| 毕业论文 | 您所在的位置:网站首页 › spss多元回归预测模型怎么做 › 毕业论文 |
毕业论文
|
今天回来改论文,我就顺道整理了一下前段时间做的一些分析。 在对问卷收集到的数据做处理的这些日子里,b站up主junlei老师的视频给了我很大的帮助,看了一遍又一遍,无论是结构方程还是回归,up都做了详细的视频教学。 本文配合junlei老师的视频效果更佳,junlei老师的公号里也有process插件以及调节的相关模型! 天刚突然想到我居然忘记在致谢里感谢junlei老师! 因为我的毕设采用的是回归分析,没有用结构方程,涉及的分析主要是描述性统计分析、问卷信度分析、效度分析、相关分析和回归分析(直接效应、中介效应、调节效应)。 关于问卷的信效度分析之前的文章里做过教程,这里就不再赘述。 有需要的铁子可直接点击下方链接跳转: 01、「描述性统计分析」 这部分主要就是对人口统计学变量或者控制变量部分做一个简要的概括说明。比如被调查者的年龄、职业、性别、使用时间的分布是什么样的,占到总人数的百分之几balabala。 然后可以适当地解释一下一些现象,比如使用时间都分布在晚上8-10点的原因,可能是大家吃过晚饭之后打开手机购物的概率更大balabala,能够自圆其说即可。 举例子: 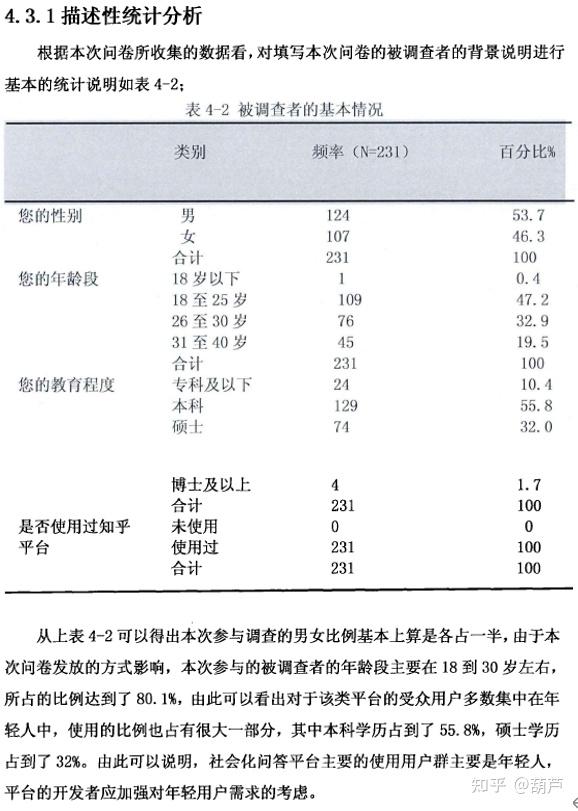 ▲文献来源:[1]胡守伟. 社会化问答平台用户持续使用意愿影响因素研究[D].安徽大学,2017.02、「相关分析」 ▲文献来源:[1]胡守伟. 社会化问答平台用户持续使用意愿影响因素研究[D].安徽大学,2017.02、「相关分析」 相关分析是回归分析的基础和前提,只有当变量相关时,进行回归分析寻求其相关的具体形式才有意义。相关分析就是去检验两两变量之间的相关性,相关性主要通过得出的相关系数(r)来看。 相关系数r有正负之分(表示正、负相关)。 取值在-1到1,r的绝对值在0.6以上,认为是强相关;0.3到0.6之间,可以认为是中等强度的相关。0.3以下,认为是弱相关。(不同的参考书有不一样的标准,但基本在这附近) 相关系数的得出主要两种方法:一种是Spearman相关系数,这种适用于变量是有序变量的情况,就比如大一、大二这种有等级的变量;另一种是Pearson相关系数,这就比较常见,适用于连续型变量,因为我们在做相关分析的时候是计算量表题的均值来表示变量,均值就变成了一个连续型的变量,因此本文在做相关分析的时候采用的Pearson。 用SPSS进行相关分析的步骤如下: 1.首先给所有变量的量表题算好均值,用来表示该变量。位置在转换-计算变量。   2.选择分析-相关-双变量,把模型中涉及的所有变量计算好均值,然后进行相关分析,选择皮尔逊相关系数,点击确定即可生成结果。   3.因为要对生成的结果做一个简单处理,我觉得junlei老师的方法特别好,先把spss的结果复制到Excel,该删的删,格式该换的换,再复制到word中。   至此相关分析结束。 03、「直接效应的回归分析」用回归分析和结构方程分析有很多不同,比如在做回归分析的时候一次只能有一个因变量。直接效应就是变量A可以直接影响B,那我们这次回归分析的目的就是要看这个影响关系显不显著,然后回归系数是多少。 具体步骤如下: 1.打开分析-回归-线性  2.在因变量中选择此次回归的因变量,在“块”的第一页放入控制变量:年龄、职业、性别、参与类别,点击下一页放入此次回归的自变量。  3.接着点击统计,选中R方变化量和共线性诊断。R方变化量主要是为了更明显的看出加入自变量之后模型的解释程度变化,变高说明更加解释度更好。而共线性诊断主要是通过膨胀因子VIF和容差来判断该回归方程是否存在多重共线性关系。 一般VIF值小于10且容差大于0.1时,回归方程不存在严重的多重共线性问题,模型可以接受。   4.等待结果 这里的模型1指预测变量只有控制变量的时候的模型,模型2是预测变量除了控制变量还加入了自变量的模型。 (1)首先看第2个表,可以看到加入自变量后R方变高,即加入3个自变量后模型的解释度从1.4%升到了54.1%,解释程度变高了。  (2)然后再看第3个表,主要是看F检验的结果,模型2的F值在0.001上显著,说明模型2是ok的,该模型在统计学上有意义。  (3)再看第4个表,这个表主要就是t检验、标准化系数和非标准化系数以及共线性统计了。  T检验的结果我们可以看到加入了期望确认度、知识互动、情感互动这三个变量之后呢,三个变量都通过了t检验(p |
【本文地址】