|
文章目录
1、标注数据集2、训练前数据集的准备工作3、修改训练相关的代码4、用训练好的权重来测试
2022.1.2的记录:
1、标注数据集
我这里标注数据集使用的软件是labelImg,labellmg下载链接 我下的是最新版本的。 原本昨天是想标1000张的,但是好累啊,就每个信号标了50张,一共200张。 在标注之前,首先需要建立像这样的俩个文件夹(任意位置即可) 原本昨天是想标1000张的,但是好累啊,就每个信号标了50张,一共200张。 在标注之前,首先需要建立像这样的俩个文件夹(任意位置即可)  把你需要标注的图片放到JPEGImages文件夹里面,并且名字按顺序排好,像这样。 把你需要标注的图片放到JPEGImages文件夹里面,并且名字按顺序排好,像这样。  之后就可以开始标数据集了。打开labelImg。 之后就可以开始标数据集了。打开labelImg。  标完之后在Annotations文件夹下就会有刚刚标注好的坐标位置文件。需要注意的是这个文件是voc的标注格式,我们是不能直接用的。voc和yolo标注格式的不同可以参考彻底搞懂VOC/YOLO标注格式《补充》 标完之后在Annotations文件夹下就会有刚刚标注好的坐标位置文件。需要注意的是这个文件是voc的标注格式,我们是不能直接用的。voc和yolo标注格式的不同可以参考彻底搞懂VOC/YOLO标注格式《补充》 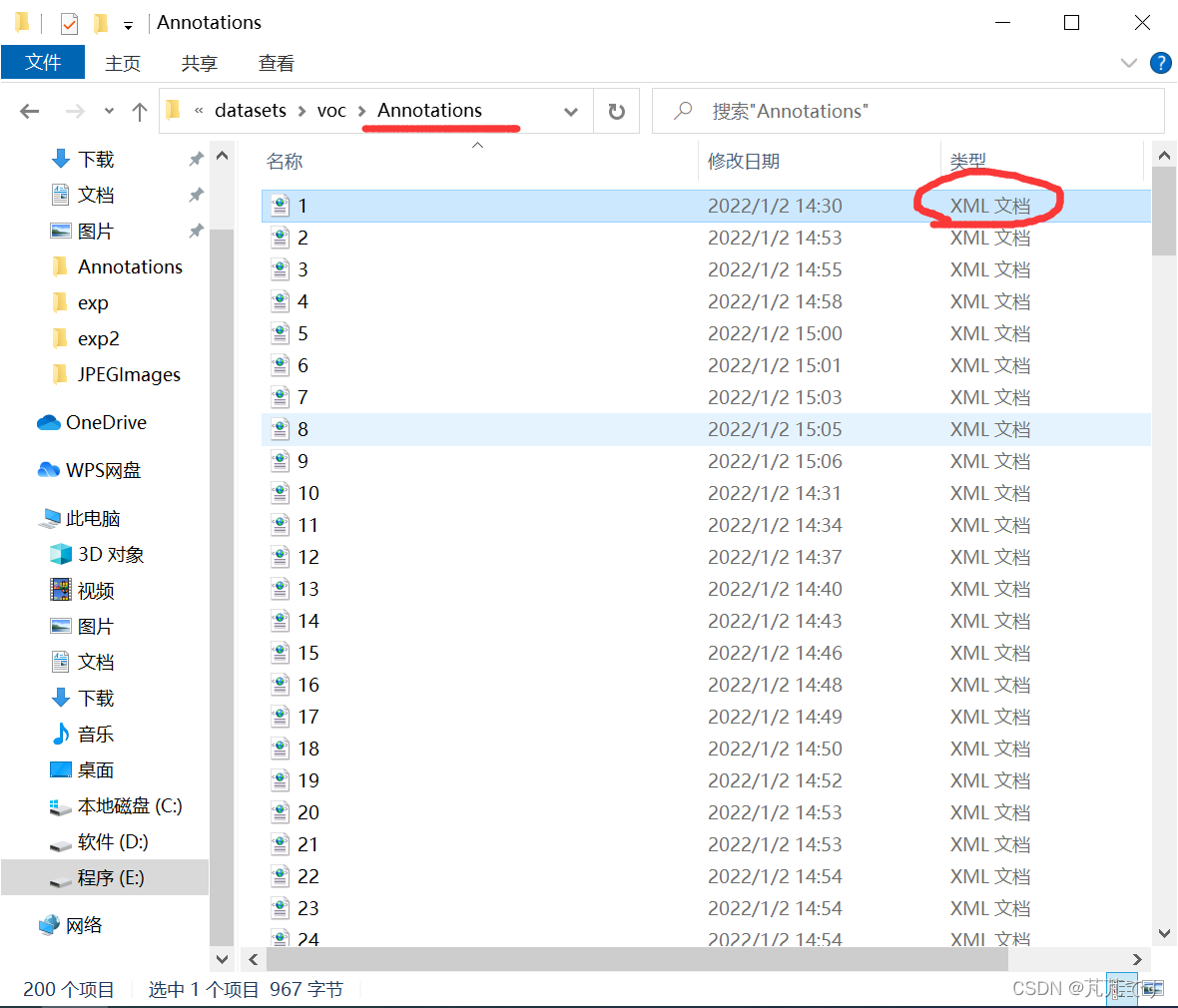
2、训练前数据集的准备工作
这一步骤的训练数据文件夹的建立路径都是按照yolov5源代码来的,以尽量不修改yolov5代码中的路径为前提。 一定要注意路径!!!不要弄错。 在上面一步中得到了voc格式的标注文件,现在需要把它转化成yolo格式的标注文件。转换的相关代码
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# 数据标签
classes = ['Signal']
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
if w>=1:
w=0.99
if h>=1:
h=0.99
return (x,y,w,h)
def convert_annotation(rootpath,xmlname):
xmlpath = rootpath + '/Annotations'
xmlfile = os.path.join(xmlpath,xmlname)
with open(xmlfile, "r", encoding='UTF-8') as in_file:
txtname = xmlname[:-4]+'.txt'
print(txtname)
txtpath = rootpath + '/worktxt' #生成的.txt文件会被保存在worktxt目录下
if not os.path.exists(txtpath):
os.makedirs(txtpath)
txtfile = os.path.join(txtpath,txtname)
with open(txtfile, "w+" ,encoding='UTF-8') as out_file:
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
out_file.truncate()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
rootpath='E:\\datasets\\voc' ##需要修改的地方
xmlpath=rootpath+'\\Annotations'
list=os.listdir(xmlpath)
for i in range(0,len(list)) :
path = os.path.join(xmlpath,list[i])
if ('.xml' in path)or('.XML' in path):
convert_annotation(rootpath,list[i])
print('done', i)
else:
print('not xml file',i)
代码中的rootpath需要修改。我的是下图圈出来的这个,你按照自己的路径修改。 运行之后会在rootpath路径下生成含有yolo标注格式文件的worktxt文件夹。 运行之后会在rootpath路径下生成含有yolo标注格式文件的worktxt文件夹。  下一步将数据集分成训练集、验证集和测试集,代码如下(不过,我用的yolov5的训练代码是没有用测试集的。我使用的是ultralytics。) 下一步将数据集分成训练集、验证集和测试集,代码如下(不过,我用的yolov5的训练代码是没有用测试集的。我使用的是ultralytics。)
import os
import random
import sys
root_path = 'E:\\datasets\\voc'
xmlfilepath = root_path + '/Annotations'
txtsavepath = root_path + '/ImageSets/Main'
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
train_test_percent = 1.0 # (训练集+验证集)/(训练集+验证集+测试集)
train_valid_percent = 0.8 # 训练集/(训练集+验证集)
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * train_test_percent) # 训练集+验证集数量
ts = int(num-tv) # 测试集数量
tr = int(tv * train_valid_percent) # 训练集数量
tz = int(tv-tr) # 验证集数量
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and valid size:", tv)
print("train size:", tr)
print("test size:", ts)
print("valid size:", tz)
# ftrainall = open(txtsavepath + '/ftrainall.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fvalid = open(txtsavepath + '/valid.txt', 'w')
ftestimg = open(txtsavepath + '/img_test.txt', 'w')
ftrainimg = open(txtsavepath + '/img_train.txt', 'w')
fvalidimg = open(txtsavepath + '/img_valid.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '.txt' + '\n'
imgname = total_xml[i][:-4] + '.jpg' + '\n'
if i in trainval:
# ftrainall.write(name)
if i in train:
ftrain.write(name)
ftrainimg.write(imgname)
else:
fvalid.write(name)
fvalidimg.write(imgname)
else:
ftest.write(name)
ftestimg.write(imgname)
# ftrainall.close()
ftrain.close()
fvalid.close()
ftest.close()
ftrainimg.close()
fvalidimg.close()
ftestimg.close()
同样,你需要修改root_path成你自己的路径,和上面改成一样就行。训练集、验证集和测试集三者的比例关系可以在代码中修改。运行之后会在root_path路径下生成一个ImageSets文件夹。  里面有个Main文件夹,里面放着分配好的含有训练集、验证集和测试集图片名称和对应的标注文件名称的文本文件。 里面有个Main文件夹,里面放着分配好的含有训练集、验证集和测试集图片名称和对应的标注文件名称的文本文件。  之后我们要将这些文件重构成符合训练代码需要的文件形式。代码如下: 之后我们要将这些文件重构成符合训练代码需要的文件形式。代码如下:
import os
import shutil
# 获取分割好的train\test\valid名称
img_txt_cg_train = []
img_txt_cg_test = []
img_txt_cg_valid = []
label_txt_cg_train = []
label_txt_cg_test = []
label_txt_cg_valid = []
root_path = 'E:\\datasets\\voc'
path = root_path + '\\ImageSets\\Main\\'
for line in open(path+"img_train.txt"):
line=line.strip('\n')
img_txt_cg_train.append(line)
for line1 in open(path+"img_test.txt"):
line1=line1.strip('\n')
img_txt_cg_test.append(line1)
for line2 in open(path+"img_valid.txt"):
line2=line2.strip('\n')
img_txt_cg_valid.append(line2)
for line3 in open(path+"train.txt"):
line3=line3.strip('\n')
label_txt_cg_train.append(line3)
for line4 in open(path+"test.txt"):
line4=line4.strip('\n')
label_txt_cg_test.append(line4)
for line5 in open(path+"valid.txt"):
line5=line5.strip('\n')
label_txt_cg_valid.append(line5)
# 建立cg数据的文件夹
new_dataset_train = root_path + '/data/train/images/'
new_dataset_test = root_path + '/data/test/images/'
new_dataset_valid = root_path + '/data/valid/images/'
new_dataset_trainl = root_path + '/data/train/labels/'
new_dataset_testl = root_path + '/data/test/labels/'
new_dataset_validl = root_path + '/data/valid/labels/'
if not os.path.exists(new_dataset_train):
os.makedirs(new_dataset_train)
if not os.path.exists(new_dataset_test):
os.makedirs(new_dataset_test)
if not os.path.exists(new_dataset_valid):
os.makedirs(new_dataset_valid)
if not os.path.exists(new_dataset_trainl):
os.makedirs(new_dataset_trainl)
if not os.path.exists(new_dataset_testl):
os.makedirs(new_dataset_testl)
if not os.path.exists(new_dataset_validl):
os.makedirs(new_dataset_validl)
# cg移动
fimg = root_path + '\\JPEGImages\\'
flable = root_path + '\\worktxt\\'
# 小数据建议:copy 大数据建议:move
for i in range(len(img_txt_cg_train)):
shutil.copy(fimg+str(img_txt_cg_train[i]),new_dataset_train)
shutil.copy(flable+str(label_txt_cg_train[i]),new_dataset_trainl)
for j in range(len(img_txt_cg_test)):
shutil.copy(fimg+str(img_txt_cg_test[j]),new_dataset_test)
shutil.copy(flable+str(label_txt_cg_test[j]),new_dataset_testl)
for q in range(len(img_txt_cg_valid)):
shutil.copy(fimg+str(img_txt_cg_valid[q]),new_dataset_valid)
shutil.copy(flable+str(label_txt_cg_valid[q]),new_dataset_validl)
同样,你要把代码当中的root_path改成你JPEGImages所在的文件路径。改成和上面一样就行。运行之后会在root_path路径下生成一个data文件夹,里面装的是yolov5训练要用到的数据文件。   然后在你放yolov5代码的文件夹的同级路径下新建一个datasets文件夹,如果你已经跑过github上用来演示的coco128数据集的话,那应该已经有这个文件夹了就不需要新建了。 然后在你放yolov5代码的文件夹的同级路径下新建一个datasets文件夹,如果你已经跑过github上用来演示的coco128数据集的话,那应该已经有这个文件夹了就不需要新建了。  新建完之后,将刚刚的data文件夹复制到datasets文件夹下。或者你就先新建一个datasets文件夹,然后修改上面的第三段程序里的路径直接将data文件夹生成到你的datasets文件夹下,省事一点。 新建完之后,将刚刚的data文件夹复制到datasets文件夹下。或者你就先新建一个datasets文件夹,然后修改上面的第三段程序里的路径直接将data文件夹生成到你的datasets文件夹下,省事一点。  然后修改文件夹的名称,比如我这个数据集里全是信号的时频图,我修改成Signals。 然后修改文件夹的名称,比如我这个数据集里全是信号的时频图,我修改成Signals。  到此,训练要用到的数据集,验证集,测试集(没有用到测试集)就都已经准备好了。 到此,训练要用到的数据集,验证集,测试集(没有用到测试集)就都已经准备好了。
这部分的代码来自制作你自己的yolov5数据集并进行训练
3、修改训练相关的代码
在上一步完成之后就可以开始训练了。如果你只是想先跑通的话,图中我用红色标出的都是需要修改的。其他的你不知道干嘛的就不要动它。 第一个weights,改成yolov5s.pt。如果你想用其他的权重,像yolov5m.pt,你需要自己去下载然后放到你的yolov5代码文件夹下。 第二个data,这个在修改之前,需要自己在data文件夹下面新建一个.yaml文件,我是复制的coco128.yaml重命名然后修改的。 第一个weights,改成yolov5s.pt。如果你想用其他的权重,像yolov5m.pt,你需要自己去下载然后放到你的yolov5代码文件夹下。 第二个data,这个在修改之前,需要自己在data文件夹下面新建一个.yaml文件,我是复制的coco128.yaml重命名然后修改的。  内容如下,我画红线的都是要改的: 内容如下,我画红线的都是要改的:  如果你上面都是跟着我的步骤来的话,train和val这俩行改成和我一样就行,path那一行把Signals改成你自己命名的文件夹名称(就刚刚生成的data文件夹)。不用test的话,test那一行也不用动它了。然后是类别数量nc,根据自己情况修改。类别名称,如果你不止一个,像下图这样一个一个加进去就好了。 如果你上面都是跟着我的步骤来的话,train和val这俩行改成和我一样就行,path那一行把Signals改成你自己命名的文件夹名称(就刚刚生成的data文件夹)。不用test的话,test那一行也不用动它了。然后是类别数量nc,根据自己情况修改。类别名称,如果你不止一个,像下图这样一个一个加进去就好了。  实际上.yaml文件需要的内容就这六个。 实际上.yaml文件需要的内容就这六个。  修改保存完之后就可以修改刚刚data的那一行了。 修改保存完之后就可以修改刚刚data的那一行了。  然后是epochs,训练轮数,根据自己情况修改即可。 最后是batch_size,如果你的显卡显存不是很大,图片大小也不是很小的话,建议把batch_size设置地小一点。我显卡现存是12G,设的32。你可以由大到小一点一点的改,直到不报OOM(Out Of Memory)的错误就行。 最后就可以运行train.py程序了。 训练过程可视化,yolov5里用的是wandb,但我相信不是所有人都可以用wandb的,如果你是每次运行到第29轮报错的话,可以看我的这篇文章。 毕业设计记录-yolov5的wandb报错,原因和解决方法(非屏蔽wandb) 另外还有其他俩个可视化方案。 毕业设计记录-Pytorch学习-tensorboardX训练过程可视化 毕业设计记录-Pytorch学习-HidderLayer训练过程可视化 然后是epochs,训练轮数,根据自己情况修改即可。 最后是batch_size,如果你的显卡显存不是很大,图片大小也不是很小的话,建议把batch_size设置地小一点。我显卡现存是12G,设的32。你可以由大到小一点一点的改,直到不报OOM(Out Of Memory)的错误就行。 最后就可以运行train.py程序了。 训练过程可视化,yolov5里用的是wandb,但我相信不是所有人都可以用wandb的,如果你是每次运行到第29轮报错的话,可以看我的这篇文章。 毕业设计记录-yolov5的wandb报错,原因和解决方法(非屏蔽wandb) 另外还有其他俩个可视化方案。 毕业设计记录-Pytorch学习-tensorboardX训练过程可视化 毕业设计记录-Pytorch学习-HidderLayer训练过程可视化
4、用训练好的权重来测试
训练完成之后,代码会打印出各种输出的文件夹路径。可以自行看训练结束后打印的东西。   我们训练好的权重就放在了weights文件夹下面,有俩个一个是精度最高的,一个是最后的。 我们训练好的权重就放在了weights文件夹下面,有俩个一个是精度最高的,一个是最后的。  我是使用的best.pt,将best.pt复制到yolov5代码文件夹里,如下图。 我是使用的best.pt,将best.pt复制到yolov5代码文件夹里,如下图。  然后把你要测试的图片全都放到这个目录下 然后把你要测试的图片全都放到这个目录下
 最后修改detect.py文件中我圈出来的部分,改成best.pt。 最后修改detect.py文件中我圈出来的部分,改成best.pt。  然后运行detect.py,运行结束之后,也会打印出输出的路径。 然后运行detect.py,运行结束之后,也会打印出输出的路径。 如下 如下  如果你想测试视频,按住shift,然后鼠标右击,打开power shell窗口输入如下指令。指令中的路径根据自己的来。 如果你想测试视频,按住shift,然后鼠标右击,打开power shell窗口输入如下指令。指令中的路径根据自己的来。 
|