| 什么是Flink的非barrier对齐,如何使用? | 您所在的位置:网站首页 › flink多个输出 › 什么是Flink的非barrier对齐,如何使用? |
什么是Flink的非barrier对齐,如何使用?
|
众所周知,flink在开启checkpoint之后,source 任务收到触发检查点保存的指令后,会立即在当前处理的数据中插入一个标识字段(Barrier),然后再向下游任务发出。我们平时使用比较多的是对齐的barrier,那你知道非对齐的barrier吗?如何使用呢?让我们通过下面的阅读一起了解一下吧。 一、Barrier 流的barrier是Flink Checkpoint中的一个核心概念。多个barrier被插入到数据流中, 然后作为数据流的一部分随着数据流动(有点类似于Watermark)。这些barrier不会跨越流中的数据。 每个barrier会把数据流分成两部分:一部分数据进入当前的快照,另一部分数据进入下一个快照。每个barrier携带着快照的id。barrier 不会暂停数据的流动,所以非常轻量级。在流中, 同一时间可以有来源于多个不同快照的多个barrier,这意味着可以并发地出现不同的快照。
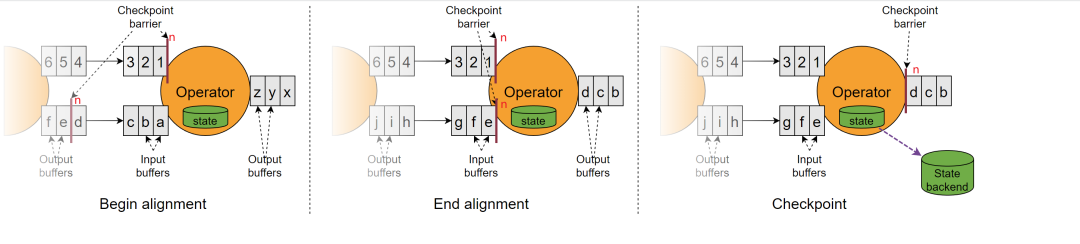
二、对齐的barrier 在多并行度下,如果要实现严格一次,则要执行barrier对齐。当 job graph 中的每个 operator 接收到 barrier 时,就会记录下其状态。拥有两个输入流的 operators(例如 CoProcessFunction)会执行 barrier 对齐(barrier alignment),以便当前快照能够包含两个输入流 barrier 之前(但不超过)的所有 events 产生的状态。
1. 当operator收到数字流的barrier n时, 它就不能处理(但是可以接收)来自该流的任何数据记录,直到它从字母流的所有输入中接收到 barrier n 为止。 2. 接收到 barrier n 的流(数字流)暂时被搁置。从这些流接收的记录会进入输入缓冲区, 不会被处理。例如图中的 barrier n 之后的数据 123 已经到达了operator, 存入到了输入缓冲区没有被处理, 只有等到字母流的 barrier n 到达之后才会开始处理。 3. 一旦最后所有输入流都接收到 barrier n,operator 就会把缓冲区中待输出的数据发出去,然后把 barrier n 接着往下游发送。这里还会对自身进行快照。 优点: barrier 对齐不仅保证了状态的准确性,还巧妙地消去了原生C-L算法中记录输入流状态的步骤,十分轻量级,保存的数据体积小。 缺点: 延迟性高(快的barrier到达后会阻塞此条流的数据处理)。 加剧作业的反压(当出现反压时,数据本身就处理不过来,此时某条流的数据又阻塞了,所以就会加剧反压)。 整体 chenkpoint 时间变长(因为反压会导致数据流速变慢,导致barrier流动速度也会变慢,所以整体chenkpoint时间就会变长)。 三、barrier不对齐 如果barrier不对齐会怎么样?会重复消费,就是至少一次语义。
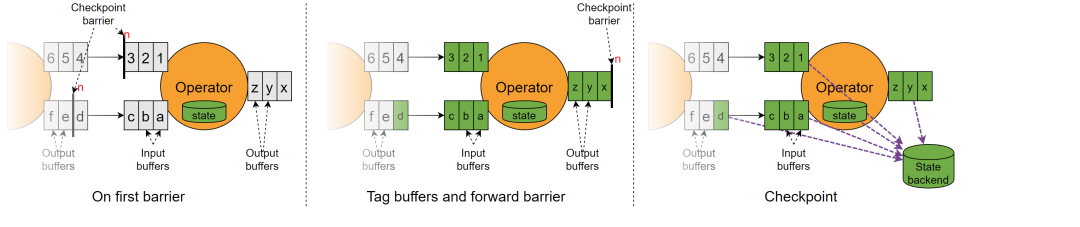
1. 当 operator 收到数字流的 barrier n 时,开启本地快照记录自己的状态,并将这个 barrier 发往下游(输出缓冲区)。 2. 接收到 barrier n 的流(数字流)会继续往下走。字母流的 barrier n 前面的数据(abcd)会被保存到状态里面,直到 barrier n 到来以后,再进行checkpoint,将数据保存到检查点中。 优点: 避免了 checkpoint 可能带来的阻塞,有利于提升 Flink 的资源利用率。 缺点: 由于要持久化缓存数据,State Size 会有比较大的增长,磁盘负载会加重。 随着 State Size 增长,作业恢复时间可能增长,运维管理难度增加。 四、barrier的使用 对齐 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 每 1000ms 开始一次 checkpoint env.enableCheckpointing(1000); // 高级选项: // 设置模式为精确一次 (这是默认值),对于延迟要求较高的选择,最少一次 env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 确认 checkpoints 之间的时间会进行 500 ms env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); // Checkpoint 必须在一分钟内完成,否则就会被抛弃 env.getCheckpointConfig().setCheckpointTimeout(60000); // 允许两个连续的 checkpoint 错误 env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2); // 同一时间只允许一个 checkpoint 进行 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留 env.getCheckpointConfig().setExternalizedCheckpointCleanup( ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 开启实验性的 unaligned checkpoints env.getCheckpointConfig().enableUnalignedCheckpoints(); 非对齐 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 启用非对齐 Checkpoint env.getCheckpointConfig().enableUnalignedCheckpoints(); 或者在 flink-conf.yml 配置文件中增加配置: execution.checkpointing.unaligned: true 总结 非对齐barrier主要是解决严重反压情况下作业难以完成 checkpoint 的问题,同时它以磁盘资源为代价,避免了 checkpoint 可能带来的阻塞,有利于提升 Flink 的资源利用率。 |

【本文地址】