| 图数据集整理 | 您所在的位置:网站首页 › computer导入 › 图数据集整理 |
图数据集整理
|
前言
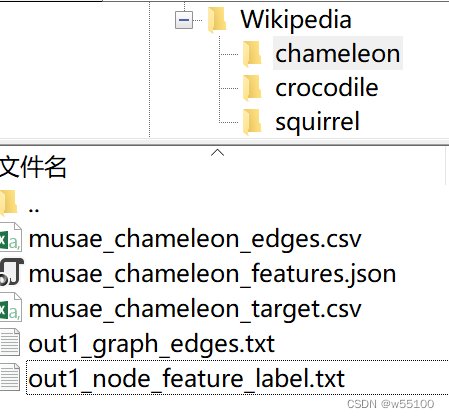
给自己做个梳理。 主要参考 1.torch_geometric.datasets https://pytorch-geometric.readthedocs.io/en/latest/modules/datasets.html https://github.com/pyg-team/pytorch_geometric 2.gnn-benchmark仓库 https://github.com/shchur/gnn-benchmark 3.dgl.data.gnn_benchmark https://docs.dgl.ai/en/0.7.x/_modules/dgl/data/gnn_benchmark.html –更新 查重把自己这篇博客查进去了。。。笑死。 结点分类任务cora,citeseer, Amazon的2个子集。 co-author的2个子集。 PPI Reddit (Symmetric Stochastic Block Model Mixture dataset,) Wiki-CS Wikipedia 1.引文网络(LBC Project)LBC project http://www.cs.umd.edu/~sen/lbc-proj/LBC.html 下辖三大数据集。 Cora Citeseer WebKB 。这是一个复合数据集。 The WebKB dataset consists of 877 scientific publications classified into one of five classes. The citation network consists of 1608 links. Each publication in the dataset is described by a 0/1-valued word vector indicating the absence/presence of the corresponding word from the dictionary. The dictionary consists of 1703 unique words. The README file in the dataset provides more details. Click here to download the tarball containing the dataset. LBC Project提供的原始文件包含.cites, .content 两种格式。 例如Cora的原始版本为 cora.cites + cora.content两个文件。 注意,从原始文件采样的label,需要freeze one-hot encoding for each class。 详见2个issue https://github.com/tkipf/pygcn/pull/53 https://github.com/tkipf/pygcn/pull/62 对这个rawdata进行处理,结果可能是不稳定的。 为了便于不同researcher进行复现和比较, 现在市面上流行的是经过preprocess的“7切割版”(我自己起的名)。 "7切割版"含有[‘x’, ‘y’, ‘tx’, ‘ty’, ‘allx’, ‘ally’, ‘graph’] 一共7种格式的文件。 例如cora是 cora.x , … , cora.graph。 这份“7切割版”是稳定的,load之后的结果是稳定的,便于比较。 1.1 WebKB3个子集比较常用 Cornell, Texas, and Wisconsin http://www.cs.cmu.edu/~webkb/ http://www.cs.umd.edu/~sen/lbc-proj/data/WebKB.tgz 原始文件是{.cites, .content}的组合。5个类别。 需要处理。 暂时不知道标准划分是什么。 在Geom-GCN里被作为disassortative graphs使用。 2.亚马逊Amazon不是蒙面战士Amazon(逃 又称AmazonCoBuy,因为边的含义是两个结点商品共同被购买。 常用两个子集 Computers, Photo Amazon Computers and Amazon Photo are segments of the Amazon co-purchase graph [McAuley et al., 2015], https://arxiv.org/pdf/1506.04757.pdf 论文作者主页提供的原始数据集 https://cseweb.ucsd.edu//~jmcauley/datasets.html 注意原始数据集是为推荐任务做的,几百万个结点。 现在作为GNN Benchmark的是后人从中二次采集的数据集。 二次采集的论文是这篇 Pitfalls of Graph Neural Network Evaluation Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, Stephan Günnemann https://arxiv.org/abs/1811.05868 https://github.com/shchur/gnn-benchmark 3.共同作者 Co-author常用2个子集CS,Physics (generated from the Microsoft Academic Graph dataset) https://kddcup2016.azurewebsites.net/ 4.WikiCS论文 Wiki-CS: A Wikipedia-Based Benchmark for Graph Neural Networks https://arxiv.org/abs/2007.02901 https://github.com/pmernyei/wiki-cs-dataset 含3个文件,解压后120MB。 data.json metadata.json statistics.json 官方给了20个seed下的mask。 print(np.array(train_masks).shape) >(20, 11701)11701个结点的划分是 print(np.sum(train_masks)/20) print(np.sum(val_masks)/20) print(np.sum(stopping_masks)/20) print(np.sum(test_mask)) >580 train >1769 valid >3505 stopping >5847 test 6. Reddit“Inductive Representation Learning on Large Graphs” https://arxiv.org/abs/1706.02216 7.演员共现网络(Actor)Actor co-occurrence network. 一般出现时叫Actor。非常古老了。 This dataset is the actor-only induced subgraph of the film-directoractor-writer network (Tang et al., 2009) Jie Tang, Jimeng Sun, Chi Wang, and Zi Yang. Social influence analysis in large-scale networks.In Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 807–816. ACM, 2009. 5.维基百科Wikipedia network常用3个子集,Chameleon, squirrel, crocodiles https://arxiv.org/abs/1909.13021 http://snap.stanford.edu/data/wikipedia-article-networks.html http://snap.stanford.edu/data/wikipedia.zip 回归任务是预测网页的月度平均流量。 原文写的 The data was collected from the English Wikipedia (December 2018). These datasets represent page-page networks on specific topics (chameleons, crocodiles and squirrels). Nodes represent articles and edges are mutual links between them. The edges csv files contain the edges - nodes are indexed from 0. The features json files contain the features of articles - each key is a page id, and node features are given as lists. The presence of a feature in the feature list means that an informative noun appeared in the text of the Wikipedia article. The target csv contains the node identifiers and the average monthly traffic between October 2017 and November 2018 for each page. For each page-page network we listed the number of nodes an edges with some other descriptive statistics. Wikipedia-Geom分类版本 Wikipedia本身没有类别。 但是在Geom-GCN里,流量被分箱成5个类别了。 the average monthly traffic of the web page is converted into five categories to predict. 于是被做成了分类任务啊。 而且Geom-GCN只对Chameleon, squirrel做了处理。 “crocodile” is not available. 这个数据集,dgl没有收录。 torch_geometric里有,可以控制是否开启分类任务。 原始格式是edges.csv和features.json。 处理成分类任务后,变成了 “out1_graph_edges.txt” + “out1_node_feature_label.txt” DatasetNodesedgesfeaturesclasseslinkWiki-CS11,701216,12330010https://github.com/pmernyei/wiki-cs-dataset/raw/master/datasetAmazon-Computers13,752245,86176710https://github.com/shchur/gnnbenchmark/raw/master/data/npz/amazon_electronics_computers.npzAmazon-Photo7,650119,0817458https://github.com/shchur/gnn-benchmark/raw/master/data/npz/amazon_electronics_photo.npzCoauthor-CS18,33381,8946,80515https://github.com/shchur/gnn-benchmark/raw/master/data/npz/ms_academic_cs.npzCoauthor-Physics34,493247,9628,4155https://github.com/shchur/gnn-benchmark/raw/master/data/npz/ms_academic_phy.npzWikipedia-Chameleon2,27736,1012,3255Wikipedia-Squirrel5,201217,0732,0895 ChameleonCrocodileSquirrelNodes2,27711,6315,201Edges31,421170,918198,493Density0.0120.0030.015Transitvity0.3140.0260.348 关于Geom-GCN版本的备注如果你follow 这文章geom-gcn https://arxiv.org/pdf/2002.05287.pdf https://openreview.net/forum?id=S1e2agrFvS https://github.com/graphdml-uiuc-jlu/geom-gcn 你会发现开源仓库,/new_data/里包含了 WebKB的Cornell, Texas, and Wisconsin。 文件里的film就是Actor数据集。 但是找不到chameleon,squirrel这两个数据集。 这两个数据集是Mr.纪自己把原始的回归任务分箱后做成分类数据集的。 想获得这两个数据集,只能通过他的torch_geometric框架。 在框架中自动下载,处理。 处理完成后会得到out1_graph_edges.txt和out1_node_feature_label.txt这两个文件。 feature的存在方式不一样/ 别的数据集feature: 每行 1,0 交错,代表每个bag of words是否存在。 而film(actor)数据集的feature ,每行仅记录那些为1的位置。 所以在加载out1_node_feature_label.txt时,需要特别注意。 看数据的处理代码也可知一二。 https://github.com/graphdml-uiuc-jlu/geom-gcn/blob/master/utils_data.py PS: 这就是我不喜欢geom系列,包括PyG这个框架的原因之一。 他们的工程化做的非常粗糙。 像这种同一个框架下的数据,都已经是process过的二手版本了。 明明可以处理成格式一样。 非要靠load层面的if-else来自适应。
早期大家会遵从数据集自带的划分方式。 比如cora自带的 [0,140),[140,640), [1000,1433) 的划分。 后面在固定划分上卷不动了之后,又开始流行随机划分。 60%/20%/20%。 这种划分的代表作很多。 这种划分的训练集太大了,很快各种模型就都性能过剩了。 然后开始流行一种48%/32%/20%的划分 最开始这个划分的人 Pei, H., Wei, B., Chang, K. C.-C., Lei, Y., and Yang, B. Geom-gcn: Geometric graph convolutional networks. International Conference on Learning Representations, 2019. https://openreview.net/forum?id=S1e2agrFvS接力者若干(这几篇都是沿用相同设置)Yujun Yan, Milad Hashemi, Kevin Swersky, Yaoqing Yang, and Danai Koutra.Two sides of the same coin: heterophily and oversmoothing in graph convolutional neural networks. preprint arXiv:2102.06462 (2021). Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. 2020. Beyond homophily in graph neural networks: Current limitations and effective designs. In Advances in Neural Information Processing Systems, Vol. 33. 某种通用的划分标准。 HAN 原始 https://github.com/Jhy1993/HAN/ DGL https://github.com/dmlc/dgl/blob/master/examples/pytorch/han 异质图总结异质图差点逼疯我。因为涉及到几个框架哥抢市场。。 1.raw version 1.1 DBLP four areaDBLP is a bibliography website of computer science. We use a commonly used subset in 4 areas with nodes representing authors, papers, terms and venues. 下载后的文件应该叫DBLP_four_area.zip(1.99MB)。 这是最原始的文件,zip里面全部都是txt。 从这份声明可以看到 https://github.com/Jhy1993/HAN/tree/master/data/DBLP_four_area 这个数据集是Jing Gao ([email protected]) 和 Yizhou Sun ([email protected])标注的。 Jing Gao, Feng Liang, Wei Fan, Yizhou Sun, Jiawei Han, Graph-based Consensus Maximization among Multiple Supervised and Unsupervised Models". Advances in Neural Information Processing Systems (NIPS), 22, 2009, 585-593. 可以从作者之一的主页下载到标注后的数据集。 http://web.cs.ucla.edu/~yzsun/data/ 备注 需要跟另一个citation network dataset DBLP区分 Shirui Pan, Jia Wu, Xingquan Zhu, Chengqi Zhang, and Yang Wang. Tri-party deep network representation. Network, 11(9):12, 2016. 这个DBLP是同质性的数据集。 因为DBLP是一个网站,任何人从这个上面爬虫一些内容做出来的数据集都叫DBLP! 1.2 IMDBIMDB is a website about movies and related information. A subset from Action, Comedy, Drama, Romance and Thriller classes is used. https://www.kaggle.com/karrrimba/movie-metadatacsv kaggle的公开数据。原始格式是movie-metadata.csv(1.49 MB)。 2.HAN versionHAN版本是jihouye同学于方兴未艾之际抢市场时留下的祸根。 使用了 ACM,DBLP,IMDB 3个数据集。 见仓库 https://github.com/Jhy1993/HAN ACM3025.mat(252M)。 https://pan.baidu.com/s/1V2iOikRqHPtVvaANdkzROw 提取码:50k2 DBLP4057_GAT_with_idx_tra200_val_800.zip(387.2M) https://pan.baidu.com/s/1Qr2e97MofXsBhUvQqgJqDg 提取码:6b3h 解压后是.npy .npz文件。 IMDB5k(545.5M) https://pan.baidu.com/s/199LoAr5WmL3wgx66j-qwaw 密码:qkec 别问我为什么命名这么不规范。。。 甚至解压后的文件排布也很奇葩。。。 备用链接 https://cloud.tsinghua.edu.cn/d/0e784c52a6084b59bdee/?p=%2F&mode=list 需要注意的是!ACM 或者说ACM3025是HAN首次引入的自己采样标注的数据集。 We extract papers published in KDD, SIGMOD, SIGCOMM, MobiCOMM, and VLDB and divide the papers into three classes (Database, Wireless Communication, Data Mining). Then we construct a heterogeneous graph that comprises 3025 papers §, 5835 authors (A) and 56 subjects (S). Paper features correspond to elements of a bag-of-words represented of keywords. We employ the meta-path set {PAP, PSP} to perform experiments. Here we label the papers according to the conference they published. DBLP是MAGNN这篇文章对原始文件的再采样。 IMDB是原始文件的再采样。 We extract a subset of DBLP which contains 14328 papers §, 4057 authors (A), 20 conferences ©, 8789 terms (T). The authors are divided into four areas: database, data mining, machine learning, information retrieval. Also, we label each author’s research area according to the conferences they submitted. Author features are the elements of a bag-of-words represented of keywords. Here we employ the meta-path set {APA, APCPA, APTPA} to perform experiments 虽然HAN原文写的We extract 但实际上使用的是 they extrac。 MAGNN的处理代码 https://github.com/cynricfu/MAGNN/blob/master/preprocess_DBLP.ipynb authors (4,057 nodes), papers (14,328 nodes), terms (7,723 nodes), and conferences (20 nodes) https://arxiv.org/pdf/2002.01680.pdf 解压后一堆.npz和.npy,还有一个文件夹0. 其中文件夹/0/是 post-processing for mini-batched training Here we extract a subset of IMDB which contains 4780 movies (M), 5841 actors (A) and 2269 directors (D). The movies are divided into three classes (Action, Comedy, Drama) according to their genre. Movie features correspond to elements of a bag-of-words represented of plots. We employ the meta-path set {MAM, MDM} to perform experiments. 处理方法见代码(反正我没看) https://github.com/Jhy1993/HAN/blob/master/preprocess_dblp.py 除此之外HAN还使用了FreeBase数据集。 FreeBase is a huge knowledge graph. We sample a subgraph of 8 genres of entities with about 1,000,000 edges following the procedure of a previous survey. FreeBase数据集来自这篇文章。 Carl Yang, Yuxin Xiao, Yu Zhang, Yizhou Sun, and Jiawei Han. 2020. Heterogeneous Network Representation Learning: A Unified Framework with Survey and Benchmark. TKDE (2020) freebase这个东西,后来一直被人忽视。 3.MAGNN versionDBLP node types : [‘author’, ‘conference’, ‘paper’, ‘term’] target node type : ‘author’ feature author torch.Size([4057, 334]) paper torch.Size([14328, 4231]) term torch.Size([7723, 50]) label author torch.Size([4057]) IMDB node types: [‘movie’, ‘director’, ‘actor’] target node type: ‘movie’ feature movie torch.Size([4278, 3066]) director torch.Size([2081, 3066]) actor torch.Size([5257, 3066]) label torch.Size([4278]) 注意,IMDB 4. HGB version来源文章 Are we really making much progress? Revisiting, benchmarking, and refining heterogeneous graph neural networks https://github.com/THUDM/HGB 可能他时隔多年终于发现当年写的东西太丑了, 在HGB版本里面进行了规范化。 现在的文件 info.dat label.dat label.dat.test link.dat node.dat meta.dat(可能没有) url.dat(可能没有)看起来严谨多了对吧。 有一个小细节可以证明他绝对对当年的黑历史感到羞涩。 因为他甚至不敢在自己的torch_geometric 的datasets里面加入自己的HAN版本数据集。。。 只保留了HGBDataset。 完整的HGB版本继承了HAN里的 ACM,DBLP,IMDM,Freebase. 虽然Freebase并不被正式推荐,但是下载source files是会看到有的。 所有数据集一起,zip文件15.6MB,解压后373MB。 警告 HGB不提供test label。 .dat里的test label是随机生成的。 所以你无论怎么学习,平均acc就是1/n_cls。 You should notice that the test data labels are randomly replaced to prevent data leakage issues. If you want to obtain test scores, you need to submit your prediction to our website. 想要具体label需要去biendata这个竞赛网站,以参赛的方式传submission.txt然后看leaderboard结果。 https://www.biendata.xyz/hgb/ 一天限制3次上传!!! 离谱。 拒绝使用HGB。 4. DGL version众所周知DGL的数据底层存储方式跟PYG是有巨大差别的。 我专门研究过一下DGL的API,传送门https://blog.csdn.net/w55100/article/details/121706281。 不得不承认虽然用起来很难受,但还是写的比PYG好一点。 需要注意的是ACM这个数据集,DGL又搞了一份同名的出来。(狗狗摇头.gif) “”“This model shows an example of using dgl.metapath_reachable_graph on the original heterogeneous graph. Because the original HAN implementation only gives the preprocessed homogeneous graph, this model could not reproduce the result in HAN as they did not provide the preprocessing code, and we constructed another dataset from ACM with a different set of papers, connections, features and labels. “”” 因为不知道HAN到底是怎么处理的数据,于是自己又整了一份ACM。。。行吧。 就叫ACM.dat (19.5M) 。 处理方法在这 https://github.com/dmlc/dgl/blob/195f99362d883f8b6d131b70a7868a537e55b786/examples/pytorch/han/utils.py def load_acm 加载HAN引进版 ACM3025.pkl 。 def load_acm_raw 加载dgl尊享版ACM.mat。 HGB来源文章 Are we really making much progress? Revisiting, benchmarking, and refining heterogeneous graph neural networks https://github.com/THUDM/HGB ACM,DPLB,IMDB 作者自称 24% for training, 6% for validation and 70% for test in each dataset 1.ACMHAN (WWW19)里用的subset。保留所有citation和reference边。 这个subset压缩后只有十几M,原始的ACM3025压缩后有一百多M。 > print(num_nodes_dict) ...{'paper': 3025, 'author': 5959, 'subject': 56, 'term': 1902} >for k in x_dict.keys(): print(k,np.array(x_dict[k]).shape ) ... paper (3025, 1902) author (5959, 1902) subject (56, 1902) term (0,) #4种结点类型。且各类别在node.dat中规律顺序排列。 #只有term未给出feature,其余feature维度均为1902。 #因为term就是feature本身,注意到1902个term,特征上{1,0}代表是否包含此term。 #所以特征矩阵的行数= 3025+5959+56 = 9040 >print(e_types) ... {0: ('paper', 'cite', 'paper'), 1: ('paper', 'ref', 'paper'), 2: ('paper', 'to', 'author'), 3: ('author', 'to', 'paper'), 4: ('paper', 'to', 'subject'), 5: ('subject', 'to', 'paper'), 6: ('paper', 'to', 'term'), 7: ('term', 'to', 'paper')} #8种edge type,不区分方向的话只有4对。 >print(info) ...{'node.dat': {'node type': {'0': 'paper', '1': 'author', '2': 'subject', '3': 'term'}}, 'link.dat': {'link type': {'0': {'start': 0, 'end': 0, 'meaning': 'paper-cite-paper'}, '1': {'start': 0, 'end': 0, 'meaning': 'paper-ref-paper'}, '2': {'start': 0, 'end': 1, 'meaning': 'paper-author'}, '3': {'start': 1, 'end': 0, 'meaning': 'author-paper'}, '4': {'start': 0, 'end': 2, 'meaning': 'paper-subject'}, '5': {'start': 2, 'end': 0, 'meaning': 'subject-paper'}, '6': {'start': 0, 'end': 3, 'meaning': 'paper-term'}, '7': {'start': 3, 'end': 0, 'meaning': 'term-paper'}}}, 'label.dat': {'node type': {'0': {'0': 'database', '1': 'wireless communication', '2': 'data mining'}}}} #上面是ACM的info 注意到label.dat指出了,ACM预测结点分类任务,只针对'0'类型的node,即paper结点进行预测,每个paper结点属于3个类别,database, wireless communication, data mining. >print(len(train_ys)) >print(len(test_ys)) ... 907 训练集 paper类型 (of 3025) 3025*0.24=726, val应该是907-726=181。 2118 测试集 paper类型 (of 3025) 2.DBLP {'node.dat': {'node type': {'0': 'author', '1': 'paper', '2': 'term', '3': 'venue'}, 'Attribute Dimension': {'0': '0', '1': '4231', '2': '50', '3': '0'}}, 'link.dat': {'link type': { '0': {'start': '0', 'end': '1', 'meaning': 'author-paper'}, '1': {'start': '1', 'end': '2', 'meaning': 'paper-term'}, '2': {'start': '1', 'end': '3', 'meaning': 'paper-venue'}, '3': {'start': '1', 'end': '0', 'meaning': 'paper-author'}, '4': {'start': '2', 'end': '1', 'meaning': 'term-paper'}, '5': {'start': '3', 'end': '1', 'meaning': 'venue-paper'}}}, 'label.dat': { 'node type': {'0': {'0': 'Database', '1': 'Data Mining', '2': 'AI', '3': 'Information Retrieval'}}}}这个数据集比较奇葩。 author类结点不给features, paper类结点4231维, term类结点50维, venue类结点不给feature。 3.IMDB 注意HGB的代码,在multi-label上,如IMDB,通常需要sigmoid后利用一个threshold超参来判正负,再算f1_score。此处写死threshold=0.5。 https://github.com/THUDM/HGB/blob/master/NC/benchmark/methods/RGCN/entity_classify.py 详见def multi_evaluate(model_pred, labels)函数。 benchmarkHGB是一个很神奇的东西。。 异质图NC可以认为有老4样,aAIFB,MUTAG,BGS,AM。 Resource Description Framework (RDF) format (Ristoski, deVries, and Paulheim 2016) Modeling Relational Data with Graph Convolutional Networks https://arxiv.org/abs/1703.06103 http://dws.informatik.uni-mannheim.de/en/research/a-collection-of-benchmark-datasets-for-ml 统计 #AIFB Total #nodes: 7262 Total #edges: 48810 #Node types: 7 #Canonical edge types: 104 #Unique edge type names: 78 - Target Category: Personen - target node number 237 - Number of Classes: 4 - Label Split: - Train: 140 - Test: 36MUTAG - Nodes: 27163 - Edges: 148100 (including reverse edges) - ntypes: 5 - etypes: 50 - Target Category: d - target node number 9529 - Number of Classes: 2 - Label Split: - Train: 272 - Test: 68 BGS #Node types: 27 #Canonical edge types: 122 #Unique edge type names: 96 - Nodes: 94806 - Edges: 672884 (including reverse edges) - Target Category: Lexicon/NamedRockUnit - target node number : 18002 - Number of Classes: 2 - Label Split: - Train: 117 - Test: 29HGB based on DGL 在老4样上的结果。 AIFBMUTAGBGSAMGCN97.2273.8286.2181.92GAT72.6586.21RGCN95.8373.2383.190.4RGCN on paper92.5970.188.5189.29splits218,54,68来源https://github.com/THUDM/HGB/tree/master/NC/RGCN 可是有一个BUG。 #https://github.com/THUDM/HGB/blob/master/NC/RGCN/entity_classify.py #Line:182 logits = F.softmax(logits) loss = F.cross_entropy(logits[train_idx], labels[train_idx])显然ce之前是不需要softmax的。 我把softmax去掉之后… HGB作者也没有固定seed,导致每次跑的结果都不一样。 我随便给了个seed,现在结果稳定了。 括号里是加上softmax的结果。括号外去掉softmax。 AIFBMUTAGBGSAMGCN(seed)97.22(94.44)73.53(75)86.71(82.76)78.28(72.73)GCN(repo)97.2273.8286.2181.92在新4样的结果。 Q:HGB代码里是怎么在异质图上跑GCN的。 A:跑GCN和GAT的时候 把feature变成一个对角单位阵 意思是 input feature is then the node id. 于是结点数即是输入维度。 详见源码https://github.com/THUDM/HGB/blob/master/NC/RGCN/entity_classify.py if args.model =='gcn' model = GCN(input_dim=num_nodes,...) if args.model in ['gcn],'gat']: i = torch.LongTensor([[i for i in range(num_nodes)], [ i for i in range(num_nodes)]]) v = torch.FloatTensor([1 for i in range(num_nodes)]) feats = torch.sparse.FloatTensor( i, v, torch.Size([num_nodes, num_nodes]))model 到loss,用的cri和acti。 贰、 Link PredcitionLP任务比较靠近下游。知识图谱或者推荐关系发掘。 一般是跟在表征学习之后,再加一个下游 decoder去学link概率。 所以理论上任何一个NC Dataset都可以经过采样变成LP Dataset。。。 (以原本存在的edge作为正样本,不存在的edge作为负样本) 所以比baseline的本质,是比embedding learning,decoder部分一般是dotmul/distmul。 然后这个领域。。。似乎不存在一个很标准很统一的benchmark。 为了稍示区别,还是找几个特别一点的。 最经典的MovieLen10M, IMDB… 就不提了吧。 LastFm这是一家音乐网站的名字。HetRec2011中提供了一份爬虫数据。 我称之为’HetRec-LastFm-2k’ 之所以叫2k是因为有1892 users,接近2千个。 来源 Iván Cantador, Peter Brusilovsky, and Tsvi Kuflik. 2011. Second workshop on information heterogeneity and fusion in recommender systems (HetRec2011). In RecSys’11. 387–388 https://dl.acm.org/doi/pdf/10.1145/3292500.3330961 LP-知识图谱WN18 (WordNet18) 因为有18个relations WN18RR : Subset of WN18 FB15k (FreeBase15k) 这俩都被dgl收录了 from dgl.data.knowledge_graph import load_data dl = load_data(‘wn18’) # return WN18Dataset() dl = load_data(‘FB15k’) # return FB15kDataset() dl = load_data('FB15k237) #return FB15k237Dataset() HNE版本有一篇的IEEE TKDE2020的survey做了4个数据集。 DBLP,Yelp, Freebase ,PubMed Carl Yang, Yuxin Xiao, Yu Zhang, Yizhou Sun, and Jiawei Han. 2020. Heterogeneous Network Representation Learning: A Unified Framework with Survey and Benchmark. TKDE (2020). 当然了。。。叫这些名字的数据集实!在!太!多!了! 增加前缀以示区分 HNE-PubMed,HNE-Freebase, HNE-DBLP, HNE-Yelp。 作者提到DBLP是使用最多的,因为所有数据公开而且没有版权或者privacy纠纷。 Yelp是推荐系统里用的多的。 Freebase是知识图谱。 PubMed生物医学。 三、图分类数据集 TUDataSetTUDataset: A collection of benchmark datasets for learning with graphs https://arxiv.org/abs/2007.08663 https://chrsmrrs.github.io/datasets/docs/datasets/ 这个数据集有些时候是没有attribute的 https://github.com/dmlc/dgl/tree/master/python/dgl/data/tu.py LegacyTUDataset uses provided node feature by default. If no feature provided, it uses one-hot node label instead. If neither labels provided, it uses constant for node feature. The dataset sorts graphs by their labels. Shuffle is preferred before manual train/val split. dgl整理了几个常用子数据集,下面numfeats处'-'就表示不提供node feat。 DDPROTEINSENZYMESIMDB-BINARYIMDB-MULTICOLLABNumGraphs11781113600100015005000AvgNodesPerGraph284.3239.0632.6319.7713.0074.49AvgEdgesPerGraph715.6672.8262.1496.5365.942457.78NumFeats89118---NumClasses226232 其他版本区别于公开数据集对于谁会使用自己的不可知性 (paper-agnostic datasets), 某些文章会收录一些公开数据集,然后自己做点二次加工,产生variant。 这种就是 paper-specific-datasets。 GIN版来自这篇文章 Graph Isomorphism Network How Powerful are Graph Neural Networks? ICLR2019 https://arxiv.org/pdf/1810.00826.pdf https://github.com/weihua916/powerful-gnns 数据集 ‘MUTAG’, ‘COLLAB’, ‘IMDB-BINARY’, ‘IMDB-MULTI’, ‘NCI1’, ‘PROTEINS’, ‘PTC’, ‘REDDIT-BINARY’, ‘REDDIT-MULTI5K’ node feat的处理 Importantly, our goal here is not to allow the models to rely on the input node features but mainly learn from the network structure. Thus, in the bioinformatic graphs, the nodes have categorical input features but in the social networks, they have no features. For social networks we create node features as follows: for the REDDIT datasets, we set all node feature vectors to be the same (thus, features here are uninformative); for the other social graphs, we use one-hot encodings of node degrees srcfile https://raw.githubusercontent.com/weihua916/powerful-gnns/master/dataset.zip 这个dataset.zip解压后得到 … / COLLAB/ …/COLLAB.mat …/COLLAB.txt …/10fold_idx目录 这个版本的数据集后续被GraphNorm引用了。 https://github.com/lsj2408/GraphNorm 可以参考它的处理方法,base on dgl。 https://github.com/lsj2408/GraphNorm/GraphNorm_ws/gnn_ws/gnn_example/Temp/dataset.py 虽然paper里报的数据集统计特征是一样的。 但是GIN版本是作者预处理好的.mat,.txt,不是from scratch的。。 这样的东西总是让人不放心啊。。。 这东西也被dgl收录了。 from dgl.data import GINDataset GINDataset的问题 1. 没有validation set代码里有split_fold10函数。 可以产出train_idx, val_idx。 但是没有测试集。 因为这里的val_idx就是作者论文里的测试集了。 作者是这么解释的 https://github.com/weihua916/powerful-gnns/readme.md The cross-validation in our paper only uses training and validation sets (no test set) due to small dataset size. Specifically, after obtaining 10 validation curves corresponding to 10 folds, we first took average of validation curves across the 10 folds (thus, we obtain an averaged validation curve), and then selected a single epoch that achieved the maximum averaged validation accuracy. Finally, the standard devision over the 10 folds was computed at the selected epoch. 它记录10折内,所有epoch的valid_acc。 对每个epoch,算10折的mean,std,max,min。 res[epoch] = np.mean(raw[epoch]) 然后取所有epoch mean中最高的mean acc作为best performance。 best_perform = np.max( [ v for k,v in res.items() ] ) 2.feat预处理方式不统一constant,label onhot, degree onehot 化学领域 QM9Ramakrishnan, Raghunathan, Dral, Pavlo O, Rupp, Matthias, and Von Lilienfeld, O Anatole. Quantum chemistry structures and properties of 134 kilo molecules. Scientific data, 1, 2014. paper: https://www.nature.com/articles/sdata201422.pdf 开源主页 http://quantum-machine.org/datasets/ 这里有一个非官方的快速下载QM9的download脚本 https://github.com/priba/nmp_qc/tree/master/data 一共6个raw文件。4个较小的txt描述性文件。2个较大的核心数据文件。 Alchemy: A Quantum Chemistry Dataset for Benchmarking AI Models https://arxiv.org/abs/1906.09427v1 https://alchemy.tencent.com/ 腾讯19年比赛数据集。 现在去官网大概下载不到了。 向其他有的人要来试试吧。 DeepChem提供了一些化学领域的基础模型和数据集。 deepchem https://arxiv.org/pdf/1703.00564.pdf https://deepchem.io/ 另一篇综述 https://arxiv.org/pdf/2011.14867.pdf |
 这样只有adj和feature。 而具体的划分方式splt_idx,在 https://github.com/graphdml-uiuc-jlu/geom-gcn的 /splits/目录内。 每个数据集对应10种划分,每个划分为1个.npz文件。 即每个数据集最终有10个.npz划分文件。
这样只有adj和feature。 而具体的划分方式splt_idx,在 https://github.com/graphdml-uiuc-jlu/geom-gcn的 /splits/目录内。 每个数据集对应10种划分,每个划分为1个.npz文件。 即每个数据集最终有10个.npz划分文件。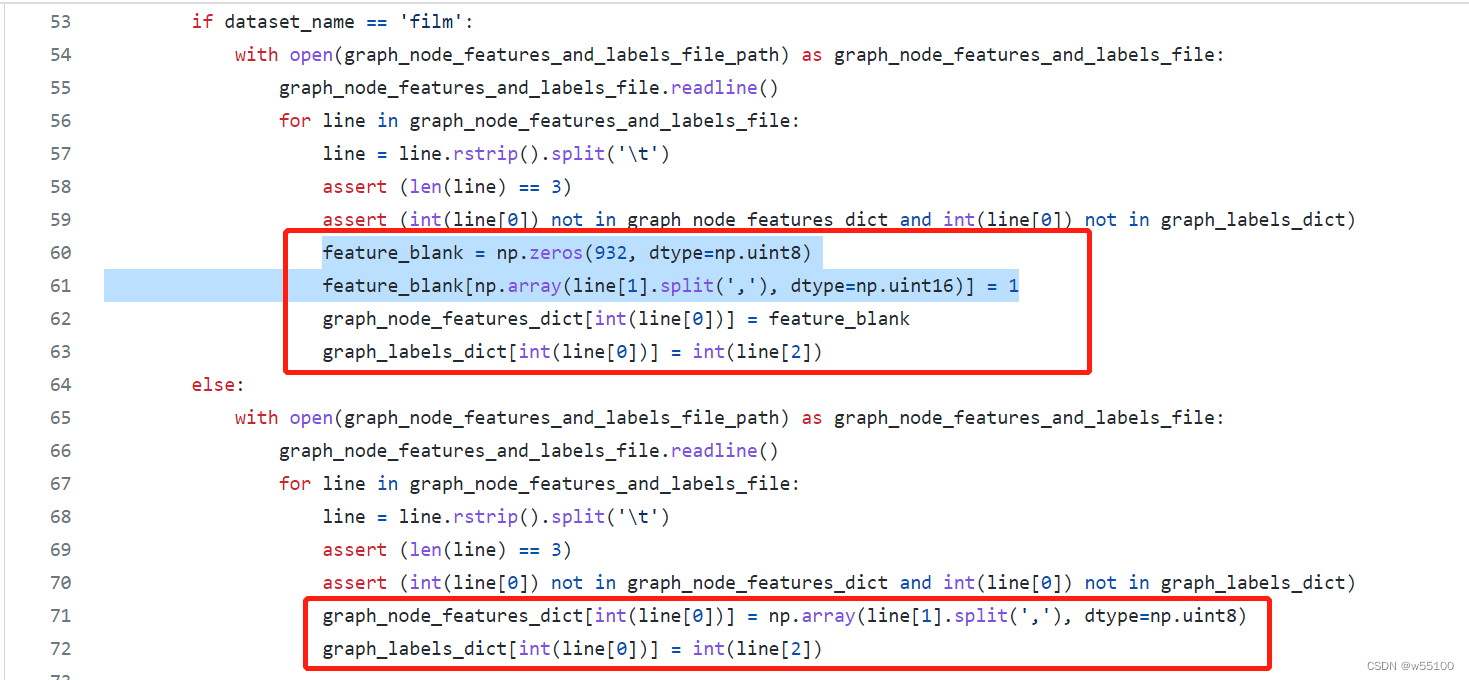

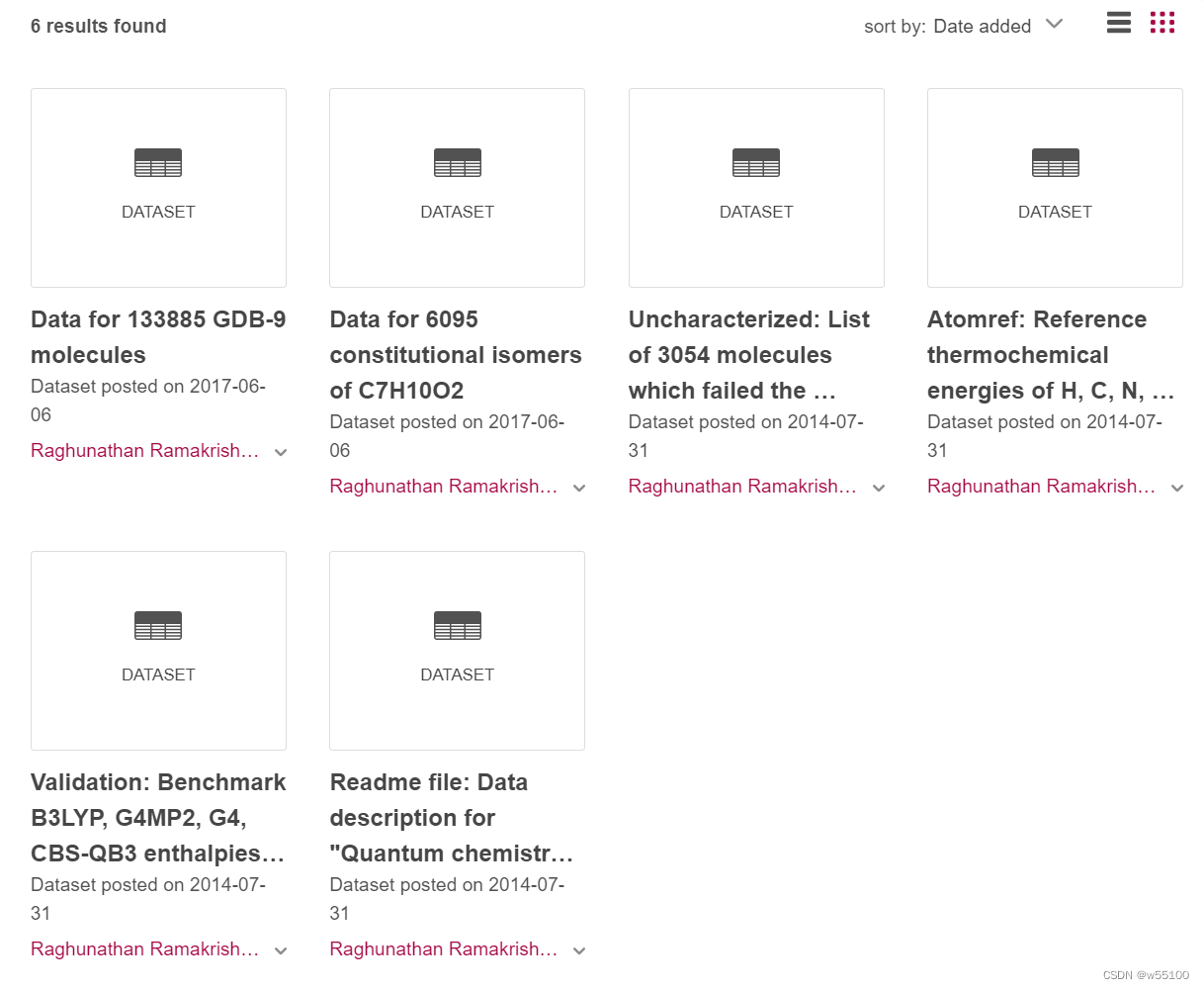
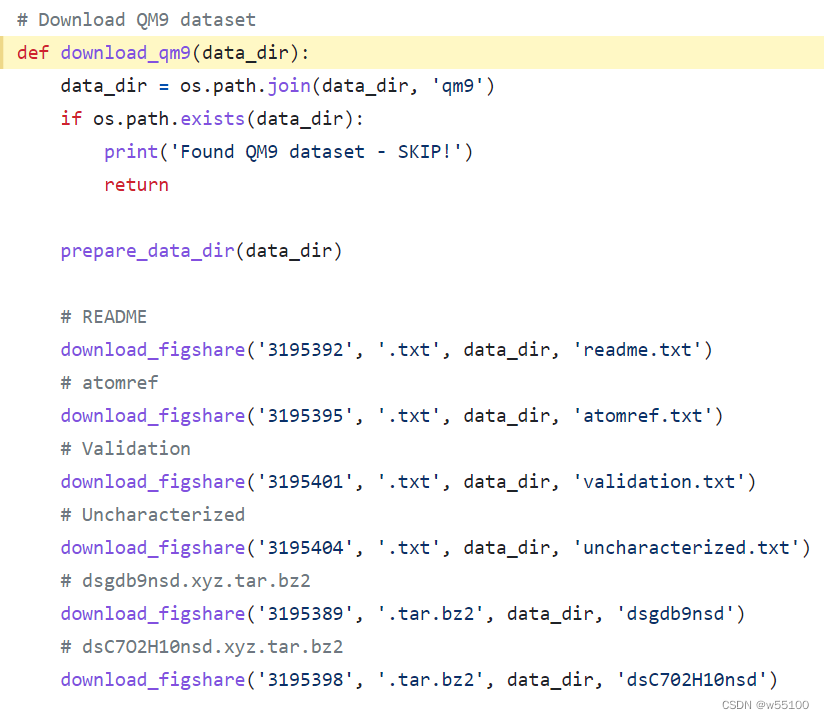 最后两个大文件是压缩包。解压后得到2个目录。
最后两个大文件是压缩包。解压后得到2个目录。  目录里都是.xyz文件。
目录里都是.xyz文件。  计数
计数【本文地址】