| 论文(一):Data | 您所在的位置:网站首页 › ea的优化 › 论文(一):Data |
论文(一):Data
|
Data-Driven Evolutionary Optimization: An Overview and Case Studies 数据驱动的进化优化。纵览 概述和案例研究 摘要 Abstract—Most evolutionary optimization algorithms assume that the evaluation of the objective and constraint functions is straightforward. In solving many real-world optimization problems, however, such objective functions may not exist. Instead, computationally expensive numerical simulations or costly physical experiments must be performed for fitness evaluations. In more extreme cases, only historical data are available for performing optimization and no new data can be generated during optimization. Solving evolutionary optimization problems driven by data collected in simulations, physical experiments, production processes, or daily life are termed data-driven evolutionary optimization. In this paper, we provide a taxonomy of different data driven evolutionary optimization problems, discuss main challenges in data-driven evolutionary optimization with respect to the nature and amount of data, and the availability of new data during optimization. Real-world application examples are given to illustrate different model management strategies for different categories of data-driven optimization problems. Index Terms—Data science, data-driven optimization, evolutionary algorithms (EAs), machine learning, model management, surrogate. 大多数进化优化算法假定目标和约束函数的评估是直接的。然而,在解决许多现实世界的优化问题时,这种目标函数可能不存在。相反,必须进行计算上昂贵的数值模拟或昂贵的物理实验来进行适配性评价。在更极端的情况下,只有历史数据可用于每个成型的优化,并且在优化过程中不能产生新的数据。解决由模拟、物理实验、生产过程或日常生活中收集的数据驱动的进化优化问题被称为数据驱动的进化优化。在本文中,我们提供了不同的数据驱动进化优化问题的分类,讨论了数据驱动进化优化在数据性质和数量方面的主要挑战,以及优化过程中新数据的可用性。同时,还给出了现实世界的应用实例,以说明针对不同类别的数据驱动优化问题的不同模型管理策略。 索引范围--数据科学,数据驱动的优化,进化算法(EA),机器学习,模型管理,代用。
一、介绍 MANY real-world optimization problems are difficult to solve in that they are nonconvex or multimodal, large-scale, highly constrained, multiobjective, and subject to a large amount of uncertainties. Furthermore, the formulation of the optimization problem itself can be challenging, requiring a number of iterations between the experts of the application area and computer scientists to specify the appropriate representation, objectives, constraints, and decision variables [1]–[3]。 许多现实世界的优化问题都很难解决,因为它们是非凸或多模态的、大规模的、高度约束的、多目标的,并且受制于大量的不确定性。此外,优化问题本身的计算公式可能具有挑战性,需要应用领域的专家和计算机科学家之间进行多次迭代,以指定适当的代表、目标、约束和决策变量[1]-[3]。
Over the past decades, evolutionary algorithms (EAs) have become a popular tool for optimization [4], [5]. Most existing research on EAs is based on an implicit assumption that evaluating the objectives and constraints of candidate solutions is easy and cheap. However, such cheap functions do not exist for many real-world optimization problems. Instead, evaluations of the objectives and/or constraints can be performed only based on data, collected either from physical experiments, numerical simulations, or daily life. Such optimization problems can be called data-driven optimization problems [6]. In addition to the challenges coming from the optimization, data-driven optimization may also be subject to difficulties resulting from the characteristics of data. For example, the data may be distributed, noisy, heterogeneous, or dynamic (streaming data), and the amount of data may be big or small, imposing different challenges to the data-driven optimization algorithm. 在过去的几十年里,进化算法(EA)已经成为一种流行的优化工具[4], [5]。大多数现有的关于演化算法的研究是基于一个隐含的假设,即评估候选解决方案的目标和约束条件是容易和便宜的。然而,对于许多现实世界的优化问题来说,这样的廉价函数并不存在。相反,目标和/或约束的评估只能基于从物理经验、数字模拟或日常生活中收集的数据。这种优化问题可以被称为数据驱动的优化问题[6]。除了来自优化的挑战外,数据驱动的优化还可能受到数据特性带来的困难。例如,数据可能是分布式的、有噪声的、异质的或动态的(流式数据),数据量可能很大或很小,对数据驱动的优化算法提出了不同的挑战。
In some data-driven optimization problems, evaluations of the objective or constraint functions involve time- or resource-intensive physical experiments or numerical simulations (often referred to as simulation-based optimization). For example, a single function evaluation based on computational fluid dynamic (CFD) simulations could take from minutes to hours [1]. To reduce the computational cost, surrogate models (also known as meta-models [7]) have been widely used in EAs, which are known as surrogate-assisted EAs (SAEAs) [8]. SAEAs perform a limited number of real function evaluations and only a small amount of data is available for training surrogate models to approximate the objective and/or constraint functions [9], [10]. Most machine learning models, including polynomial regression [11], Kriging model [12], [13], artificial neural networks (ANNs) [14]–[16], and radial basis function networks (RBFNs) [17]–[20] have been employed in SAEAs. With limited training data, approximation errors of surrogate models are inevitable, which may mislead the evolutionary search. However, as shown in [21] and [22], an EA may benefit from the approximation errors introduced by surrogates, and therefore, it is essential in SAEAs to make full use of the limited data. 在一些数据驱动的优化问题中,目标或约束函数的评估涉及时间或资源密集型的物理实验或数值模拟(通常被称为基于模拟的优化)。例如,基于计算流体动力学(CFD)模拟的单一函数评估可能需要几分钟到几小时[1]。为了减少计算成本,代用模型(也被称为元模型[7])已被广泛用于EA中,这被称为代用辅助EA(SAEA)[8]。SAEAs进行有限的实际函数评价,只有少量的数据可用于训练surrogate模型来近似目标和/或约束函数[9], [10]。大多数机器学习模型,包括多项式回归[11]、克里金模型[12]、[13]、人工神经网络(ANN)[14]-[16]和径向基函数网络(RBFN)[17]-[20]都被应用于SAEAs。由于训练数据有限,代用模型的近似误差是不可避免的,这可能会误导进化搜索。然而,正如[21]和[22]所示,一个EA可以从代理模型引入的近似误差中获益,因此,在SAEA中充分利用有限的数据是非常重要的。
In contrast to the above situation in which collecting data is expensive and only a small amount of data is available, there are also situations in which function evaluations must be done on the basis a large amount of data. The hardness brought by data to data-driven EAs is twofold. First, acquiring and processing data for function evaluations increase the resource and computational cost, especially when there is an abundant amount of data [23]. For example, a single function evaluation of the trauma system design problem [6] needs to process 40 000 emergency incident records. Second, the function evaluations based on data are the approximation of the exact function evaluations, because the available data is usually not of ideal quality. Incomplete [24], imbalanced [25], [26], and noisy [27], [28] data bring errors to function evaluations of data-driven EAs, which may mislead the search. 与上述收集数据成本高且只有少量数据的情况相比,还有一种情况是必须在大量数据的基础上进行函数评估。数据给数据驱动的EA带来的硬伤有两方面。首先,获取和处理函数评价的数据会增加资源和计算成本,特别是在有大量数据的时候[23]。例如,创伤系统设计问题[6]的一个函数评价需要处理40 000条紧急事件记录。其次,基于数据的函数评价是精确函数评价的近似值,因为可用的数据通常质量不理想。不完整的[24]、不平衡的[25]、[26]和嘈杂的[27]、[28]数据会给数据驱动的EA的函数评价带来误差,这可能会误导搜索。
This paper aims to provide an overview of recent advances in the emerging research area of data-driven evolutionary optimization. Section II provides more detailed background about data-driven optimization, including a categorization with respect to the nature of the data, whether new data can be collected during optimization, and the surrogate management strategies used in data-driven optimization. Five case studies of real-world data-driven optimization problems are presented in Section III, representing situations where the amount of data is either small or big, and new data is or is not allowed to be generated during optimization. Open issues for future work in data-driven optimization are discussed in detail in Section IV, and Section V concludes this paper。 本文旨在概述数据驱动的进化优化这一新兴研究领域的最新进展。第二节提供了关于数据驱动优化的更详细的背景,包括对数据性质的分类,在优化过程中是否可以收集新的数据,以及数据驱动优化中使用的代理管理策略。第三部分介绍了现实世界中数据驱动优化问题的五个案例研究,代表了数据量或大或小,以及优化过程中是否允许产生新数据的情况。第四节详细讨论了数据驱动优化的未来工作的开放问题,第五节是本文的结论。
二、数据驱动的进化优化 Generally speaking, EAs begin with a randomly initialized parent population. In each iteration of EAs, an offspring population is generated via a number of variation opera[1]tors, crossover, and mutation, for instance. All solutions in the offspring population will then be evaluated to calculate their fitness value and assess their feasibility. Then, the new parent population for the next iteration is selected from the offspring population or a combination of the parent and offspring populations。 一般来说,EA从一个随机初始化的亲代种群开始。在EA的每一次迭代中,都会通过一些变异因子、交叉和变异等方式产生一个子代群体。然后,子代种群中的所有解决方案将被评估,以计算其健身值并评估其可行性。然后,下一次迭代的新父代种群将从子代种群或父代和子代种群的组合中选择。
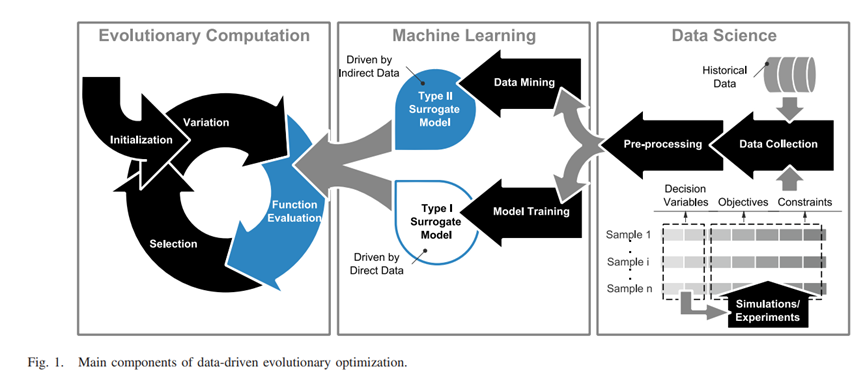
Fig. 1 presents the three main disciplines involved in data-driven evolutionary optimization, namely, evolutionary computation (including other population-based meta-heuristic search methods), machine learning (including all learning techniques), and data science. While the traditional challenges remain to be handled in each discipline, new research questions may arise when machine learning models are built for efficiently guiding the evolutionary search given various amounts and types of data. 图1展示了数据驱动的进化优化所涉及的三个主要学科,即进化计算(包括其他基于群体的元启发式搜索方法)、机器学习(包括所有学习技术)和数据科学。虽然每个学科都有传统的挑战需要处理,但当建立机器学习模型以有效指导给定的各种数量和类型的数据的进化搜索时,可能会出现新的研究问题。
Although they are widely used, surrogates in data-driven evolutionary optimization have a much broader sense than in surrogate-assisted evolutionary optimization. For example, the “surrogate” in the case study in Section III-B is more a way of reducing the amount of data to be used in fitness evaluations rather than an explicit surrogate model, where an update of the surrogate is to adaptively find the right number of data clusters. 尽管它们被广泛使用,但数据驱动的进化优化中的代用模型比代用模型辅助的进化优化中的代用模型具有更广泛的意义。例如,III-B节案例研究中的 "代理 "更多的是一种减少健身评估中使用的数据量的方式,而不是一个明确的代理模型,代理的更新是为了自适应地找到正确的数据集群数量。
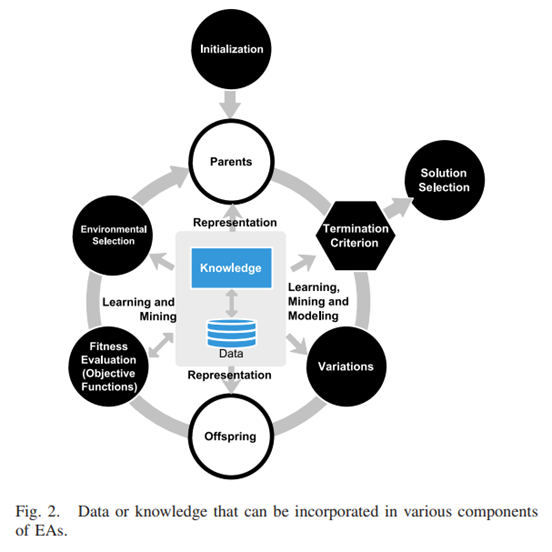
It should also be emphasized that data or domain knowledge can be utilized to speed up the evolutionary search almost in every component of an EA, as illustrated in Fig. 2. For example, history data can be used to determine the most effective and compact representation of a very large scale complex problem [29]. We also want to note that domain knowledge about the problem structure or information about the search performance acquired in the optimization process can be incorporated or reused in EAs to enhance the evolutionary search performance. These techniques are usually known as knowledge incorporation in EAs [30]. 还应该强调的是,如图2所示,数据或领域知识几乎可以在EA的每一个组成部分中被利用来加快进化搜索的速度。例如,历史数据可以用来确定一个非常大规模的复杂问题的最有效和最紧凑的表述[29]。我们还想指出,在优化过程中获得的关于问题结构的领域知识或关于搜索性能的信息可以被纳入或重用在EA中,以提高进化的搜索性能。这些技术通常被称为EA中的知识整合[30]。
In the following, we discuss in detail the challenges in data collection and surrogate construction arising from data-driven optimization。 在下文中,我们将详细讨论数据驱动的优化所带来的数据收集和代用品构建方面的挑战。
A、 数据收集 Different data-driven optimization problems may have completely different data resources and data collection methods. Roughly speaking, data can be classified into two large types: 1) direct and 2) indirect data, consequently resulting in two different types of surrogate modeling and management strategies, as shown in Fig. 1. 不同的数据驱动的优化问题可能有完全不同的数据资源和数据收集方法。粗略的说,数据可以分为两大类。1)直接数据和2)间接数据,由此产生两种不同类型的代用模型和管理策略,如图1所示。
(1)One type of data in data-driven optimization is directly collected from computer simulations or physical experiments, in which case each data item is composed of the decision variables, corresponding objective and/or constraint values, as shown in the bottom right panel of Fig. 1. This type of data can be directly used to train surrogate models to approximate the objective and/or constraint functions, which has been the main focus in SAEAs [9], [10]. We call surrogate models built from direct data type I surrogate models. Note that during the optimization, EAs may or may not be allowed to actively sample new data. 数据驱动优化中的一类数据是直接从计算机模拟或物理实验中收集的,在这种情况下,每个数据项由决策变量、相应的目标和/或约束值组成,如图1的右下角面板所示。这种类型的数据可以直接用于训练代用模型以近似目标和/或约束函数,这一直是SAEAs的主要焦点[9], [10]。我们把由直接数据建立的代用模型称为I型代用模型。请注意,在优化过程中,可能会也可能不会允许EA主动对新数据进行采样。 (2)The second type of data is called indirect data. For example, some of the objective and constraint functions in the trauma system design problem [6] can only be calculated using emergency incident records. In this case, the data are not presented in the form of decision variables and objective values. However, objective and constraint values can be calculated using the data, which are then further used for training surrogates. We term surrogate models based on indirect data Type II surrogate models. In contrast to direct data, it is usually less likely, if not impossible, for EAs to actively sample new data during optimization. 第二种类型的数据被称为间接数据。例如,创伤系统设计问题[6]中的一些目标和约束函数只能通过紧急事件记录来计算。在这种情况下,数据没有以决策变量和目标值的形式呈现。然而,目标值和约束值可以用数据来计算,然后进一步用于训练代用模型。我们把基于间接数据的代用模型称为第二类代用模型。与直接数据相比,在优化过程中,EA通常不太可能(如果不是不可能的话)主动采样新的数据。
In addition to the difference in the presentation form of the data, other properties related to data are also essential for data-driven evolutionary optimization, including the cost of collecting data, whether new data is allowed to be collected during the optimization, and whether data collection can be actively controlled by the EA. Last but not the least, data of multiple fidelity can also be made available for both data types [31]–[34] 除了数据表现形式的不同,与数据相关的其他属性对于数据驱动的进化优化也是至关重要的,包括收集数据的成本,是否允许在优化过程中收集新的数据,以及数据收集是否可以由EA主动控制。最后但并非最不重要的是,多种保真度的数据也可以为两种数据类型提供[31]-[34]。 In the following, we divide data-driven EAs into offline and online methodologies, according to whether new data is allowed to be actively generated by the EA [6]。 在下文中,我们根据是否允许EA主动生成新数据,将数据驱动的EA分为离线和在线方法[6]。
B. Offline and Online Data-Driven Optimization Methodologies 1) Offline Data-Driven Optimization Methodologies: In offline data-driven EAs, no new data can be actively generated during the optimization process [35], presenting serious challenges to surrogate management. Since no new data can be actively generated, offline data-driven EAs focus on building surrogate models based on the given data to explore the search space. In this case, the surrogate management strategy heavily relies on the quality and amount of the available data. 离线数据驱动的优化方法学。在离线数据驱动的优化方法中,在优化过程中不能主动生成新的数据[35],给代用模型管理带来了严重的挑战。由于没有新的数据可以主动生成,离线数据驱动的EA着重于根据给定的数据建立代用模型来探索搜索空间。在这种情况下,替代物管理策略在很大程度上依赖于可用数据的质量和数量。
(1) Data With Nonideal Quality: Real-world data can be incomplete [24], imbalanced [36], or noisy [27], [28]. Consequently, construction of surrogates must take into account these challenges and nevertheless, the resulting surrogates are subject to large approximation errors that may mislead the evolutionary search. 非理想质量的数据。现实世界的数据可能是不完整的[24],不平衡的[36],或有噪音的[27],[28]。因此,代用数据的构建必须考虑到这些挑战,尽管如此,所得到的代用数据会有很大的近似误差,可能误导进化搜索。
(2) Big Data: In offline data-driven optimization, the amount of the data can be huge, which results in prohibitively large computational cost for data processing and fitness calculation based on the data [23]. The computational cost of building surrogate models also dramatically increases with the increasing amount of the training data. 大数据。在离线数据驱动的优化中,数据量可能是巨大的,这导致数据处理和基于数据的适应性计算的计算成本过大[23]。随着训练数据量的增加,建立代用模型的计算成本也急剧增加。 (3) Small Data: Opposite to big data, the amount of available data may be extremely small due to the limited time and resource available for collecting data. Data paucity is often attributed to the fact that numerical simulations of complex systems are computationally very intensive, or physical experiments are very costly. A direct challenge resulting from small data is the poor quality of the surrogates, in particular for offline data-driven optimization where no new data can be generated during optimization. 小数据。与大数据相反,由于收集数据的时间和资源有限,可用的数据量可能极少。数据匮乏通常是由于复杂系统的数值模拟在计算上非常密集,或者物理实验的成本非常高。小数据带来的直接挑战是替代物的质量差,特别是对于离线数据驱动的优化,在优化期间不能产生新的数据。
Note, however, that a standard criterion to quantify big data and small data still lacks [23], as a sensible definition may depend on the problem and the computational resources available for solving the problem at hand. 然而,请注意,仍然缺乏一个量化大数据和小数据的标准[23],因为合理的定义可能取决于问题和解决手头问题的计算资源。
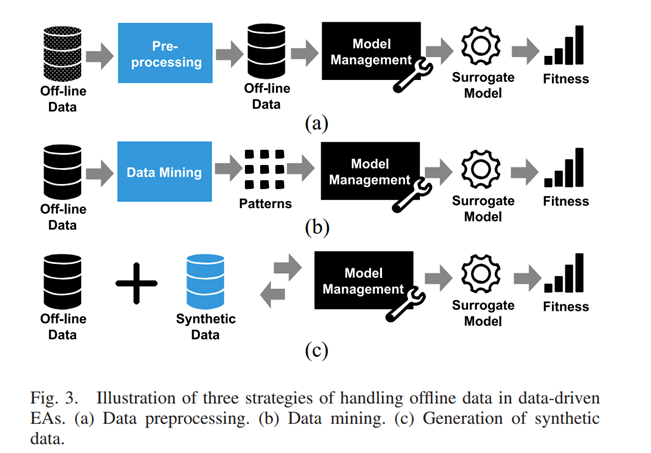
Because of the above-mentioned challenges, not many offline data-driven EAs have been proposed. The strategies for handling data in offline data-driven EAs can be divided into three categories: data preprocessing, data mining, and synthetic data generation, as shown in Fig. 3. 由于上述挑战,目前提出的离线数据驱动的EA还不多。如图3所示,离线数据驱动EA的数据处理策略可以分为三类:数据预处理、数据挖掘和合成数据生成。
(1) Data Preprocessing: For data with nonideal quality, preprocessing is necessary. As highlighted in Fig. 3(a), offline data must be preprocessed before they are used to train surrogates to enhance the performance of data[1]driven EAs. Taking the blast furnace problem in [37] as an example, which is a many-objective optimization problem, the available data collected from production is very noisy. Before building surrogates to approximate the objective functions, a local regression smoothing [38] is used to reduce the noise in the offline data. Then, Kriging models are built to assist the reference vector guided EA (RVEA) [39]. 数据预处理。对于非理想质量的数据,预处理是必要的。如图3(a)所示,离线数据在用于训练代用指标之前必须进行预处理,以提高数据驱动的EA的性能。以[37]中的高炉问题为例,这是一个多目标的优化问题,从生产中收集的可用数据是非常嘈杂的。在建立代用指标以近似目标函数之前,使用局部回归平滑[38]来减少离线数据的噪声。然后,建立Kriging模型来协助参考向量引导的EA(RVEA)[39]。 (2) Data Mining: When data-driven EAs involve big data, the computational cost may be unaffordable. Since big data often has redundancy [40], existing data mining techniques can be employed to capture the main patterns in the data. As shown in Fig. 3(b), the data-driven EA is based on the obtained patterns rather than the original data to reduce the computational cost. In the trauma system design problem [6], there are 40 000 records of emergency incidents and a clustering technique is adopted to mine patterns from the data before building surrogate models. 数据挖掘。当数据驱动的EA涉及大数据时,计算成本可能是无法承受的。由于大数据通常具有冗余性[40],可以采用现有的数据挖掘技术来捕捉数据中的主要模式。如图3(b)所示,数据驱动的EA是基于获得的模式而不是原始数据来降低计算成本的。在创伤系统设计问题[6]中,有40 000条紧急事件的记录,在建立代用模型之前,采用聚类技术从数据中挖掘模式。
(3) Synthetic Data Generation: When the quantity of the data is small and no new data is allowed to be generated, it is extremely challenging to obtain high-quality surrogate models. To address this problem, synthetic data can be generated in addition to the offline data, as shown in Fig. 3(c). This idea has shown to be helpful in data[1]driven optimization of the fused magnesium furnace optimization problem [41], where the size of available data is extremely small and it is impossible to obtain new data during optimization. In the proposed algorithm in [41], a low-order polynomial model is employed to replace the true objective function to generate synthetic data for model management during optimization. 合成数据的生成。当数据数量较少且不允许产生新的数据时,获得高质量的代用模型是极具挑战性的。为了解决这个问题,除了离线数据外,还可以生成合成数据,如图3(c)所示。这个想法在熔融镁炉优化问题的数据驱动优化中被证明是有帮助的[41],在这个问题上,可用数据的规模非常小,而且在优化过程中不可能获得新的数据。在[41]中提出的算法中,采用了低阶多项式模型来替代真实的目标函数,以产生合成数据,用于优化期间的模型管理。
Offline data-driven EAs are of practical significance in industrial optimization. However, it is hard to validate the obtained optimal solutions before they are really implemented. 离线数据驱动的EA在工业优化中具有实际意义。然而,在真正实施之前,很难验证所获得的最优解决方案。 |
【本文地址】