| 深度学习 | 您所在的位置:网站首页 › lmdb格式数据集 › 深度学习 |
深度学习
|
转载:http://blog.csdn.net/mrhiuser/article/details/69603826
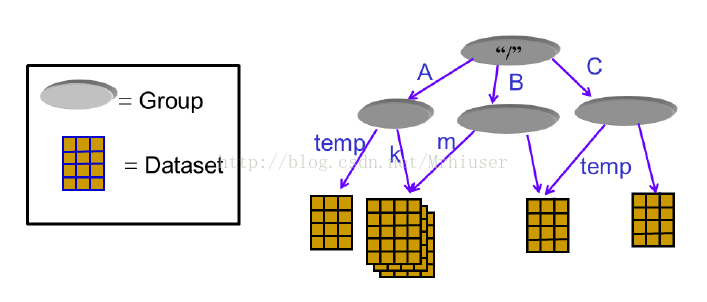
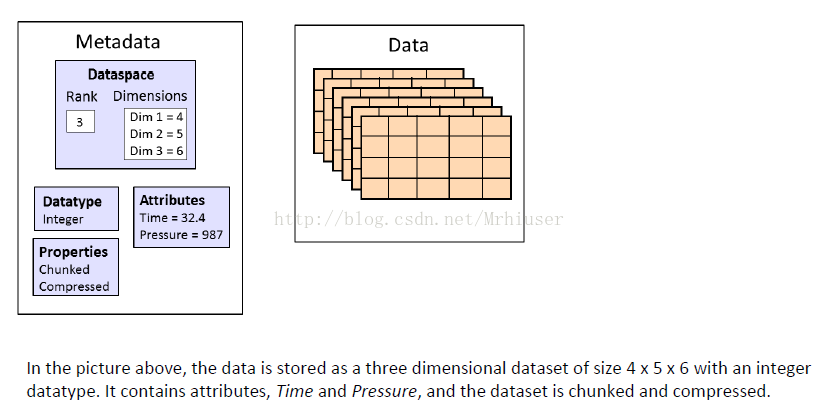
转载:http://blog.csdn.net/zykimmy/article/details/52950441 1、HDF5介绍 HDF 是用于存储和分发科学数据的一种自我描述、多对象文件格式。HDF 是由美国国家超级计算应用中心(NCSA)创建的,以满足不同群体的科学家在不同工程项目领域之需要。HDF 可以表示出科学数据存储和分布的许多必要条件。HDF 被设计为: 自述性:对于一个HDF 文件里的每一个数据对象,有关于该数据的综合信息(元数据)。在没有任何外部信息的情况下,HDF 允许应用程序解释HDF文件的结构和内容。通用性:许多数据类型都可以被嵌入在一个HDF文件里。例如,通过使用合适的HDF 数据结构,符号、数字和图形数据可以同时存储在一个HDF 文件里。灵活性:HDF允许用户把相关的数据对象组合在一起,放到一个分层结构中,向数据对象添加描述和标签。它还允许用户把科学数据放到多个HDF 文件里。扩展性:HDF极易容纳将来新增加的数据模式,容易与其他标准格式兼容。跨平台性:HDF 是一个与平台无关的文件格式。HDF 文件无需任何转换就可以在不同平台上使用。(官方介绍:https://support.hdfgroup.org/HDF5/whatishdf5.html) 2、HDF5的文件组织一个HDF5文件就是一个由两种基本数据对象(groups and datasets)存放多种科学数据的容器: HDF5 group: 包含0个或多个HDF5对象以及支持元数据(metadata)的一个群组结构HDF5 dataset: 数据元素的一个多维数组以及支持元数据(metadata)
3、HDF5软件下载 https://support.hdfgroup.org/HDF5/release/obtain518.html 4、目录结构下载后解压 在Matlab中的使用: 注:因为matlab是列优先存储,而hdf5是行优先存储,所以你必须把矩阵在Matlab里转置一下,虽然matlab还是列优先存储,但是转置之后对于原矩阵相当于行优先存储了,这时候在写入到hdf5中。
hdf5和lmdb的对比:
LMDB格式的优点: - 基于文件映射IO(memory-mapped),数据速率更好 - 对大规模数据集更有效. HDF5的特点: - 易于读取 - 类似于mat数据,但数据压缩性能更强 - 需要全部读进内存里,故HDF5文件大小不能超过内存,可以分成多个HDF5文件,将HDF5子文件路径写入txt中. - I/O速率不如LMDB. 而且hdf5,可以应用于多标签的任务上,比如给一张猫,它的标签不仅仅只包括它是猫这个标签,还包括,它很胖,它很大,这种标签,就使用hdf5比较合适。而lmdb是一对一的,键值对数据库,一个图片只对应一个标签。
以下内容转载于:https://www.cnblogs.com/yinheyi/p/6083855.html
caffe默认使用的数据格式为lmdb文件格式,它提供了把图片转为lmdb文件格式的小程序,但是呢,我的数据为一维的数据,我也要分类啊,那我怎么办?肯定有办法可以转为lmdb文件格式的,我也看了一些源代码,好像是把我们的数据变为Datum的格式(这是一个用google protocol buffer搞的一个数据结构类),然后再把它存为lmdb文件。在Datum里面,label为Int类型,要是我们label为符点数,我还怎么用??(不过看到Datum里面有个float_data的东西,怎么用啊,不懂)。好吧,费了一劲想把转换Mnist的程序为我用,是有点成功,不过太麻烦,好像不怎么好使。 最后,用hdf5格式的数据吧。好在网络有好多资料哦,牛逼的人好多的哦,我实在是很膜拜他们。下面说说怎么转。我用的是matlab转,网络也有好多用python程序的。
以转Mnist 为例,我们以后可以照着写出自己的来。
%读入训练数据,下面的函数loadMNISTImages是一个自己的函数,如果你想要的话,可以去gitbub上下载(看 %参考文献里有, 读完以后,这时,images为一个28*28* 50000的3D数组; images = loadMNISTImages('train-images-idx3-ubyte');%读完后,labels为一个50000* 1的数组; labels = loadMNISTLabels('train-labels-idx1-ubyte');% reshape images to 4- D: [rows,col,channel,numbers] trainData=reshape(images,[28 28 1 size(images,2)]);% permute to [cols,rows,channel,numbers] trainData=permute(trainData,[2 1 3 4]);% permute lables to [labels, number of labels ] trainLabels=permute(labels,[2,1]);% create database %注意,这是的/data与/label表示文件里的dataset.当我们定义.proto文件的网络时,一定要注意:top:分别也要为data和label. h5create('train.hdf5','/data',size(trainData),'Datatype','double'); h5create('train.hdf5','/label',size(trainLabels),'Datatype','double'); h5write('train.hdf5','/data',trainData); h5write('train.hdf5','/label',trainLabels);% same for test data
生成文件以后,可以通过h5disp(’文件名‘)看看里面的东西。下面是我自己生成的文件里的内容,不是上面生成的哦;
再往下,就是.proto文件里的data的定义了,下面是我的定义自己的:
注意: 第一,再生成HDF5文件时,一定要注意数组的维度关系,很敏感的,如,把1*50000写为了50000*1肯定会出错的。在caffe中,数据都是以4维出现的。(我记得python与matlab里的维度是正反的,python与C语言中都是rowmajor, matlab中是 column-major, 相应的就是, matlab是一组维度中,左边的数字变化最快,,而python中为右边。好像是这样的) 第二,生成的HDF5的dataset的名称一定要与你后面定义的.proto文件里的data层的top:后面的名称(即输出的名称)一样啊,要不出错,找不到数据的)。 第三,在定义.proto文件里的data层时注意,hdf5_data_param的source不要直接写我们生成的HDF5文件的路径,而是写一个.txt文件的,并在.txt文件里写入你生成的HDF5文件的路经,一个HDF5文件路径占一行,一定要这样哦。原因是因为,我们可以要读入多个HDF5文件,所以要这样写哦。 第四,生成的HDF5文件一般都很大,如果是图片的话,可以很多的,HDF5Data layer不能按照batch来从磁盘上读取数据,只能一次性把所有数据从h5文件中读到内存中,如果出错了,很可以你的内存不够了哦; 第五,HDF5Data layer不支持预处理功能。
一开始吧, 我老是想一个总是,当读取HDF5文件时,它是怎么知道包含有多少个数据的,现在想想,HDF5文件肯定写入了相关的数据结构相关的内容啊,看看上面的h5disp()的输出,我们就知道啦。 其实上面这个问题,我一开始是在想使用lmdb文件时,它把数据写入的Datum中,在Datum文件中,放数据的为bytes格式,我再想,它怎么知道一个数据占多少个byte的呢??Datum里也没有这个选项。现在还是不明白,如果这个问题明白了,我就可以把数据转为lmdb文件了,但是我始终没有找到由datum变为数据的源代码呢?? 如果好心人看到了,请帮我解答一下子哦; 注:caffe怎么指的hdf5里有多少个数据呢,caffe里的数据都是4维的,hdf5数据也可以是四维的,hdf5数据创建一个四维数组,最后一个维度就是数据量的多少 |


【本文地址】