| laravel leftjoin 右侧取最新一条 | 您所在的位置:网站首页 › laravel最新 › laravel leftjoin 右侧取最新一条 |
laravel leftjoin 右侧取最新一条
|
小蜗牛,今天爬了多远?不急,继续爬总会到达终点。 朋友们,今天学习了多久?别慌,保持学习才会看到更好的自己。 最近过了双11,就一直准备双12的大促,忙到无法自拔。今天,咱们就来聊聊mysql中一个非常实际场景(当然hive和oracle实际也适用就是语法有不同而已),这个属于经典和常用,也就意味着坑很多,所以,各位好好看好好学。 文章目录情景引入 基础知识介绍 需求 预热准备 定义测试“书”表的DDL 随便插入几条测试数据的DML 方案设计 错误方案一 结果 分析 错误方案二 结果 分析 正确方案一 结果 分析 正确方案二 结果 分析 正确方案三 结果 分析 总结 情景引入旁白:今天的天气好晴朗,处处好风光!!好风光!!今天的我没有睡懒觉,而是与小白手牵手在逛街!!! 小白:你看你看,那个店子有好多的书呀!知识的海洋,我来了! 我:翻了个白眼,知识的海洋,对你不应该是知识的地狱吗?今天怎么像变了一个人呢? 旁白:我和小白走进了琳琅满目的书店,各色各样的书籍展示在眼前! 小白:好奇怪,你快看,那边有好多重复的书,书名和作者都是一样的,可是却有新有旧的。 我:这不是很正常吗?总不能同样的书籍就那么一本书吧。 小白:可是,这相同的书名和编码的书,我都只想看最新的一本,这个可怎么办呢? 我:很简单呀,你一一对比每种相同的书,然后拿最新的不就好了吗?不就多花点时间而已嘛,用时间换复杂度也行啦! 小白:那多难整啊。。。我就是要每种书的最新的那一本,你快帮我想更好的办法; 我:既然,你都说了,要每组书名和编码一样的最新的一本,那么就认真听我给你分析分析。 基础知识介绍这篇文章主要是讲解在Mysql中常常遇到的一个需求问题,那么会涉及到的一些知识点如下:group by:order by:inner join:left join:学习链接: 菜鸟教程PS:这些基础的就不多说了,大家不懂的就往对应的链接里面先学习学习再往下面的内容阅读哦! 需求求按一定字段进行分组之后的每组最新或者版本最大的一条数据。假设:如书名和书编码相同时,则获取版本号最大(或创建时间最近)的一条数据;PS:本文就以版本号最大为例子吧。实际依葫芦画瓢就明白其他的场景了。 预热准备 定义测试“书”表的DDL CREATE TABLE `book` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL COMMENT '书名', `code` varchar(64) DEFAULT NULL COMMENT '书编码', `create_time` datetime DEFAULT NULL COMMENT '创建时间', `version` int(11) DEFAULT NULL COMMENT '版本号', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;PS:简简单单的数据字段,如有不严谨的地方请不要在意,这里仅仅用于说明本文需要讲解的场景哦!!! 随便插入几条测试数据的DML INSERT INTO `book` VALUES ('1', '小白', '0001', '2020-04-07 21:07:44', '1');INSERT INTO `book` VALUES ('2', '小白', '0001', '2020-04-08 21:07:59', '2');INSERT INTO `book` VALUES ('3', '小黑', '0002', '2020-04-08 21:08:16', '1');INSERT INTO `book` VALUES ('4', '小明', '0003', '2020-04-01 21:08:28', '2');INSERT INTO `book` VALUES ('5', '小明', '0003', '2020-04-08 21:08:40', '3');
根据上面的样本数据再结合对应的需求,那么,**在理想状态下,**就是获取得到如下情况的数据: 采取简单直接的方式,即先分组和排序一起操作 select *FROM bookGROUP BY name,code order by version desc, id asc 结果
首先,确实是将相同的name和code的内容进行了分组,即同样的name和code的数据只存在一条,说明group by没有毛病,是分组了。 order by:其中id asc是升序,那么结果确实也是升序这个没问题;假设,觉得没用,那么大家可以试试没有加id asc的情况就如下,说明id asc 是生效了。 order by:其中version desc是倒序,那么再看下实际情况,确实也是按照version倒序进行排序,那么说version desc也是有效果的。那么到底哪里有问题呢? 结论:这是因为当group by 和order by同时出现的时候,它是先执行group by 分组然后才对分组的结果进行的排序。因此,执行顺序是有问题,这样自然无法实现我们需要取每组最大版本号的数据了。 错误方案二经过上面错误方案的解析,那么这一种肯定可以。。自信满满!!! select * from (select *from bookORDER BY version desc)as t1GROUP BY t1.name,t1.code order by id asc 结果
通过实际结果观察,id确实是升序,但是每条数据的version字段却不是最大的呀。 通过第一种错误方案说到,要先根据version排序,然后再group by 分组。那看看SQL,确实是先排序,再分组了。可是为什么不行? 结论:该方案还是由于排序和分组的效果被优化导致的。因为当外层存在group by语法时,会导致内层的order by 会失效,而mysql会默认采取“第一条”。关键来了,“第一条”,这个第一条并不是排序后的第一条,而是插入数据库同等分组条件下的顺序的第一条哦!假设,我们把初始的数据变成如下,然后再执行该方案的SQL就发现结果与期望的一样啦。其原因就是在于上面说的。 ======================================= 好气呀,这两种方案都不行,那到底怎么写呢。别慌,继续往下面看 ======================================= 正确方案一 select * from (select *from bookORDER BY version desclimit 100000)as t1GROUP BY t1.name,t1.code order by id asc 结果
我们对比一下错误方案二和现在这种方案,发现,就是因为该mysql内层采取了limit关键字进行“分页”处理。 why?why?why? 结论: 因为在内层子查询中采取limit和order by同时作用的话,就会将子查询的结果根据对应语法进行实际的先排序后分页,而不会与外层的group by语法进行优化。因此,这样的效果就可以实现获取每组的版本号最大的数据了。缺点: 很多朋友也应该想到了,那么就是如果子查询的结果集的条数是不知道的呢?那么limit如果小了,就会导致一些数据丢失,自然这样得到的结果就不准了。那么如何解决呢?优化: 既然无法确定实际的查询数据条数,那么就可以先查询一下总的数据条数,然后limit就以该结果作为参数不就可以了嘛。对的,先查询子查询的总数据条数,然后limit该结果就可以了。切记,是分开两个SQL语句了哦!!!!注意点: 这里要采取inner join而别采取left join或者right join(它们三者的区别就不多说了),除非你确定你的数据条件中,不存在null的情况,而都是一一对应而都存在,那么就没问题; 正确方案二上面的方案存在一定的问题,那么还可以怎么做呢? select t1.*from book as t1INNER JOIN(SELECT name,code,max(version) as versionfrom bookGROUP BY name,code)as t2on t1.code = t2.code and t1.name = t2.nameand t1.version = t2.versionorder by id asc 结果
该SQL实现的方式主要是用到了max函数的作用。(1)我们逐步的拆分来看:首先, SELECT name,code,max(version) as versionfrom bookGROUP BY name,code我们先根据要分组的内容进行group by,注意这时候select的字段也是要将分组的字段进行获取,其次,就是采取max函数获取我们需要的version最大(同理,如果是创建时间也是一样)。那么这样处理得到的结果是什么呢?自然,这样就可以获取到每组中版本号最大的数据信息。注意,此时并没有达到我们想要的结果。因为如果我们还要获取到版本号最大的其他的字段的信息,而此时只是获取到版本号最大的,而其他字段并非就是版本号最大对应的所有字段信息。(2)再通过inner join的语法作用。我们在(1)中已经获取到了每个分组条件以及需要版本号的最大的值,那么,通过inner join的等值连接,这样就可以根据“等值原理”获取到其对应的所有字段的信息了呀。那么就实现了我们的需求;缺点: 可以发现在最里层的子查询中这样的效率是不好的,是走的全表扫描(PS:如果存在其他的限制条件通过有索引可以实现一点优化),那么全表扫描的效率就不够好了。优化: 在里层的查询中,增加一定的限制条件,并且限制条件采取能够以索引处理; 正确方案三那么还有其他的处理方案吗? select t1.*from bookas t1,(SELECT name,code,max(version) as versionfrom bookGROUP BY name,code)as t2where t1.code = t2.code and t1.name = t2.nameand t1.version = t2.versionorder by id asc 结果
该方案实际和正确方案二没什么特别大的差异;将方案二中的inner join等值连接而采取自然连接的方式。实际当加上where条件之后,效果是一致的了。 总结当然,上面的例子是非常简单的,但是实际就是能够表明这种相似场景会存在的问题,而在我们实际中,也不过是限制条件多了一点,然后表的字多了一些,而要关联的表多一点而已。所以,还是希望各位能够明白上述几种正确和错误方案的原因和原理; 分组取数是相对常见的需求,那么,我们应该多注重这方面的隐藏问题,否则,只是简单的想或者数据量少时,那几种错误的方案可能就被误以为是正确的了。所以,要多多的思考问题; 建议大家可以看看Mysql的执行流程以及底层时,引擎到底是如何工作等等内容,比如,Mysql执行语句是一条链还是多分支?Mysql执行的时候是哪一层判断语法是否正确或错误的呢?。所以,路漫漫兮,共同学习! 如果你觉得文章还不错,那么赶紧分享给一样想学习的小伙伴来共同成长。 |
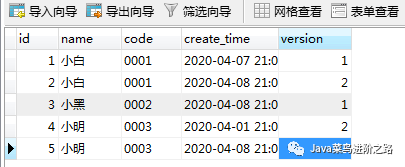 PS:瞎插几条数据,以表心意!!!!
PS:瞎插几条数据,以表心意!!!!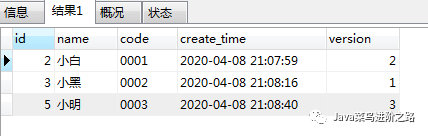 PS:为了让各位看的清楚,就特意按照id从小到大的排序了哈!!
PS:为了让各位看的清楚,就特意按照id从小到大的排序了哈!!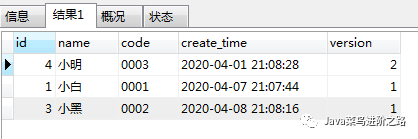 结论:这样的方案是错误的对比,理想情况和实际情况,只能说,这种方案当然不行啦。那么为何不行呢?请继续看。。。。。
结论:这样的方案是错误的对比,理想情况和实际情况,只能说,这种方案当然不行啦。那么为何不行呢?请继续看。。。。。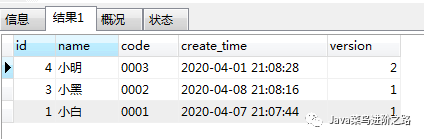
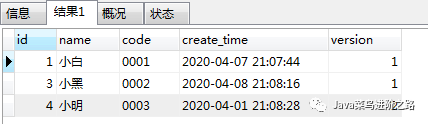 结论:这个方案结果还是不对!!!
结论:这个方案结果还是不对!!! 结论:哇塞,实际和预期是一样的结果了哦!!!
结论:哇塞,实际和预期是一样的结果了哦!!!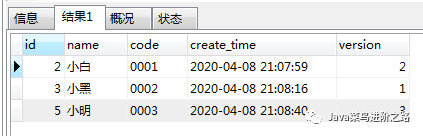 结论:实际和预期一样!
结论:实际和预期一样!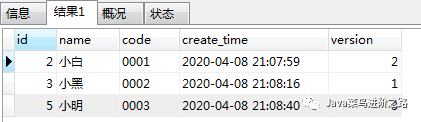 结论:老铁,实际和预期一样,没毛病!
结论:老铁,实际和预期一样,没毛病!【本文地址】