| 正则表达式中断言的使用以及简单例子 | 您所在的位置:网站首页 › shell正则表达式匹配连续数字是什么 › 正则表达式中断言的使用以及简单例子 |
正则表达式中断言的使用以及简单例子
|
原文链接: https://www.cnblogs.com/dogecheng/p/11466687.html https://www.cnblogs.com/he-qing-qing/p/11331080.html 版权声明:本文为转载文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 正则表达式断言 概念 零宽断言 匹配宽度为零,满足一定的条件/断言。零宽断言用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配 零宽断言分四种 先行断言(零宽度正预测先行断言) 表达式:(?=表达式)表示匹配表达式前面的位置先行断言的执行步骤是这样的先从要匹配的字符串中的最右端找到第一个ing(也就是先行断言中的表达式)然后 再匹配其前面的表达式,若无法匹配则继续查找第二个ing 再匹配第二个 ing前面的字符串,若能匹配 则匹配.*(?=d) 可c以匹配abcdefghi 中的abc 后发断言(零宽度正回顾后发断言) 表达式: (? 例子 (?:pattern)()表示捕获分组,()会把每个分组里的匹配的值保存起来,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推 (?:)表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来 import re a = "123abc456" pattern = "([0-9]*)([a-z]*)([0-9]*)" print(re.search(pattern,a).group(0,1,2,3)) pattern = "(?:[0-9]*)([a-z]*)([0-9]*)" print(re.search(pattern,a).group(0,1,2))
(?:pattern)匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。 正则表达式的匹配原理可以参考这篇文章: https://blog.csdn.net/lxcnn/article/details/4304651 这在使用 “或” 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 ‘industry|industries’ 更简略的表达式。 (?=pattern)正向肯定预查(look ahead positive assert),匹配pattern前面的位置。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。 简单说,以 xxx(?=pattern)为例,就是捕获以pattern结尾的内容xxx 例如,“Windows(?=95|98|NT|2000)“能匹配"Windows2000"中的"Windows”,但不能匹配"Windows3.1"中的"Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 (?=pattern)和(?:pattern)的区别可以参考:https://blog.csdn.net/shashagcsdn/article/details/80017678 (?!pattern)正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。 简单说,以 xxx(?!pattern)为例,就是捕获不以pattern结尾的内容xxx 例如"Windows(?!95|98|NT|2000)“能匹配"Windows3.1"中的"Windows”,但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 (? |
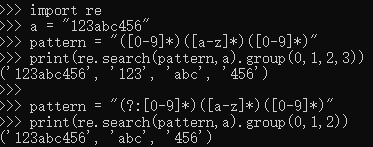 可以看到使用 (?:pattern) 后匹配的第一个 [0-9] 没有保存下来。python中group(0)返回整体。
可以看到使用 (?:pattern) 后匹配的第一个 [0-9] 没有保存下来。python中group(0)返回整体。【本文地址】