| R语言复杂抽样5(2):线性回归 | 您所在的位置:网站首页 › tscore怎么算 › R语言复杂抽样5(2):线性回归 |
R语言复杂抽样5(2):线性回归
|
5.2 线性回归 5.2.1 最小二乘法计算的斜率作为总体估计汇总 线性回归总结了响应变量 Y 的平均值与一个或多个预测变量 X 的不同值的差异。Y的其他名称是“结果”或“依赖”变量,而 X 的其他名称是“独立”或“载体”变量。线性回归的工作模型分为两部分。模型的系统部分描述了平均值的差异
并且模型的随机部分表示 Y 的方差是恒定的
模型的不同部分具有不同的重要性级别。模型的系统部分定义了系数的含义:β是在 X 上相差 1 个单位的观测值在 Y 中的平均差异。模型的随机部分影响在估计α和β时观察的加权方式;它不会影响参数的含义,但会影响估计的精度。 在基于模型的分析中,有必要正确指定模型的随机部分以获得正确的标准误差,但我们所有的标准误差估计都是基于设计的,因此无论模型如何都是有效的。值得注意的是,有时在基于模型的回归分析中使用的“三明治”、“模型稳健”或“异方差一致”标准误差 [64, 1851] 几乎与我们将使用的基于设计的标准误差相同;主要区别在于分层的处理。 回归模型中的参数将通过采样加权最小二乘法进行估计。如果我们有完整的总体数据,我们会将α和β定义为使总体残差平方和最小的值
对于来自复杂样本的数据,我们可以使用抽样权重估计残差平方和的总体总和,
并通过使估计的总体总数最小化的值来估计α和β。 为了解释β由于 X 中每单位差异的 Y 平均差异与模型的拟合无关,因此考虑一个只有两个点 (X1 , y1 ) 和 (x2, y2) 的数据集。β的估计将是两点之间的线的斜率
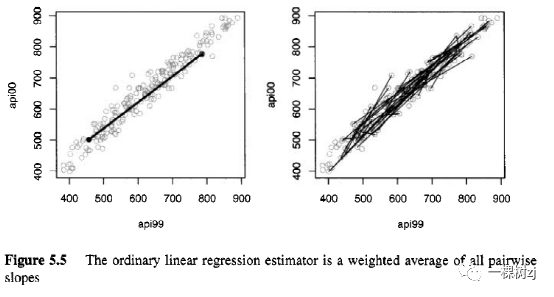
对于图 5.5 左侧面板中显示的线,x 的差值为 330,y 的差值为 277,给出了成对斜率为 0.839。
如果我们从一个简单的随机样本中得到 n 个点,那么就有 n(n - 1)/2 个这样的点对,所以我们可以计算 n(n - 1)/2 个不同的斜率,其中 βj, j 是直线的斜率在 (xi,yi) 和 (Xj,yj) 之间。图 5.5 显示了 50 条这样的线。这些估计值可以通过对它们求平均来组合,但是当 xi - x j 很大时会有更多信息,因此我们更喜欢加权平均。在图 5.5 中很明显,短线比长线具有更多的可变斜率。如果我们使用权重 W i j = (xj- X j ) 2 加权平均值将是
这正是来自普通线性回归的β的最小二乘估计。 对于来自复杂设计的数据,抽样权重使β的计算稍微复杂一些,但基本原理仍然认为回归系数估计可以解释为每单位 X 差异的 Y 平均差异,而不依赖于一切都基于对模型或拟合优度的假设。 5.2.2 总体总数的回归估计总体总数的比率估计量基于一个工作模型,该模型拟合具有零截距和单个预测变量的直线。对此的一个轻微概括是单独的比率估计量,用于分层设计,其中每个层的分母总数是单独已知的,而不仅仅是整个总体。其中计算每个层中总体总数的比率估计量,并将这些估计的层总数相加。单独的比率估计器对应于一个工作模型
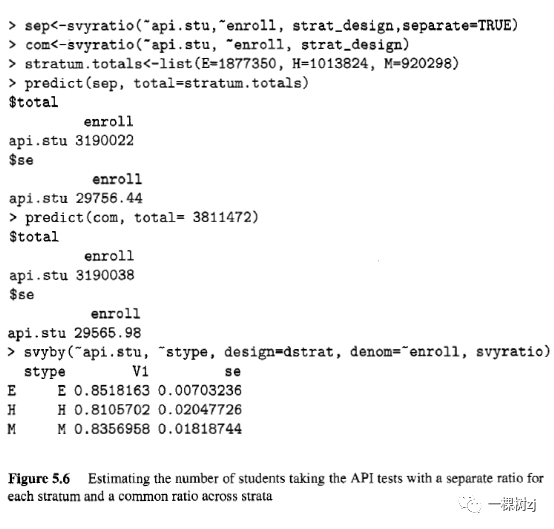
其中,βk 是层 k 的比率。在大样本量中,单独的比率估计量将比基于单一比率的估计量更准确,因为它使用更多的总体信息并且因为更多的估计参数允许工作模型更好地拟合数据。在第 5.1.3 节的示例中,单独比率模型的估计值和标准误与单一比率的估计值和标准误差几乎相同,因为参加 API 测试的学生比例在小学、中学和高中之间没有明显差异学校。图 5.6 显示了单独比率估算器的计算,以及学校类型之间的比率比较。
可以继续扩展工作模型以纳入更多总体信息并更好地拟合数据的过程。可以使用任何回归模型,只要工作模型中所有变量的总体总数都可用。第一步是将截距参数添加到用于比率估计的工作模型中,而不是强制截距为零。这一步很重要,因为它消除了一组选择不当的预测变量可能给出比仅使用 Horvitz-Thompson 估计量更差的估计的可能性。 我们看到,使用比率估计量,使用“英语语言学习者”的百分比作为分母变量来估计参加 API 测试的学生人数,其标准误差是 Horvitz-Thompson 估计量的两倍多。添加了截距的工作模型是
由于这两个变量几乎不相关,因此 ,β = 0 和 α 几乎与 api.stu 的估计总体均值相同。当β= 0 时,总数的回归估计量只是 Nα ,估计和标准误差几乎与 Horvitz-Thompson 估计量相同。这个结果很普遍。在回归模型中添加一个额外的变量来估计总体总数最多可以将标准误差少量增加。 这种少量的额外可变性来自估计另一个系数的需要,并且随着样本量的增加而变小。 最坏的情况发生在额外变量的系数近似为零时,因此在估计总数时实际上忽略了该变量。
例子:苏格兰的收入。通过指向内皮尔大学 PEAS 项目的链接,可以在网站上获得包含苏格兰数据的家庭资源调查的子集。这是对集群样本中家庭的 4695 个观察值的集合。我们可以使用图 5.7 中的代码定义调查设计并估计所有家庭、有孩子的家庭和单亲家庭的平均收入。所有家庭的平均每周收入为£483(标准误差£10.6),£611(标准错误£15.6)适用于所有有孩子的家庭,£277(标准错误£8.5)适用于单亲家庭。设计效果从所有家庭的2.9下降到单亲家庭的 1.01,表明对贫困家庭的过度抽样取得了成功。 总体总数可用于两个分类变量,即议会税收范围 (CTBAND) 和住房使用权 (TENURE),即人们是私人租房、从政府租房、拥有房屋或抵押房屋。图 5.7 定义了每个类别的指标变量,然后拟合线性模型并预测家庭总收入。可以将总数除以苏格兰的家庭数 (2236979) 以获得平均值。必须手动定义指标变量而不是使用 R 的类别自动处理的原因是 predict()函数需要单行数据来预测总数,因此需要为每个指标变量。 平均每周家庭收入的回归模型估计值为£483,标准误差为£7.5。通过使用已知的总体信息,标准误差已大大降低。令人惊讶的是,点估计是相同的。这是因为调查中的权重已经使用有关总体总数的信息进行了调整。大规模的全国调查通常会进行这些调整,下一章将介绍这些调整。 构建回归估计量以改进对有孩子的家庭和单亲家庭的平均每周收入的估计更加困难,因为这些子集的总体信息不可用。在第 7 章中,我们将看到如何使用这些信息,但也会看到它并没有提供太多额外的精度。 例子:美国大选。网站上的选举数据基于 2000 年和 2008 年美国总统选举的县级投票总数。在这两年中,这些都是初步总数,有些州没有按县细分,因此本示例中的数值结果与官方结果不完全匹配。同样的分析也可以用从 http 商业获得的高质量数据来完成:http : /www . uselectionatlas. org/的结论基本相同。 数据集中有 3049 个地区(县或州),巴拉克奥巴马的总票数为 65627076,约翰麦凯恩的总票数为 57545471。如果我们抽取 200 个地区的简单随机样本,我们可以通过以下方式定义调查设计对象
使用 Horvitz-Thompson 估计器,此设计的估计总数为奥巴马的 7700 万和麦凯恩的 5600 万,标准误差分别为 2900 万和 1300 万。
我们拥有所有地区 2000 年总统选举的数据,因此我们可以拟合线性回归模型并计算预测,如图 5.8 所示。线性回归模型的预测是奥巴马5800万,麦凯恩5100万,标准误差分别为600万和400万,精度提升非常大。 工作线性模型在回归线周围具有恒定的方差,但我们预计更大的区域会有更多的可变性。我们可以拟合一个工作模型,其中回归线周围的方差与拟合值成正比,因此有效地与该区域的投票数成正比。图 5.8 中的第三个代码块拟合这些工作模型并从中进行预测。由此得出的估计数为奥巴马 6100 万和麦凯恩 5400 万,标准误差分别为 410 万和 370 万,在准确性和标准误差上都得到了进一步提高。 这些改进并不令人惊讶:众所周知,以往选举中来自同一地区的“波动”是使用早期选举数据的最佳方式。这个例子是不切实际的,因为早期的选举回报不是随机样本,但当数据由于无响应而不是随机样本时,回归模型也可以帮助减少偏差。例如,假设我们的样本由印第安纳州和弗吉尼亚州的所有 225 个县组成,这两个州是最先报告结果的州之一。这些县对总体的代表性不是很强,我们预计会有相当大的偏见。奥巴马的估计总数为 4400 万,麦凯恩为 4100 万,标准误差为 600 万和 400 万,低估了总体总数和奥巴马的差值。根据线性回归模型估计,奥巴马为 6500 万,麦凯恩为 4900 万,标准误差为 800 万和 300 万。 使用回归模型和 2000 年选举的已知总体数据大大减少了偏差。奥巴马的投票现在被高估了,但只有大约一个估计的标准误差。 如果数据是概率样本,则来自工作回归模型的估计总体总数总是有效的,如果工作模型拟合良好,则将更加精确。如果数据不是概率样本,可能是因为无响应,如果工作模型拟合良好,估计值的偏差会更小,也可能更精确。在任一情况下,使用来自总体的已知信息可以更好地估计未知信息。我们将在第 7 章再次看到选举示例,说明使用已知总体数据的其他方法。本章的其余部分将重点介绍拟合回归模型以估计变量之间的关系。 5.2.3 模型选择的混杂和其他标准在工作线性回归模型中选择预测变量很重要,因为它会影响系数的含义。其中一些选择完全由分析师自行决定:您想比较吸烟者与不吸烟者还是比较以包年为单位的不同吸烟史?其他人则被科学问题的结构所迫:如果您想知道喝咖啡是否会影响血压,那么血压的比较只有在体重和年龄等因素相似的咖啡饮用者和非饮用者组之间进行时才有意义。 ` 有用的预测变量可以分为三类: 曝光感兴趣的:实质性问题是关于该变量与响应之间的关系。分析师可以自由选择如何总结这种关系,无论是作为类别之间的差异、线性趋势还是详细的暴露-反应曲线。选择将取决于样本大小、先验知识的水平以及结论的用途。 混淆变量:这些衡量了 X 和 Y 相关的其他无趣的原因。这些必须准确建模,以便控制无趣的关联。他们的系数通常对他们自己不感兴趣。 精度变量:这些与感兴趣的暴露无关,因此不会影响其系数的解释,但它们解释了 Y 的一些可变性,因此减少了标准误差。同样,它们的系数通常不是直接感兴趣的。精度变量只有在与响应有很强的关系时才有用;将剩余可变性降低 1% 或 2% 不太可能有任何实际好处。 不包括在这三个类别中的变量是那些与响应变量无关因此不相关的变量,以及那些受感兴趣的暴露或响应影响的变量,因此会掩盖正在研究的关系。 理想情况下,特定分析所需的所有变量选择都可以在获取数据之前完成。这并不意味着应该只拟合一个模型,因为找出哪些混杂因素影响大,哪些影响小是很有趣的。由于混杂因素和主要暴露变量的选择决定了系数的含义,因此不希望这种选择是随机的,这取决于一个特定样本中的值。基于数据的模型选择有时是有时是不可行的,因为有太多的变量可能是混杂因素,而数据不足以将它们全部包含在同一模型中。 这种在调查关联中选择模型的观点与构建预测模型的情况形成对比。灵活的模型选择程序连同对预测准确度的可靠估计可以为在新的 X 值下预测 Y 提供准确的模型,但可能不会导致包含正确的混杂因素来为系数提供有用的解释。预测模型,例如心血管疾病的 Framingham 风险评分或保险和信贷行业的精算风险评分,通常不是根据复杂的调查数据构建的,这里不再进一步讨论。 5.2.4 survey包中的线性模型函数 svyglm()将线性和广义线性模型拟合到存储在调查设计对象中的数据。函数语法几乎与基于模型的 glm()相同,只是 glm()的data参数被design参数替换。 svyglm()和glm()输出之间的主要区别在于svyglm()使用的采样加权最小二乘法不是最大似然。即使假设模型是正确的,也不可能使用似然比测试来比较模型,并且 svyglm()拟合的模型没有用于通用似然比测试函数 anova()的方法。原则上,可以将 Rao-Scott 检验从 2 x 2 表扩展到回归模型,但这仅适用于第 6.3 节中的对数线性模型。 应用于svyglm()对象的summary()函数将为模型中的每个系数提供Wald检验。对于系数集合(例如多类别因子变量的系数),请使用 regTermTest()计算 Wald 检验。 例子:膳食钠和钾和血压。众所周知,高盐饮食(和其他来源的钠)会增加血压,尽管这种关系的细节很复杂,并且在某些方面存在争议。我们将研究 NHANES 2003-2006 数据中钠和钾的消耗量与血压之间的关联。该数据集由新的“连续”NHANES 设计的两个两年波次组成,因此有必要下载 NHANES 2003-2004 和 NHANES 2005-2006 的总体统计、饮食、体型和血压数据,提取适当的变量,并合并数据集。
图 5.9 显示了加载八个文件并合并它们的代码。函数merge()用于合并四个数据文件,然后rbind()用于将两个结果数据集垂直粘贴在一起(当然,在检查变量确实正确对齐之后)。 还需要计算变量bpxsar 和bpxdar,即多次血压测量的平均值,这些变量在2003-2004 年的数据中提供,但在2005-2006 年没有提供。 需要针对组合数据调整权重。由于分析都被加权以对应于整个美国总体,因此合并的数据将代表总体的两个副本。通过将推荐用于饮食数据分析的重量变量wtdrd1减半来创建新的fouryeartwt变量。事实上,由于我们将仅估计均值,而不是总数,因此如果将 wtdrd1 用作权重而不重新缩放,则回归结果不会有任何差异。最后,使用推荐的 NHANES 设计的单阶段近似创建调查设计对象。
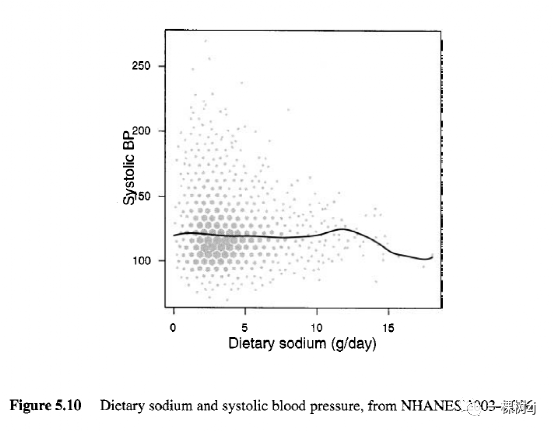
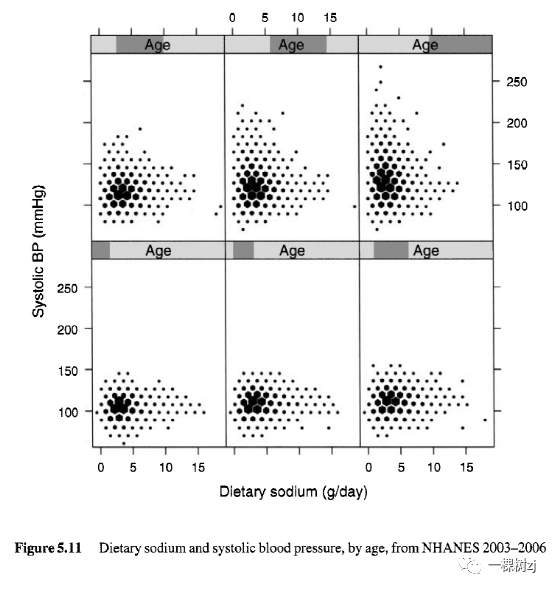
图 5.10 显示了收缩压和膳食钠数据,svysmooth() 生成了平滑的平均曲线。没有明确的关系,事实上,有迹象表明,随着钠摄入量的增加,血压会降低。回顾第 4 章中的血压和年龄图表,年龄很可能是一个重要的混杂因素。血压肯定会随着年龄的增长而升高,而且很可能不同年龄的人有不同的饮食习惯。图 5.11 显示了六个年龄组的血压与膳食钠之间的关系,现在有人建议增加,尤其是在年轻年龄组。
一个只有钠和钾作为预测因子的回归模型model0:
model0的summary()方法给出了一个包含标准误差和p值的表格。这给出了钠的 -0.69 mmHg/g/天和钾的 0.78 的点估计值,各自的 p 值为 0.0002 和 0.0068。由于年龄的混淆,这些估计值的方向错误,如图 5.10 中的图表。调整年龄的模型model1:
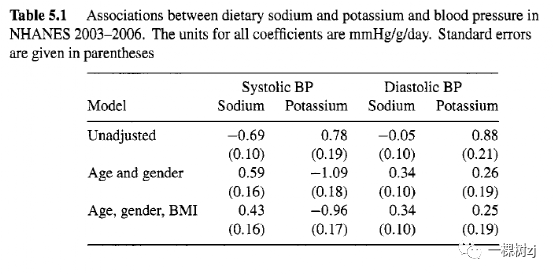
model1会逆转这种关联,钠的系数为 0.80,钾的系数为 -0.91,p 值小于 0.0001。其他重要的潜在混杂变量是性别 (RIAGENDR) 和一些肥胖的衡量指标,例如 BMI (BMXBMI)。表 5.1 显示了一系列模型中收缩压和舒张压的钠和钾系数。
可以使用 regTermTest()计算钠和钾影响的组合测试,如下所示其中 df=NULL 给出了残差自由度的默认选择,在这种情况下是层数减去设计中的 PSU 数。
尽管这些关联在统计上是显着的,但它们并不是很强:一克钠约等于2.5克盐,相当多,0.43 mmHg的血压差异非常小。由于各种原因,可能会错过更大的影响:饮食数据中存在大量测量误差,影响可能是非线性的,可能取决于食盐摄入量的历史而不仅仅是当前的摄入量,或者可能取决于年龄。可以使用可用数据检查其中一些可能性。
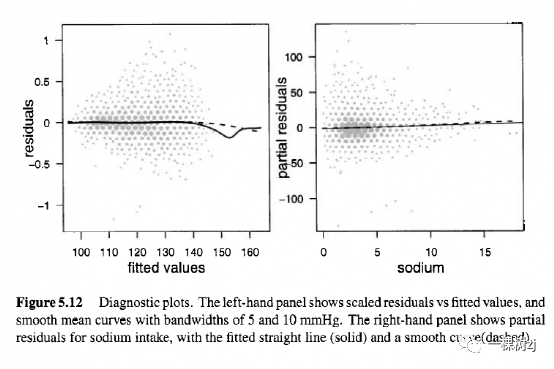
图 5.12 的左侧面板显示了收缩压最终模型的残差和拟合值,使用 svysmooth()估计了平滑的平均曲线。由于某些变量具有缺失值,因此有必要对调查设计对象进行子集化,以仅包含图形和平滑曲线的非缺失子群。模型对象有一个元素 na.action,它列出了由于缺失数据而被丢弃的观察数,因此des [-modellba.action,]是没有这些缺失值的设计子样本。拟合值中没有非线性的迹象,这可能表明混杂模型的指定错误。右侧面板显示了钠的偏残差。偏残差是通过将一个变量对残差的拟合贡献相加获得的,公式如下:
可以使用 resid(model1, "partial") 计算。如果模型指定错误,部分残差的均值将不遵循拟合关系,这可以使用平滑的均值曲线检测到。图中实线为拟合关系,斜率为0.43的直线。虚线是使用 svysmooth() 拟合的平均值,钠和血压之间的关系没有非线性的迹象。 对于未加权的数据,可以使用 plot () 方法和 termplot ()函数。这些函数也适用于 svyglm() 拟合的模型,但默认情况下,它们拟合的平滑曲线不会使用采样权重。要使用 termplot()和 plot()带有抽样加权模型,可以提供一个加权平滑器来代替通常的未加权平滑器,
这些图形仍然不会显示绘制点的抽样权重,但这些函数提供了获取诊断图初始版本的简单方法。 可以构建诊断图来评估交互作用,但仅拟合模型要容易得多。模型如下:
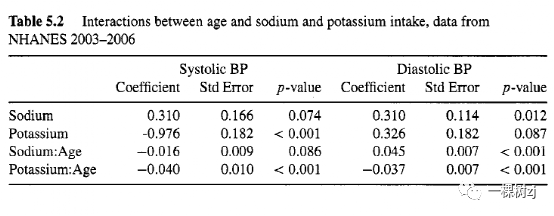
该模型添加了年龄与钠摄入量和钾摄入量之间的交互项。使用 ridageyr-40 的原因是年龄变量的零出现在有用年龄而不是零年龄。模型中的星号要求年龄的主效应和交互项。该模型中的系数和舒张压的类似系数在表 5.2 中给出。
使用这种年龄编码,表 5.2 中的主要影响是 40 岁时的关联,交互作用显示了随着年龄的增加,这种关系如何变化。钾和低血压之间的关联随着年龄的增长而加强,钠和高舒张压之间的关联也是如此。钠与较高收缩压之间的关联在年轻人中似乎更强。即使有这些趋势,估计的关联也不是很强。在80 岁时,交互模型给出的钾对收缩压的系数为 -2.6 mmHg/g/天,对于舒张压的系数为 - 1.2 mmHg/g/天。 测量误差是一个重要的可能性,因为准确评估饮食是出了名的困难。稍后通过电话进行了第二次饮食采访,查看 2005-2006 年第二次采访的数据表明,报告的钠和钾摄入量的差异通常很大。差异的方差是钾为 1.3 克/天,钾为 3.6 克/天(使用 svyvar (>) 计算,平均而言,第二次采访报告的钠消耗量较低(0.14 克/天)。这些结果表明,测得的人与人之间钠摄入量差异的一半以上可归因于测量误差,这是在考虑测量过程中的任何偏差之前。这种测量误差很可能部分掩盖了膳食钠和钾对血压的巨大影响。 5.3 回归模型需要加权吗?抽样权重在基于设计的分析中很重要,因为不等抽样会扭曲变量之间的关联,这必须在分析中进行纠正。由于回归模型使用混杂因素调整作为消除暴露和反应之间扭曲关联的一种方式,因此回归模型可能不需要采样权重是合理的。提出相同论点的另一种方法是,忽略抽样权重会得到一个回归模型,该模型适合于一些变量分布与实际总体中不同的总体。由于基于模型的回归主要用于揭示在群体中表现稳定的关联,因此应该可以在不使用采样权重的情况下估计这些关联。 DuMouchel 和 Duncan [43] 对一系列关于真实关系的假设的可能偏差进行了检查。 拟合没有采样权重的回归模型之所以具有吸引力,有两个原因。首先是并非所有软件都可以使用采样权重;这在今天已经不那么重要了。第二个现在仍然相关的原因是加权通常会降低精度。如果抽样权重是可忽略的,在有或没有权重的情况下估计都是有效的,加权估计将不太准确。 回归模型在不使用权重的情况下调整有偏抽样的能力有两个主要限制。第一个是用于构建权重的一些重要变量可能不可用,第二个是它们可能不适合包含在模型中。考虑加州健康访谈调查。权重取决于年龄、性别和种族/民族,还取决于家庭中的总人数、儿童数量和电话数量。CHIS 数据适用于检查社会经济变量与健康之间的关联,在这种情况下,回归模型可能需要针对年龄、性别和种族/民族进行调整。 调整家庭规模、家庭规模和电话数量可能是不可取的,因为这些很可能会受到所审查的社会经济变量的影响。 即使在没有明显原因导致未加权回归估计有偏差的情况下,谨慎仍然是明智的。相对较小的偏差足以超过标准误差的减少并给出总体不太准确的估计,并且无法从数据中可靠地检测到这种大小的偏差。 幸运的是,只要模型稳健的标准误差估计用于解释聚类和非常量方差,在拟合回归模型中是否使用采样权重通常几乎没有实际区别。例如,表 5.1 中收缩压、钠和钾的最终模型给出的钠和钾的系数分别为 0.43 和 -0.96,标准误为 0.16 和 0.17;未加权的线性模型给出 0.35 和 -0.99 作为系数,标准误差为 0.09 和 0.13。从这些分析中得出的结论没有真正的区别。当存在实质性差异时,可能表明少数有影响的观测值碰巧具有较大的抽样权重,因此无论是加权分析还是未加权分析都不是完全可靠的。在删除最有影响的观测值后重新拟合模型是一种有用的敏感性分析。 在病例对照设计中使用抽样权重是一个单独的问题,将在第 8.3 节中讨论。 |


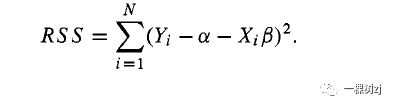
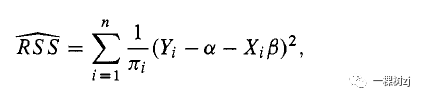
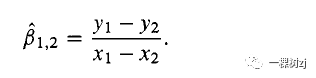
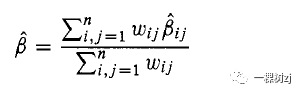
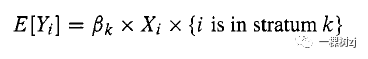
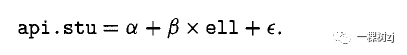




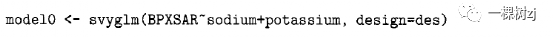


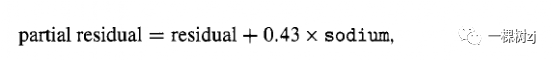


【本文地址】