| R语言复杂抽样3:整群抽样 | 您所在的位置:网站首页 › r语言实现分层抽样 › R语言复杂抽样3:整群抽样 |
R语言复杂抽样3:整群抽样
|
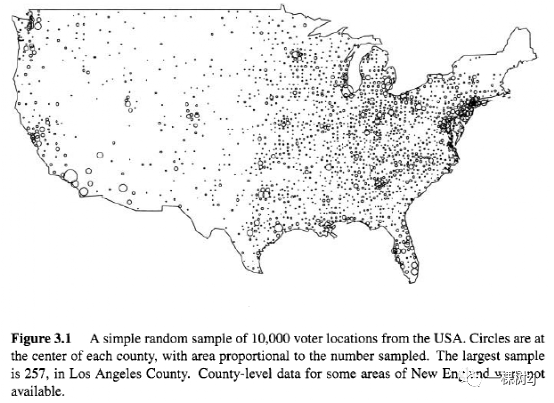
3.1介绍3.1.1为什么要集群:NHANES II设计 个人分层随机抽样对于电话访谈或邮寄问卷是可行的,但对于面对面访谈,它存在的问题是样本分布在全国。考虑NHANES的检查过程(examination) 。这涉及到详细的临床检查,以及必须储存和处理以进行分析的血样。国家卫生统计中心(National Center for Health Statistics,NCHS)在大型拖车中设立了移动检查中心(mobile examination centers,MEC),这些拖车可以在全国范围内从一个地点移动到另一个地点。 NHANES II 在四年内对 27,000 人进行了抽样。如果这27,000人是个人分层样本,则移动考试中心将不得不搬到数千个地点,交通占用了大部分可用时间和金钱。图3.1显示了来自美国的10,000名选民的样本。抽样个体居住在1184个不同的县,其中来自单个国家的最大数量是洛杉矶县的 257 个。
在NHANES II的设计中,人们认为后勤方面的考虑排除了80多个检查地点 [116]。80大小的样本显然是不够的,因此每个抽样地点都需要招募许多参与者。最终设计涉及对64个地点进行抽样,并计划在每个地点招募440名参与者。然后在每个位置应用相同的原则:每个被抽样的城市或县被分层为人口普查区,从每个区抽样被称为“段”的家庭组,对西班牙裔人口较多的区进行过抽样。 整群抽样,即抽样相对较少的人群,在涉及面对面访谈的大型调查中几乎是普遍的。与分层抽样相比,分层抽样提高了相同样本量的精度,整群抽样降低了指定样本量的精度,但可以增加指定成本的样本量和精度。相同样本量的精度降低的原因是集群中的人往往是相似的:采访同一城镇的另一个人比采访来自不同城镇的人提供的信息要少。 3.1.2 单级和多级设计整群抽样可用于招募整群集群的单阶段设计。对于教室、医疗实践或工作场所等集群,对整个集群进行抽样可能比尝试进行子抽样更方便。然而,更常见的是,在对集群进行抽样之后,在每个集群内进行二次抽样。第一阶段的集群被称为初级抽样单位或初级抽样单位(Primary Sampling Units, PSU),随后阶段的术语“二级抽样单位”( secondary sampling unit,SSU)、“三级抽样单位”在逻辑上遵循但没有被广泛使用。 一个元素的总体抽样概率是每个阶段抽样概率的乘积:如果一个集群以 1/100的概率被抽样,一个住户以1/1000的概率从该集群中抽样,则该住户的抽样概率为πi = 1/100 x 1/1000,抽样权重为100 x 1000 = 100000。以这种简单的方式计算概率需要一些抽样设计的技术条件。最重要的两个是每个人都必须在一个且只有一个集群中,并且任何给定集群的二次抽样概率不依赖于其他哪些集群被抽样。 也可以混合整群和个体抽样。由于调查的每一层都可以被认为是一个单独的独立样本,因此在一个层中进行单阶段抽样而在另一层中进行多阶段抽样并不困难。例如,苏格兰家庭调查将苏格兰分为高人口密度和低人口密度地区。在高密度地区对个体家庭进行分层随机抽样,在低密度区对个体家庭进行整群抽样。格拉斯哥单阶段抽样住户的抽样概率就是该层抽样住户数除以人口层数nh/Nh。阿伯丁郡住户的抽样概率分两个阶段进行抽样,它是整群概率与该集群内住户概率的乘积。 从数学和计算的角度来看,通过将每个采样集群视为进一步采样的总体,可以最容易地分析这种多级采样:估计的方差是每个抽样阶段的方差之和。例如,考虑NHANES II设计的简化版本,我们首先在32个层中选择64个区域,然后在每个区域内抽取440个人的简单随机样本。此设计的估计总数的方差可以分为两个来源:每个估计区域总数围绕该区域真实总数的方差,以及如果准确知道 64个采样区域中每个区域的真实总数将导致的方差。这些方差分量中的第一个可以直接从方程 2.2 中估计,第二个可以从相同方程的稍微修改版本中估计。多级采样的顺序视图作为子采样和在每个阶段添加额外方差在计算上比直接使用 Horvitz-Thompson 公式更简单,并且允许任意数量的采样阶段。至少自 1983 年 David Bellhouse 的程序TREES [7]以来,它已被用于软件中。 如果在第一阶段对集群进行替换采样,方差计算将取决于来自所有采样阶段的权重,但仅在第一阶段取决于集群成员资格。可以通过给出三个变量来指定抽样设计:抽样权重(sampling weights)、第一阶段的分层标识符(strata identifiers at stage one)和初级抽样单位标识符(PSU identifiers) 。由于大多数大型调查只对一小部分人口进行抽样,如果我们假设抽样的第一阶段是替换,那么我们预计标准误差的变化很小,结果证明这是正确的。此外,除了少数人为的例子,假设采样的第一阶段是有替换的,给出了一个保守的标准误差估计。当一些大型集群以概率1进行采样时,采样的第一阶段对这些集群没有任何不确定性。在单阶段近似中,初级抽样单位被视为分层,第二阶段抽样单位被视为初级抽样单位。 大型调查通常只报告第一阶段抽样的聚类和分层信息,甚至报告第一阶段的“伪”初级抽样单位和分层信息,这些信息可以很好地近似正确的标准误,但不对应完全符合抽样设计。除了计算简单之外,这种做法使得从调查数据中识别个人变得更加困难,如果发布完整的多阶段分层和聚类信息,这很可能是可能的。在第一阶段之后,我发现的唯一包含公开可用设计信息的大型调查是NHANES。完整的多阶段设计信息仍用于执行调查的机构的内部分析,但不可用于二次分析。 3.2 向 R指定多级设计对于单阶段集群样本,或被视为具有替换的单阶段样本的多阶段样本,在svydesign()函数中的唯一区别是 id= ~1,被指定PSU标识符的公式替换。对于NHANES III数据,指定方式为
sdppsu6和 sdpstra6是为单阶段分析定义的“伪”-PSU和层标识符。参数 nest=TRUE用于指示PSU标识符需要解释为嵌套在层中:相同的PSU id 在不同层回收。如果没有 nest=TRUE,svydesign() 将检查 PSU 是否重叠超过一个层,如果重叠则报告错误。如果设计包括有限的总体校正信息fpc,则总体规模是层中的抽样单位数。例如,在从 API 总体中抽取 15 个学区的简单随机样本并观察这些学区中的所有学校的设计中,总体规模为 757,即加利福尼亚学区的数量。 在使用有关有限总体规模信息的多阶段样本中,id、strata 和 fpc 参数必须为每个抽样阶段指定一个变量。如果某些阶段未分层而其他阶段已分层,则定义一个具有单一值的变量作为未分层阶段的层标识符。fpc参数的总体规模是被抽样的总体规模:当前集群或集群内层中的下一阶段抽样单元的数量。例如,考虑 API总体的两阶段设计,该设计对40个学区和每个学区的5所学校(或所有学校,如果少于 5 所)进行抽样。该设计在第一阶段的规模为 757,与加利福尼亚的学区数量相同。在第二阶段,抽样是一个地区内的学校,所以规模是该地区的学校数量。每个参数采用一个包含两个项的模型公式,每个采样阶段一个项。与个体抽样一样,如果可以从总体规模中计算出权重,则无需指定权重。
当总体层只有一个潜在初级抽样单位时,该层的抽样比例必须为100%,否则它将为0%。该层对第一阶段的方差没有贡献,但可能对采样后期阶段的方差有贡献。在这种情况下,忽略该层中抽样的第一阶段并将第二阶段,即单个初级抽样单位内的抽样,作为方差计算的第一阶段是有帮助的。当使用方差的单级近似时,忽略采样的第一阶段特别有用。 如果总体层有多个潜在初级抽样单位但只有一个被抽样,则设计违反了第1.1.2节中给出的条件。如果层中的两个人在不同的初级抽样单位中,他们不能同时被抽样,所以对于某些对,成对抽样概率 πij 为零。具有单一抽样初级抽样单位的分层确实出现在调查中,原因有二。第一个原因是在执行预期设计时无响应或其他问题,第二个原因是故意尝试通过精细分层来减少方差。 处理只有一个初级抽样单位的层的最佳方法是将其与另一层结合,该层是根据研究完成前可用的人口数据选择的相似层。方差估计将是保守的:与在设计阶段合并分层的情况相比,调查中的人口估计将更准确。一些 NHANES 研究使用这种方法,每个层取一个初级抽样单位,然后创建具有两个初级抽样单位的伪层进行分析。至关重要的是,要组合的层的选择取决于人口数据而不是样本数据:基于样本数据的相似性组合层将导致反保守方差估计。 当具有单个 PSU 的层无法(或至少尚未)组合以解决问题时,survey包的默认行为是报告错误,但它也提供了两个近似值来解决问题。这些由 options(survey.lonely.psu) 控制。设置 options(survey.lonely.psu = "adjust" ) 给出了一个保守的方差估计器,它使用来自总体均值而不是来自层均值的残差,以及options (survey.lonely.psu = “average”) 设置对具有多个 PSU 的所有层的平均值的方差贡献。adjust选项是保守的。aveage选项适用于因无响应而导致lonely PSU且层大致可比的设计,例如,每个层采样两个人的设计。一个子群中只有一个 PSU 的层可能会导致方差估计不佳,并给出警告。相同的调整适用于每个抽样级别,例如,只有一个 SSU 的第二阶段分层。 当一个层中只有一个总体初级抽样单位时,从有限总体校正信息中可以清楚地看出抽样比例为100%。如果由于某种原因未提供人口规模信息,则可以使用选项从方差计算中删除单 PSU 层(survey.lonely .psu = "removet")。 3.2.2 单阶段近似有多好?1992 年的NHANES是为数不多的包含多阶段抽样信息的公开数据集之一。但有限人口信息仍然相当不完整,仅说明某些自我代表的人口阶层只有一个 PSU,然后以概率 1 对其进行抽样。NCHS分析指南[117]建议将所有第二阶段抽样的总体规模表示为无限,而在第一阶段抽样中将人口规模表示为 1 或无限。对于无法处理两阶段设计的软件,另一种分析是没有有限总体校正的单阶段分析,使用“伪”初级抽样单位和层信息。
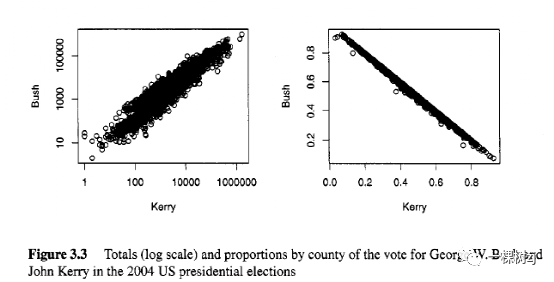
图 3.2 显示了用于声明设计和执行一项分析的代码。两阶段设计的有限总体修正被指定为抽样分数 n N ,而不是总体规模 N ,因为总体规模是无限的。对于有限的人口规模,任何一种形式的修正都是允许的,但它们不能在对 svydesign()的同一调用中混合使用。在这两种设计中,抽样权重都不能从总体规模中计算出来,因此它们在 weights 参数中指定。 定义两阶段设计时会给出警告,表明给出的人口规模大得令人难以置信。在这种情况下,使用无限的人口规模,可以忽略警告。最后两行要求估计身高(以英寸为单位)、体重(以磅为单位)、急性医疗状况的数量和医疗状况的总数。 两阶段分析给出与单阶段分析相同的估计均值,因为抽样权重相同,但给出的标准误差略小(且更准确) 。估计标准误差的差异约为 10%,在大型公共使用数据集中,接受标准误差膨胀 10% 似乎是合理的,以换取单阶段近似的增加的简单性和更高的机密性。 3.2.3 多阶段样本的重复权重单阶段整群抽样设计的重复权重是通过将群视为单位并应用与个人抽样相同的方法(第 2.3 节)来产生的。BRR 方法现在适用于每个层中有两个初级抽样单位的设计,并从每个层创建一个具有一个初级抽样单位的半样本。jackknife 方法依次将每个PSU的权重设置为零。引导程序重新采样PSU而不是个人。 对于具有小采样分数的多级设计,可以使用与线性化方法相同的单级无替换近似。对于具有大采样分数的多级设计,选择较少,Funaoka 等人提出了一种选择[51],但目前尚未在survey包中实施。 使用研究设计者提供的重复权重对于多阶段和单阶段样本的工作方式相同:在对svrepdesign()的调用中简单地提供了复制权重和缩放值。使用as.svrepdesign()从调查设计对象创建重复权重时,设计被视为单阶段,折刀、BRR 或引导程序应用于 PSU 以创建重复权重。 3.3 按大小抽样一个古老的小学笑话问:“为什么白羊比黑羊吃得更多?”;答案是“白羊多于黑羊”。 任何变量的总数往往随着人口规模的增加而增加,这一事实意味着用于估计一个变量的最佳整群设计可能对其他变量也有好处。这种影响的强度如图 3.3 所示,该图基于乔治·W·布什的县级投票数据。布什、约翰克里和拉尔夫纳德在 2004 年的美国总统选举中。投票给布什和克里的比例几乎完全呈负相关,但投票给两位候选人的总数呈正相关,为 0.88。
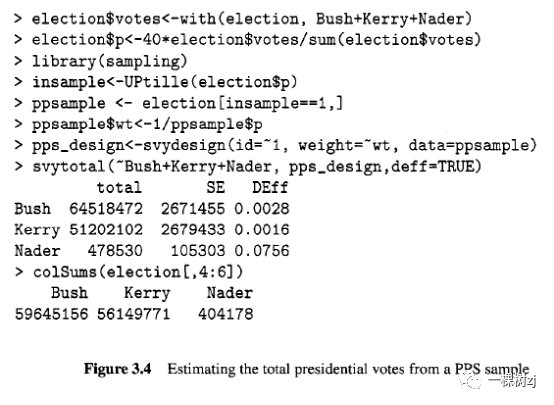
在非分层抽样中,X 的估计总和的方差取决于 X 的样本方差。如果可以选择与 Xi 成正比的 πi,则该方差将为零。这将需要知道整个群体的 Xi(最多一个比例因子),因此准确估计是可能的也就不足为奇了。更现实的是,如果πi大约与 Xi 成正比,则估计总数的方差将很小。 如图 3.3 所示,这对于整群是可能的,因为选择与集群中的总体规模成正比将使其与范围广泛的变量的集群总数大致成正比。概率与规模成比例 (PPS) 整群抽样在调查设计中非常重要, 以至于 PPS 通常用作任何非多阶段分层随机抽样设计的通用术语。Tille[172]描述了 PPS 设计的创建和使用;较早的参考文献是 Brewer 和 Hanif [22]。 不幸的是,无替换 PPS 采样的分析需要知道配对采样概率πij 。这些通常不会在数据集中提供,计算它们需要知道总体中所有集群的大小,而不仅仅是采样的集群,并且知道使用什么算法来抽取样本。在撰写本文时,survey包只能使用单级带置换近似来分析 PPS 设计。 使用sampling包 [173] 和 Tille的 PPS 无替换抽样拆分方法,我们可以从 4600 人口中抽取 40 个县的样本,概率与投票总数成正比。图 3.4 显示了代码和结果。
在这个例子中,我们可以使用所有县的已知大小计算联合采样概率 nij 和 Horvitz-Thompson 标准误差估计量的近似值(Hartley 和 Rao [59])(代码未显示,但在网站上) 。 这给出了Bush的 2,620,000、Kerry 的 2,530,000 和 Nader 的 103,000 的标准误差。我们还可以使用sampling包中的函数UPtille()计算真正的联合采样概率。基于真实联合概率的Horvitz-Thompson估计器给出了Bush的 2,600,000、Kerry的2,520,000和Nader的102,000 的标准误差。Hartley-Rao 近似与具有真实联合概率的结果没有显着差异,并且需要几秒钟而不是几小时来计算。单阶段替换近似似乎高估了主要候选者的标准误差约 6% 和纳德的约 2.5%。有限总体规模的影响大于相同规模的简单随机样本的影响,因为某些抽样概率非常大:洛杉矶县的 πi = 0.9。 重要的是要记住,这些只是来自单个样本的估计值。对单级替换近似影响的真实评估需要进行模拟研究,例如练习 3.2。模拟确实会得出相同的结论:单级近似是可以接受的准确度,尽管不如分层多级设计准确。 家庭资源调查在三个抽样阶段的第一个阶段使用邮政编码部门的 PPS 样本。使用集群规模数据的另一种方法是按规模对县进行分层并抽取分层随机样本。NHIS 和 NHANES 样本使用此策略,其中最大的集群具有πi = 1。
图3.5显示了美国选举数据中分层设计的模拟代码和结果。该设计确定地对最大的五个县(位于洛杉矶、芝加哥、休斯顿、凤凰城和底特律及其周边地区)进行抽样,然后在接下来的 95,15 个县中抽取 5 个,在剩下的 3600 个中抽取 15 个。函数 one.s i m()进行一次模拟,对replicate()的调用重复了10,000 次,运行需要几分钟。结果存储在 many.sims 中,是一个包含 6 行 10,000 列的矩阵。 第一次调用 apply0 计算前三行中每一行的平均值:估计总数。这些接近于图 3.4 中所示的真实值。第二个调用计算估计总数的标准偏差,第三个调用计算估计标准误差的平均值。这两个结果相似,表明标准误差计算给出了准确的结果。此设计的标准误差大约是 PPS 设计的两倍,因为集群大小信息的使用效率不高。可以恢复大部分损失的效率,如第 5.1.3 节和第 7 章所示。还值得注意的是,平均估计标准误差低估了估计总数的实际标准偏差,Nader 和 Kerry 分别低 10% 和 5%。提高效率的相同技术也将倾向于减轻对标准误差的低估。 3.3.1 抽样集群的信息丢失整群抽样,甚至与规模成正比的抽样,每次观察的精度都低于抽样个体。对于所有集群具有相同数量的个体 m 的单阶段集群样本,设计效果是
其中 p 是集群内相关性。尽管 p 可能非常小,但 m 可能非常大。例如,如果 m = 100 且 p = 0.01,则设计效果将为2。该公式对于定量预测不是很有用,因为 p 将是未知的,但它表明了整群抽样的一般影响。
对于更复杂的多级设计,设计效果的质量类似增加。例如,考虑来自 API 总体的两个多阶段样本。第一个是 15 个学区所有学校的聚类样本,第二个是 3.2 节中描述的两阶段聚类样本。图 3.6 显示了四个变量均值的设计效果:学业成绩指数(api00)、接受补贴膳食(meals)的学生比例、“英语语言学习者”的比例(ell)和总入学人数(enroll)。所有这些变量的设计效果都非常大,反映了学区之间在社会经济地位、学校规模和学校表现方面的巨大差异。聚类之间的较大差异会降低聚类抽样的效率,因为样本中未表示的聚类将与样本中表示的聚类不同。
图 3.7 显示了来自 2007 年行为风险因素监测系统数据的两个变量的估计比例。调查设计对象使用存储在 SQLite 数据库中的数据,并通过 RSQLite 包 [66] 访问,如 D.2.2 节所述。X_FV5SRV根据一组关于特定食物的问题,报告参与者每天是否食用五份或更多份水果和蔬菜(2=是,1=否)。X-CHOLCHK 报告参与者是否进行了胆固醇测量(1=五年内,2=五年多前,3=从未)。只有 24% 的人食用了推荐量的水果和蔬菜,但大约74%的人最近进行了胆固醇检查。这些变量的设计效果范围从 4.7 到 7.1。BRFSS数据集中的PSU并不是设计中真正的PSU,它们是 100 个电话号码的块,但设计效果仍然显示这些变量存在强烈的地理差异。 3.4 重复测量收入和计划参与调查 (SIPP) 是一项面板调查,随着时间的推移对同一个人进行重复测量。每个小组都被跟踪多年,小组的子集参与了为期四个月的随访。该网站有 1996 年小组第一波的变量子集,从 1995 年末或 1996 年初开始,每四个月对 36730 户家庭进行一次访谈。数据以每月形式记录,因此每次访谈都会在数据集中产生四个为期一个月的记录。这些住户是在两阶段样本中招募的。 第一阶段抽取了322个县或县组作为初级抽样单位;第二阶段抽样调查这些初级抽样单位内的住户。公共使用数据不包含PSU信息;相反,该文件具有用于方差估计的“伪层”和“伪 PSU”。 文件sip.db包含在1996年SIPP小组第1波中测量的一些变量。这是一个包含两个表的 SQLite 数据库文件,家庭用于家庭级分析,wave1sub 用于个人级分析。图 3.8 显示了如何向 R 描述设计。
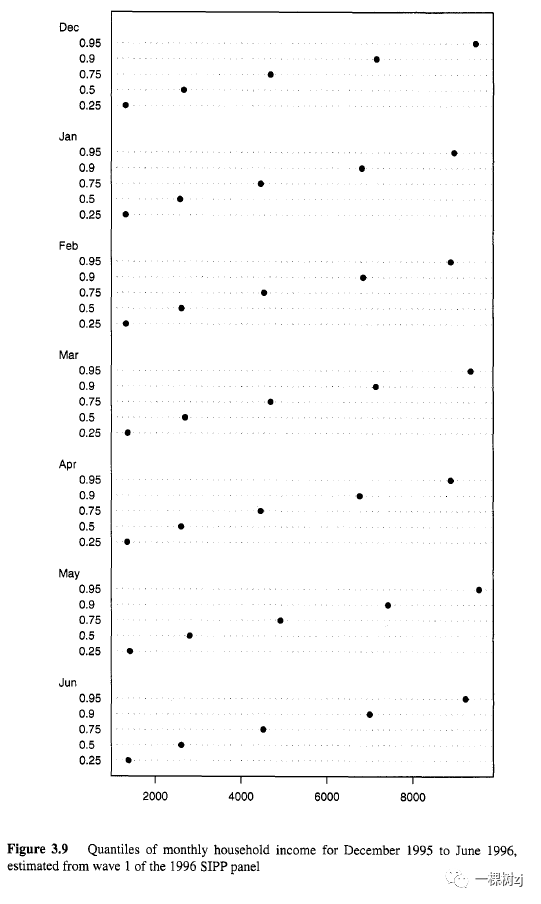
在对这些数据进行基于模型的分析中,重要的是要描述和建模一个人或家庭在四个月的数据中的相关性。在基于设计的分析中,不需要做任何特别的事情,住户内的聚类就像抽样中的另一个聚类阶段,并自动纳入分析。重要且可能具有挑战性的是在纵向分析中使用正确的权重。 在这个 SIPP 示例中,权重变量 whfnwgt 对于估计单个月的家庭级变量总数是正确的。这些权重对于计算月份之间的差异也是正确的,因为两个月之间的差异是估计整个总体的两个版本之间的差异。另一方面,在使用所有四个月的观察结果来估计单个人口总数以提高精度时,有必要将权重除以四,因为每个家庭都有四次代表。幸运的是,将所有权重除以相同的常数对其他统计量(例如中位数、均值或回归系数)的估计没有影响,因此可以忽略这种重新缩放。图 3.9 显示了根据 1995 年 12 月至 1996 年 6 月的数据集估算的月收入分位数。分位数在 7 个月期间似乎相当稳定,尽管有人建议较高的分位数从 12 月到 1 月减少,即高收入的人在 12 月的收入更高。这是有道理的,因为奖金或零售业务的收入。
当结合 SIPP 或多年的 NHANES 时,情况是相似的。如果分析估计了一个总数,则有必要重新调整抽样权重,以便将它们添加到总体的一个副本中,如果分析估计随着时间的推移存在差异,则不需要重新调整。对 NHANES 多年的分析与 SIPP 的多个浪潮之一之间存在重要区别。由于 SIPP 是一项小组研究,不同的数据收集波指的是同一个人并且是相关的;在 NHANES 中,不同年份的数据收集对不同的人进行了抽样,抽样比例足够低,可以认为数据集是独立的。当组合同一面板的两个波时,确保 PSU 适当匹配很重要,但在组合两组独立的数据收集时,重要的是确保 PSU 已编码,以便软件知道它们是不同的。 当两个样本部分重叠时,情况会更加复杂。在这种情况下的设计和估计细节超出了本书的范围,但提到一些挑战是有用的。首先,需要确定估计的目标是群体特征的差异还是个体特定变化的总结。为明确区分,请考虑估计相隔 10 年进行的两次调查的平均年龄差异。整个人口在这两个时间点的平均年龄将相当相似,例如,美国人口平均年龄从1990年到2000年增加了大约一年。然而,出现在两个样本中的任何人在较晚的样本中都将比较早的样本年长10岁。人内的平均差异为 10 年,但总体上的差异仅为一年。其次,即使目标是估计总体均值的差异,在两个样本中测量的个体比仅在样本中测量的个体更能提供有关变化的信息,因此仅使用抽样权重可能效率很低。有关两个重叠样本的一些设计和估计问题的详细信息,请参见 [151]的第 9 章及其中的参考资料。 |
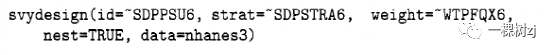
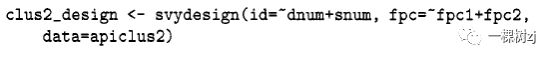


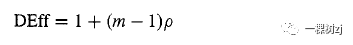



【本文地址】