| 【Python】向量空间模型:TF | 您所在的位置:网站首页 › python建立svm模型代码 › 【Python】向量空间模型:TF |
【Python】向量空间模型:TF
|
一、部分理论介绍
向量空间模型(VSM:Vector Space Model) TF-IDF(term frequency–inverse document frequency) TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)
其他理论部分请依据关键词自行探索研究。 二、TF-IDF相关实例1、题目 Q:“gold silver truck” D1:“Shipment of gold damaged in a fire” D2:“Delivery of silver arrived in a silver truck” D3:“Shipment of gold arrived in a truck” 基于TF-IDF向量化方法,求文档Q与文档D1、D2、D3相似程度。 2、分析过程 在这个文档集中,d=3。 lg(d/dfi) = lg(3/1) = 0.477 lg(d/dfi) = lg(3/2) = 0.176 lg(d/dfi) = lg(3/3) = 0
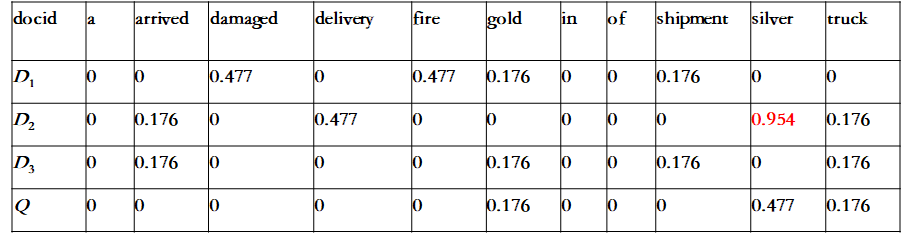
3、代码分享: 直接上完成代码: import numpy as np import pandas as pd import math #1.声明文档 分词 去重合并 D1 = 'Shipment of gold damaged in a fire' D2 = 'Delivery of silver arrived in a silver truck' D3 = 'Shipment of gold arrived in a truck' split1 = D1.split(' ') split2 = D2.split(' ') split3 = D3.split(' ') wordSet = set(split1).union(split2,split3) #通过set去重来构建词库 #2.统计词项tj在文档Di中出现的次数,也就是词频。 def computeTF(wordSet,split): tf = dict.fromkeys(wordSet, 0) for word in split: tf[word] += 1 return tf tf1 = computeTF(wordSet,split1) tf2 = computeTF(wordSet,split2) tf3 = computeTF(wordSet,split3) print('tf1:\n',tf1) #3.计算逆文档频率IDF def computeIDF(tfList): idfDict = dict.fromkeys(tfList[0],0) #词为key,初始值为0 N = len(tfList) #总文档数量 for tf in tfList: # 遍历字典中每一篇文章 for word, count in tf.items(): #遍历当前文章的每一个词 if count > 0 : #当前遍历的词语在当前遍历到的文章中出现 idfDict[word] += 1 #包含词项tj的文档的篇数df+1 for word, Ni in idfDict.items(): #利用公式将df替换为逆文档频率idf idfDict[word] = math.log10(N/Ni) #N,Ni均不会为0 return idfDict #返回逆文档频率IDF字典 idfs = computeIDF([tf1, tf2, tf3]) print('idfs:\n',idfs) #4.计算tf-idf(term frequency–inverse document frequency) def computeTFIDF(tf, idfs): #tf词频,idf逆文档频率 tfidf = {} for word, tfval in tf.items(): tfidf[word] = tfval * idfs[word] return tfidf tfidf1 = computeTFIDF(tf1, idfs) tfidf2 = computeTFIDF(tf2, idfs) tfidf3 = computeTFIDF(tf3, idfs) tfidf = pd.DataFrame([tfidf1, tfidf2, tfidf3]) print(tfidf) #5.查询与文档Q最相似的文章 q = 'gold silver truck' #查询文档Q split_q = q.split(' ') #分词 tf_q = computeTF(wordSet,split_q) #计算Q的词频 tfidf_q = computeTFIDF(tf_q, idfs) #计算Q的tf_idf(构建向量) ans = pd.DataFrame([tfidf1, tfidf2, tfidf3, tfidf_q]) print(ans) #6.计算Q和文档Di的相似度(可以简单地定义为两个向量的内积) print('Q和文档D1的相似度SC(Q, D1) :', (ans.loc[0,:]*ans.loc[3,:]).sum()) print('Q和文档D2的相似度SC(Q, D2) :', (ans.loc[1,:]*ans.loc[3,:]).sum()) print('Q和文档D3的相似度SC(Q, D3) :', (ans.loc[2,:]*ans.loc[3,:]).sum())4、部分结果 文档1的词频: 1、文本特征抽取的向量空间模型(VSM)和TF/IDF方法 2、06_TF-IDF算法代码示例 3、用20 newsgroups数据来进行NLP处理之文本分类 4、Python Set union() 方法 |



 逆文档频率idf:
逆文档频率idf:  tf-idf向量空间:
tf-idf向量空间:  4篇文档组成的向量空间:
4篇文档组成的向量空间:  相似度SC:
相似度SC: 
【本文地址】
公司简介
联系我们