| 一些常用的语音特征提取算法 | 您所在的位置:网站首页 › lpc测试 › 一些常用的语音特征提取算法 |
一些常用的语音特征提取算法
|
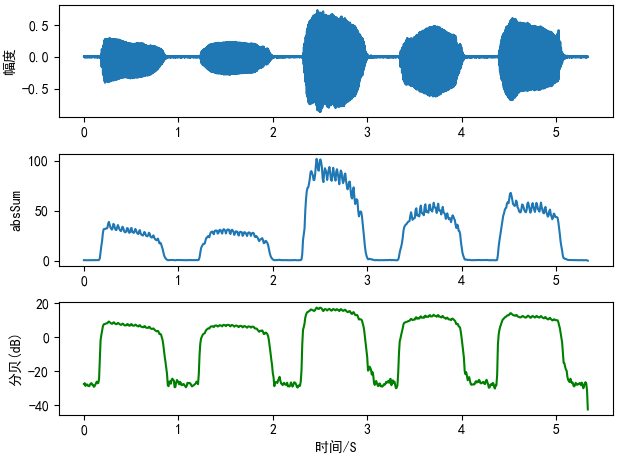
论文地址:Some Commonly Used Speech Feature Extraction Algorithms 前言语言是一种复杂的自然习得的人类运动能力。成人的特点是通过大约100块肌肉的协调运动,每秒发出14种不同的声音。说话人识别是指软件或硬件接收语音信号,识别语音信号中出现的说话人,然后识别说话人的能力。特征提取是通过将语音波形以相对最小的数据速率转换为参数表示形式进行后续处理和分析来实现的。因此,可接受的分类是从优良和优质的特征中衍生出来的。Mel频率倒谱系数(MFCC)、线性预测系数(LPC)、线性预测倒谱系数(LPCC)、线谱频率(LSF)、离散小波变换(DWT)和感知线性预测(PLP)是本章讨论的语音特征提取技术。这些方法已经在广泛的应用中进行了测试,使它们具有很高的可靠性和可接受性。研究人员对上述讨论的技术做了一些修改,使它们更不受噪音影响,更健壮,消耗的时间更少。总之,没有一种方法优于另一种,应用范围将决定选择哪种方法。 本文主要的关键技术:Mel频率倒谱系数(MFCC),线性预测系数(LPC),线性预测倒谱系数(LPCC),线谱频率(LSF),离散小波变换(DWT),感知线性预测(PLP) 1 介绍人类通过言语来表达他们的感情、观点、观点和观念。语音生成过程包括发音、语音和流利性[1,2]。这是一种复杂的自然习得的人类运动能力,在正常成年人中,这项任务是通过脊椎和颅神经连接的大约100块肌肉协调运动,每秒发出大约14种不同的声音。人类说话的简单性与任务的复杂性形成对比,这种复杂性有助于解释为什么语言对与神经系统[3]相关的疾病非常敏感。 在开发能够分析、分类和识别语音信号的系统方面已经进行了几次成功的尝试。为这类任务所开发的硬件和软件已应用于保健、政府部门和农业等各个领域。说话人识别是指软件或硬件接收语音信号,识别语音信号中出现的说话人,并在[4]之后识别说话人的能力。说话人的识别执行的任务与人脑执行的任务类似。这从语音开始,语音是说话人识别系统的输入。一般来说,说话人的识别过程主要分为三个步骤:声音处理、特征提取和分类/识别[5]。 在提取语音[6]的重要属性并进行识别之前,对语音信号进行去噪处理。特征提取的目的是通过给定数量的信号分量来描述语音信号。这是因为声学信号中的所有信息处理起来都过于繁琐,有些信息与识别任务无关[7,8]。 特征提取是通过以相对较低的数据速率将语音波形转换为参数表示形式进行后续处理和分析来完成的。这通常称为前端信号处理[9,10]。它将经过处理的语音信号转换成一种简洁而有逻辑的表示形式,比实际信号更有鉴别性和可靠性。前端是序列中的初始元素,后续特征(模式匹配和speaker建模)的质量受到前端[10]质量的显著影响。 因此,可接受的分类是从优良和优质的特征中衍生出来的。在当前自动说话人识别(ASR)系统,特征提取的过程通常被发现表示相对可靠的几个条件相同的语音信号,即使在环境条件改变或发言人,同时保留的部分描述语音信号中的信息(7、8)。 特征提取方法通常为每个语音信号提取一个多维特征向量。语音信号的参数化表示方法有很多种,如感知线性预测(PLP)、线性预测编码(LPC)和Mel-频率倒谱系数(MFCC)。MFCC是最有名和非常受欢迎的[9,12]。特征提取是说话人识别中最相关的部分。语音特征在区分说话人与其他[13]人的过程中起着至关重要的作用。特征提取在不损害语音信号[14]功率的前提下,降低了语音信号的幅度。 在特征提取之前,首先进行预处理阶段的序列。预处理步骤是预强调。这是通过一个FIR滤波器[15]来实现的,它通常是一个一阶有限脉冲响应(FIR)滤波器[16]。接着是帧阻塞,这是一种将语音信号分割成帧的方法。它消除了存在于语音信号[17]的开始和结束处的声学接口。 然后将加框的语音信号加窗。带通滤波器是一个合适的窗口[15],用于最小化每帧开始和结束时的不均匀性。最著名的两类窗户是汉明窗和矩形窗[18]。它增加了谐波的锐度,消除了信号的不连续,减少了帧零的开始和结束。它也减少了由重叠[17]形成的光谱失真。 时域特征 音量absSum def calVolume(wave_data, frame_length, overlap): wlen = len(wave_data) step = frame_length - overlap frameNum = int(math.ceil(wlen * 1.0 / step)) # 帧数 volume = np.zeros((frameNum, 1)) for i in range(frameNum): curFrame = wave_data[np.arange(i * step, min(i * step + frame_length, wlen))] # 当前帧 # curFrame = curFrame - np.median(curFrame) # False curFrame = curFrame - np.mean(curFrame) # 零对齐 volume[i] = np.sum(np.abs(curFrame)) return volumeLog10的平方和 def calVolumeDB(wave_data, frame_length, overlap): wlen = len(wave_data) step = frame_length - overlap frameNum = int(math.ceil(wlen * 1.0 / step)) # 帧数 volume = np.zeros((frameNum, 1)) for i in range(frameNum): curFrame = wave_data[np.arange(i * step, min(i * step + frame_length, wlen))] # 当前帧 curFrame = curFrame - np.mean(curFrame) # 零对齐 volume[i] = 10 * np.log10(np.sum(curFrame ** 2)) return volume
画图   import librosa
import matplotlib.pyplot as plt
import numpy as np
import Volume as vp
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示符号
sr = 16000
frameSize = 256
overLap = 128
y = librosa.load('../sounds/aeiou.wav', sr=sr)[0]
volume11 = vp.calVolume(y, frameSize, overLap)
volume12 = vp.calVolumeDB(y, frameSize, overLap)
# plot the wave
time = np.arange(0, len(y)) / sr
time2 = np.arange(0, len(volume11)) * (frameSize - overLap) / sr
plt.subplot(311)
plt.plot(time, y)
plt.ylabel("幅度")
plt.subplot(312)
plt.plot(time2, volume11)
plt.ylabel("absSum")
plt.subplot(313)
plt.plot(time2, volume12, c="g")
plt.ylabel("分贝(dB)")
plt.xlabel("时间/S")
plt.tight_layout()
plt.show()
View Code
import librosa
import matplotlib.pyplot as plt
import numpy as np
import Volume as vp
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示符号
sr = 16000
frameSize = 256
overLap = 128
y = librosa.load('../sounds/aeiou.wav', sr=sr)[0]
volume11 = vp.calVolume(y, frameSize, overLap)
volume12 = vp.calVolumeDB(y, frameSize, overLap)
# plot the wave
time = np.arange(0, len(y)) / sr
time2 = np.arange(0, len(volume11)) * (frameSize - overLap) / sr
plt.subplot(311)
plt.plot(time, y)
plt.ylabel("幅度")
plt.subplot(312)
plt.plot(time2, volume11)
plt.ylabel("absSum")
plt.subplot(313)
plt.plot(time2, volume12, c="g")
plt.ylabel("分贝(dB)")
plt.xlabel("时间/S")
plt.tight_layout()
plt.show()
View Code
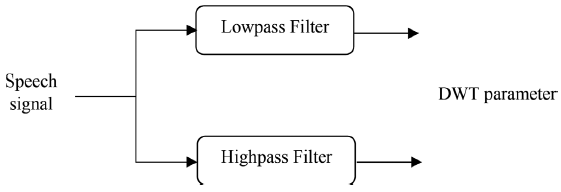
过零率 def ZeroCR(waveData, frameSize, overLap): wlen = len(waveData) step = frameSize - overLap frameNum = int(math.ceil(wlen * 1.0 / step)) # 帧数 zcr = np.zeros((frameNum, 1)) for i in range(frameNum): curFrame = waveData[np.arange(i * step, min(i * step + frameSize, wlen))] # 当前帧 # 为了避免DC bias(直流偏置),我们通常需要在每一帧上进行平均减法 curFrame = curFrame - np.mean(curFrame) # 零对齐 zcr[i] = sum(curFrame[0:-1] * curFrame[1:] 1$,$b_0>1$,而m和n被赋予一组正整数)来离散地放大和平移。 利用一对滤波器h[n]和g[n],即具有$g[n]=(-1)^{1-n}h[n]$性质的正交镜滤波器(quadrature mirror filters),可以有效地实现尺度变换和小波函数。输入信号经过低通滤波和高通滤波,分别得到近似分量和细节分量。图5总结了这一点。利用相同的低通滤波器和高通滤波器对各阶段的近似信号进行进一步分解,得到下一阶段的近似分量和细节分量。这种分解称为二元分解[33]。 DWT参数包含不同频率尺度的信息。这增强了在相应频段[33]中获得的语音信息。DWT能够按比例对输入元素的方差进行分区,这是一个额外的优势。这种划分导致了尺度相关小波方差的观点,它在很多方面等价于我们更熟悉的频率相关的傅里叶功率谱[47]。经典的离散分解方案是二元的,不能满足直接用于参数化的所有要求。DWT确实为有效的语音分析[51]提供了足够的频带数。由于输入信号的长度是有限的,由于边界[50]处的不连续性,使得小波系数在边界处的变化非常大。
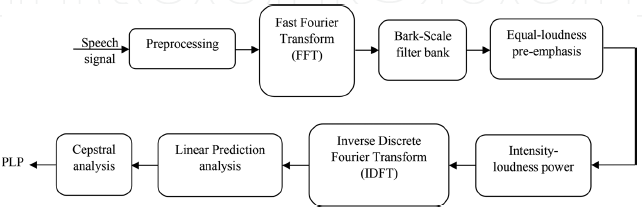
图5 DWT的方框图 7. 感知线性预测(PLP)感知线性预测(PLP)技术将关键频带、强度-响度压缩和等响度预强调相结合,用于语音相关信息的提取。它植根于非线性树皮规模,最初是打算用于语音识别任务中消除说话人相关的特征[11]。PLP给出了一个符合平滑的短期频谱的表示,该短期频谱已被均衡和压缩,类似于人类的听觉,使其类似于MFCC。在PLP方法中,我们复制了听觉的几个显著特征,然后用自回归全极点模型[52]近似地表示类似听觉的语音频谱。PLP给出了高频下的最小分辨率,这意味着基于听觉滤波器组的方法,同时给出了与倒谱分析相似的正交输出。它使用线性预测来平滑光谱,因此,它的名字是感知线性预测[28]。PLP是光谱分析和线性预测分析的结合。 7.1 算法说明,优缺点为了计算语音的PLP特征,计算了语音的快速傅里叶变换(FFT)和幅度的平方。这给出了功率谱估计。然后在1树皮间隔上应用梯形滤波器,将重叠的临界带滤波器响应整合到功率谱中。这能有效地把高频压缩成窄带。在树皮扭曲的频率尺度上的对称频域卷积允许低频掩盖高频,同时平滑频谱。频谱随后被预先强调,以近似人类听觉在各种频率下的不均匀灵敏度。对谱振幅进行压缩,减小了谱共振的振幅变化。通过离散傅里叶反变换(IDCT)得到自相关系数。进行谱平滑,求解自回归方程。将自回归系数转换为倒谱变量[28]。计算树皮鳞片频率的公式为
图6。PLP处理器的方框图 滤波器系数 滤波器的形状 建模方法 速度的计算 系数类型 抗噪声能力 对量化/附加噪声的灵敏度 可靠性 捕获频率Mel倒频谱系数(MFCC) Mel 三角形 人类听觉系统 高 倒频谱 中等 中等 高 低线性预测系数(LPC) 线性预测 线性 人类声道 高 自相关系数 高 高 高 低 线性预测倒谱系数(LPCC) 线性预测 线性 人类声道 中等 倒频谱 高 高 中等 低&中等 谱线频率(LSF) 线性预测 线性 人类声道 中等 频谱 高 高 中等 低&中等 离散小波变换(DWT) 低通&高通 - - 高 小波 中等 中等 中等 低&中等 感知线性预测(PLP) Bark 梯形 人类听觉系统 中等 倒频谱&自相关 中等 中等 中等 低&中等表1 特征提取技术的比较。
其中,bark(f)为频率(bark), f为频率(Hz)。 PLP的识别效果优于LPC[28],因为它有效地抑制了说话人相关信息[52],是对传统LPC的改进。此外,它还增强了与扬声器无关的识别性能,并且对噪声、信道变化和麦克风[53]具有鲁棒性。PLP精确重构了自回归噪声分量[54]。基于PLP的前端对共振峰频率的任何变化都很敏感。 图6显示了PLP处理器,显示了获取PLP系数所需的所有步骤。PLP对谱倾斜的敏感性较低,这与我们的研究结果一致,即对谱倾斜的语音判断相对不敏感。此外,PLP分析依赖于整体光谱平衡(共振峰振幅)的结果。共振峰振幅易受记录设备、通信信道和附加噪声[52]等因素的影响。此外,时间-频率分辨率和有效采样的短期表现在一个特设的方式解决了[54]。 表1显示了上述六种特征提取技术的比较。尽管用于研究的特征提取算法的选择是独立的,但是本表能够根据选择任何特征提取算法时的主要考虑因素来描述这些技术。这些考虑因素包括计算速度,抗噪声性和对附加噪声的敏感性。该表还可作为考虑在所讨论的任何两个或多个算法之间进行选择时的指南。 8. 结论MFCC、LPC、LPCC、LSF、PLP和DWTare是一些用于提取语音信号中相关信息的特征提取技术,用于语音识别和识别。这些技术经受住了时间的考验,并在语音识别系统中得到了广泛的应用。语音信号是一种慢时变的准平稳信号,当在5 ~ 100毫秒的足够短的时间内观察到它时,它的行为是相对平稳的。因此,包括MFCC、LPCC和PLP在内的短时谱分析常被用于从语音信号中提取重要信息。噪声是特征提取以及说话人识别过程中所面临的一个严峻挑战。随后,研究人员对上述讨论的技术进行了一些修改,使它们更不受噪音影响,更健壮,消耗的时间更少。这些方法也被用于声音的识别。提取的信息将被输入分类器进行识别。上述特征提取方法可以用MATLAB实现。
|

【本文地址】