,此时我们对左图黑色点的三个先验框进行解码操作演示: 1、进行中心预测点的计算,利用Regression预测结果前两个序号的内容对特征点的三个先验框中心坐标进行偏移,偏移后是右图红色的三个点; 2、进行预测框宽高的计算,利用Regression预测结果后两个序号的内容求指数后获得预测框的宽高; 3、此时获得的预测框就可以绘制在图片上了。  得到最终的预测结果后还要进行得分排序与非极大抑制筛选。
得到最终的预测结果后还要进行得分排序与非极大抑制筛选。 下图是未经过非极大抑制的。
下图是未经过非极大抑制的。 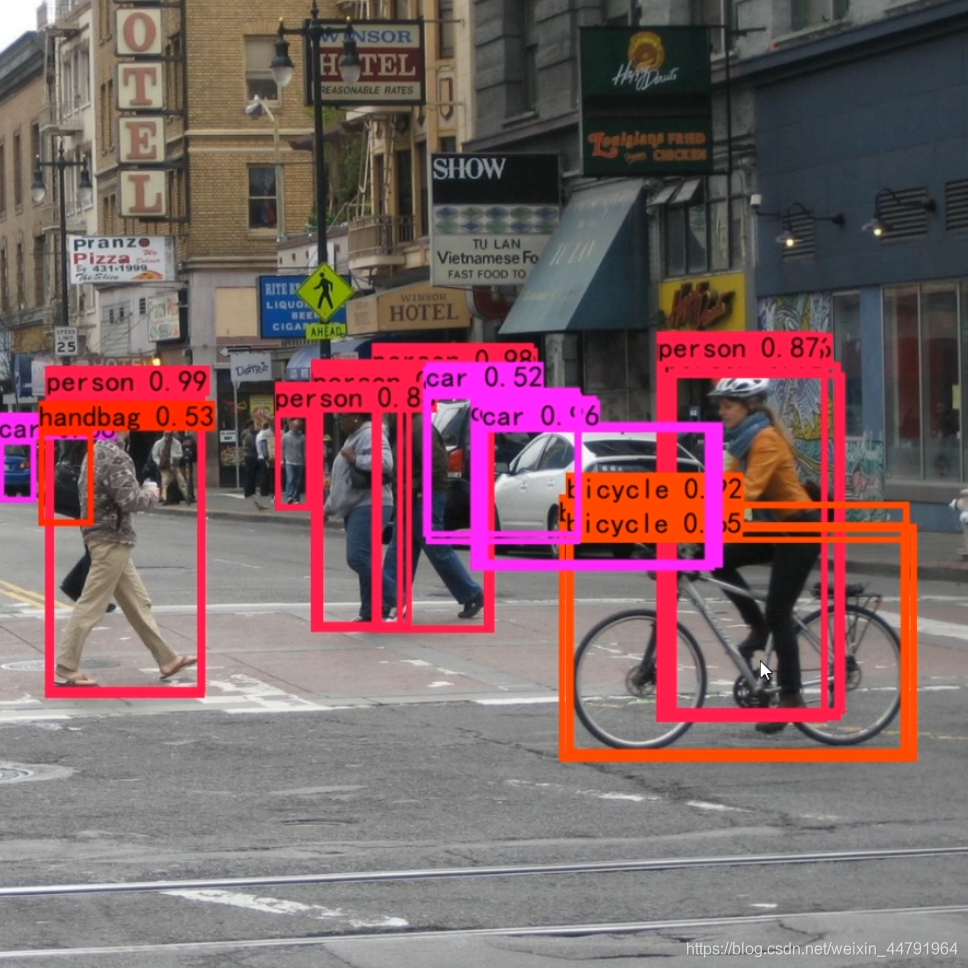
【本文地址】