| JVM监控及诊断工具 | 您所在的位置:网站首页 › JVM监控工具有哪些 › JVM监控及诊断工具 |
JVM监控及诊断工具
|
工具概述
使用前面的命令行能够获取目标Java应用性能相关的基础信息,但它们存在下列局限: 无法获取方法级别的分析数据,如方法间的调用关系、各方法的调用次数和调用时间等(这对定位应用性能瓶颈至关重要)。 要求用户登录到目标Java应用所在的宿主机上,使用起来不是很方便。 分析数据通过终端输出,结果展示不够直观。为此,JDK提供了一些内存泄漏的分析工具,如jconsole、jvisualVM等,用于辅助开发人员定位问题,但是这些工具很多时候并不足以满足快速定位的需求,所以这里我们介绍的工具相对多一些、丰富一些。 图形化综合诊断工具 JDK自带的工具 jconsole:JDK自带的可视化监控工具。查看Java应用程序的运行概况、监控堆信息、永久区(或元空间)使用情况、类加载情况等。位置:jdk\bin\jconsole.exe visual VM:visual vm是一个工具,它提供了一个可视界面,用于查看Java虚拟机上运行的基于Java技术的应用程序的详细信息。位置:jdk\bin\jvisualvm.exe JMC:Java Mission Control,内置Java Flight Recorder。能够以极低的性能开销收集Java虚拟机的性能数据。 第三方工具 MAT:MAT(Memory Analyzer Tool)是基于Eclipse的内存分析工具,是一个快速、功能丰富的Java heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗。Eclipse的插件形式。 JProfiler:商业软件,需要付费,功能强大。与VisualVM类似 Arthas:Alibaba开源的Java诊断工具,深受开发者喜爱。 Btrace:Java运行时追踪工具。可以在不停机的情况下,跟踪指定的方法调用、构造函数调用和系统内存等信息。 jconsoleJConsole,顾名思义,就是“Java 控制台”,从Java5 开始,在JDK中自带的java监控和管理控制台。用于对JVM中内存、线程和类等的监控,是一个基于JMX(java management extensions)的GUI性能监控图形界面工具。主要是 3 款:JConsole、JVisualVM、JMC。这三个工具都支持我们分析本地 JVM 进程,或者通过 JMX 等方式连接到远程 JVM 进程。当然,图形界面工具的版本号和目标 JVM 不能差别太大,否则可能会报错。在这里,我们可以从多个维度和时间范围去监控一个 Java 进程的内外部指标。进而通过这些指标数据来分析判断 JVM 的状态,为我们的调优提供依据。 三种连接方式 Loca:使用JConsole连接一个正在本地系统运行的JVM,并且执行程序的和运行JConsole的需要是同一个用户。JConsole使用文件系统的授权通过RMI连接器连接到平台的MBean服务器上。这种从本地连接的监控能力只有Sun的JDK具有。 Remote:使用下面的URL通过RMI连接器连接到一个JMX代理,service:jmx:rmi:///jndi/rmi://hostName:portNum/jmxrmi。JConsole为建立连接,需要在环境变量中设置mx.remote.credentials来指定用户名和密码,从而进行授权。 Advanced:使用一个特殊的URL连接JMX代理。一般情况使用自己定制的连接器而不是RMI提供的连接器来连接JMX代理,或者是一个使用JDK1.4的实现了JMX和JMX Rmote的应用。在 Windows 或 macOS 的运行窗口或命令行输入 jconsole,然后回车,可以看到如下界面:
本地进程列表列出了本机的所有 Java 进程(远程进程后续讲解),选择一个要连接的 Java 进程,点击连接,然后可以看到如下界面:
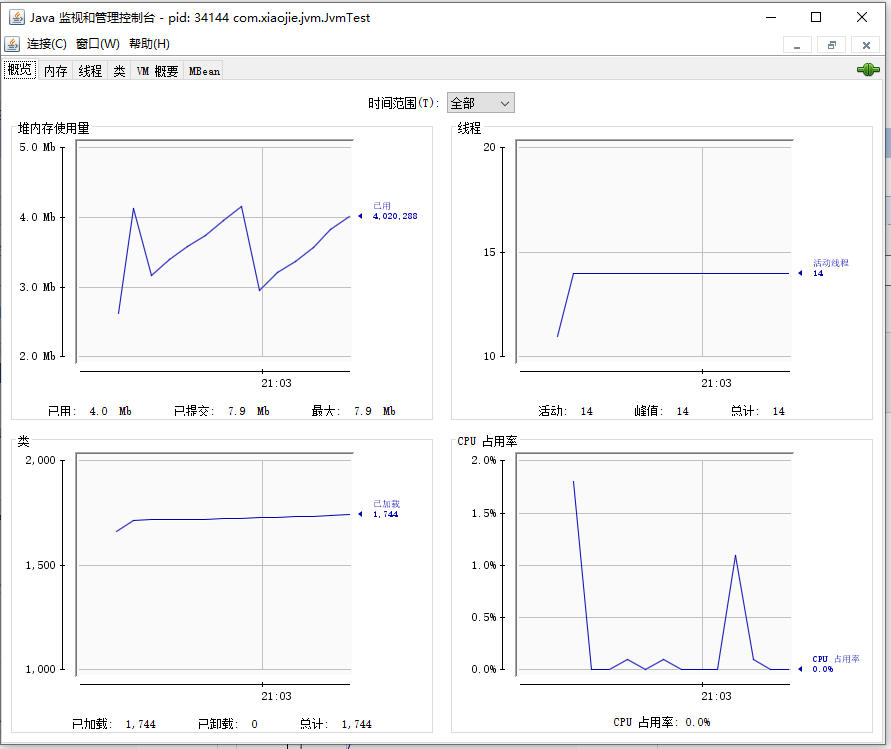
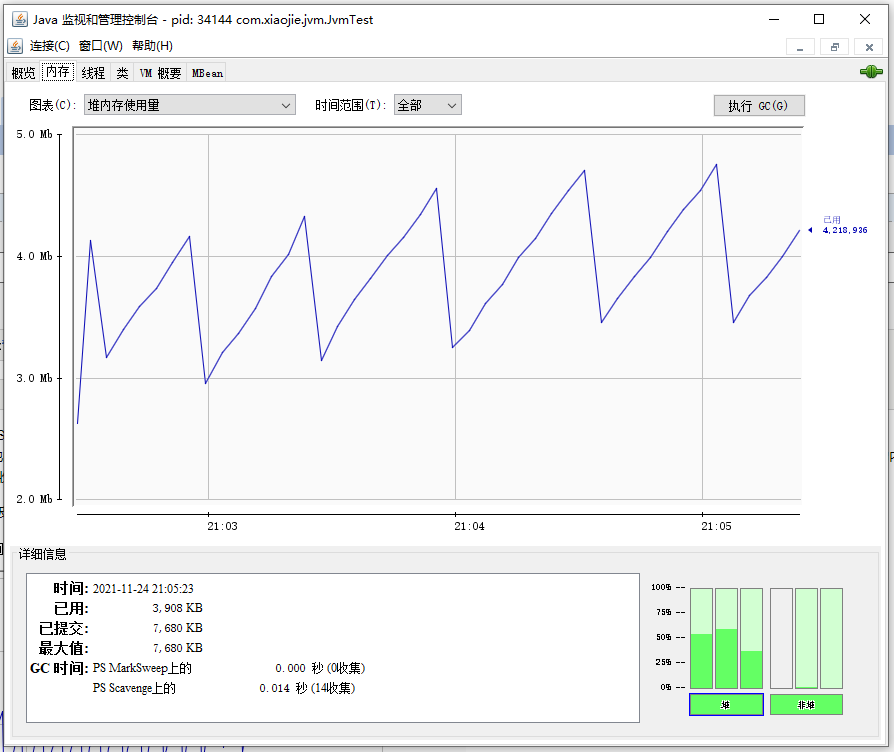
注意,点击右上角的绿色连接图标,即可连接或断开这个 Java 进程。 上图中显示了总共 6 个标签页,每个标签页对应一个监控面板,分别为: 概览:以图表方式查看 Java 进程的堆内存、线程、类、CPU 占用率四项指标和历史。 内存:JVM 的各个内存池的使用情况以及明细。 线程:JVM 内所有的线程列表和具体的状态信息。 类:JVM 加载和卸载的类数量汇总信息。 VM 概要:JVM 的供应商、运行时间、JVM 参数,以及其他数据的摘要。 MBean:跟 JMX 相关的 MBean,后续讲解。 概览概览信息见上图,四项指标具体为: 堆内存使用量:此处展示的就是前面 Java 内存模型课程中提到的堆内存使用情况,从图上可以看到,堆内存使用了 4MB 左右,并且一直在增长。 线程:展示了 JVM 中活动线程的数量,当前时刻共有 14 个活动线程。 类:JVM 一共加载了 1744 个类,没有卸载类。 CPU 占用率:目前 CPU 使用率为 0.0%,这个数值非常低,且最高的时候也不到 2%,初步判断系统当前并没有什么负载和压力。在概览面板中,我们可以看到从 JConsole 连接到 Java 进程之后的所有数据。但是如果从连接进程到现在的时间很长,比如 2 天,那么这里的图表就因为要在一个界面展示而挤压到一起,历史的数据被平滑处理了,当前的变化细节就看不清楚。 所以,JConsole 提供了多个时间范围供我们选择,点击时间范围后面的下拉列表,即可查看不同区间的数据。有如下几个时间维度可供选择:1 分钟、5 分钟、10 分钟、30 分钟、1 小时、2 小时、3 小时、6小时、12 小时、1 天、7 天、1 个月、3 个月、6 个月、1 年、全部,一共是 16 档。 当我们想关注最近 1 小时或者 1 分钟的数据,就可以选择对应的档。旁边的 3 个标签页(内存、线程、类),也都支持选择时间范围。 内存
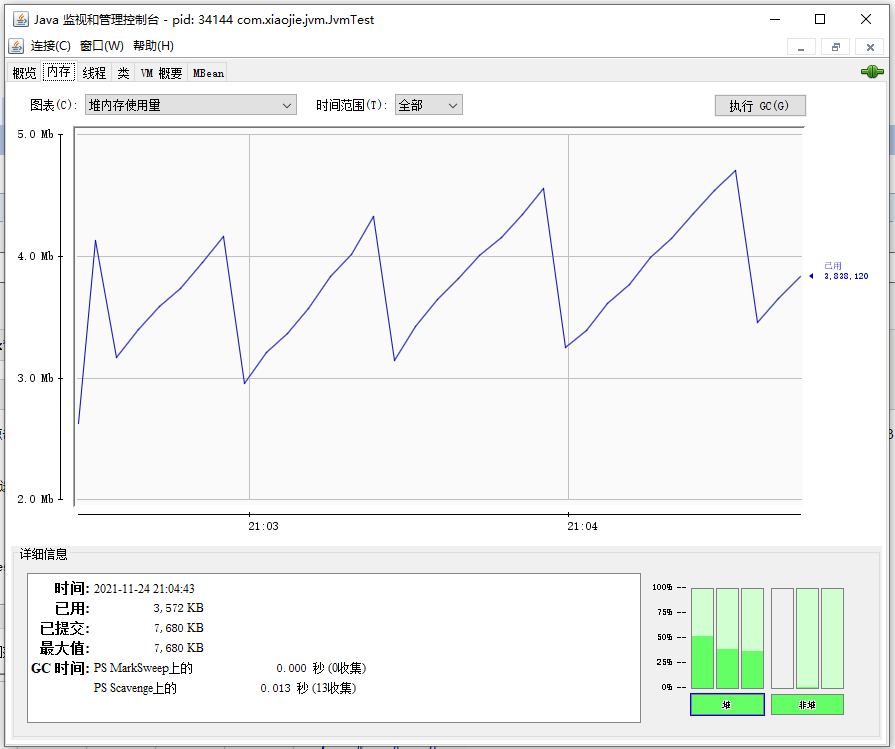
内存监控,是 JConsole 中最常用的面板。内存面板的主区域中展示了内存占用量随时间变化的图像,可以通过这个图表,非常直观地判断内存的使用量和变化趋势。 同时在左上方,我们可以在图表后面的下拉框中选择不同的内存区:
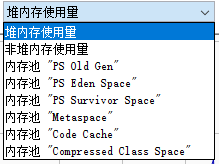
本例中,我们使用的是 JDK 8,默认不配置 GC 启动参数。可以看到,这个 JVM 提供的内存图表包括: 堆内存使用量,主要包括老年代(内存池“PS Old Gen”)、新生代(“PS Eden Space”)、存活区(“PS Survivor Space”); 非堆内存使用量,主要包括内存池“Metaspace”、“Code Cache”、“Compressed Class Space”等; 可以分别选择对应的 6 个内存池。通过内存面板,我们可以看到各个区域的内存使用和变化情况,并且可以: 手动执行 GC,点击按钮即可执行 JDK 中的 System.gc(),直接触发 GC 操作,一般来说,除非启动时明确指定了禁止手动 GC,否则 JVM 都会立刻执行 FullGC; 通过图中右下角的界面,可以看到各个内存池的百分比使用率,以及堆/非堆空间的汇总使用情况,这个图会实时变化,同时可以直接点击这里的各个部分快速切换上方图表,显示对应区域的内存使用情况; 从左下角的界面,可以看到 JVM 使用的垃圾收集器,以及执行垃圾收集的次数,以及相应的时间消耗。打开一段时间以后,我们可以看到内存使用量出现了波峰曲线,只要曲线出现了下降就表明经过了一次 GC,也就是 JVM 执行了垃圾回收。
其实我们可以注意到,内存面板其实相当于是 jstat -gc 或 jstat -gcutil 命令的图形化展示,它们的本质是一样的,都是通过采样的方式拿到JVM各个内存池的数据进行统计,并展示出来。 其实图形界面存在一个问题,如果 GC 特别频繁,每秒钟执行了很多次 GC,实际上图表方式就很难反应出每一次的变化信息。 线程线程面板展示了线程数变化信息,以及监测到的线程列表。 我们可以常根据名称直接查看线程的状态(运行还是等待中)和调用栈(正在执行什么操作)。 特别地,我们还可以直接点击“检测死锁”按钮来检测死锁,如果没有死锁则会提示“未检测到死锁”。
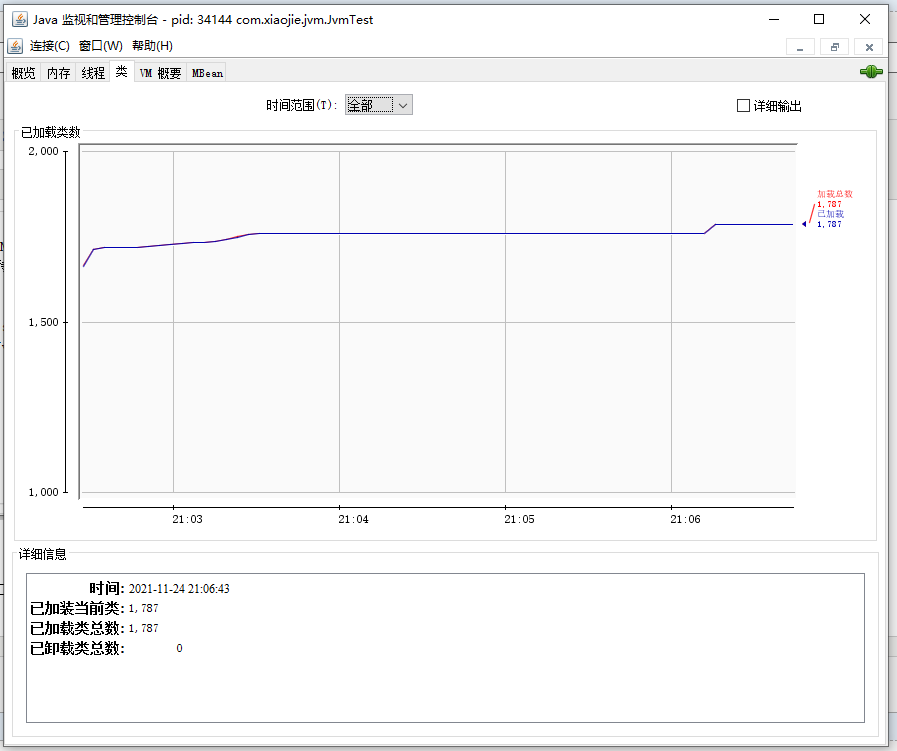
类监控面板,可以直接看到 JVM 加载和卸载的类数量汇总信息。
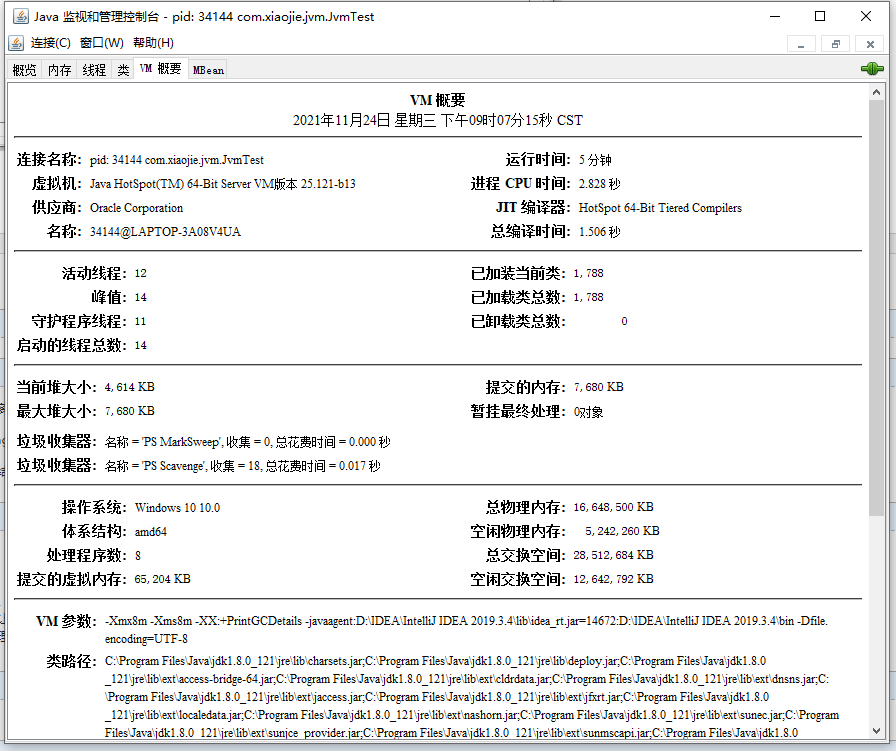
VM 概要的数据也很有用,可以看到总共有五个部分: 第一部分是虚拟机的信息; 第二部分是线程数量,以及类加载的汇总信息; 第三部分是堆内存和 GC 统计; 第四部分是操作系统和宿主机的设备信息,比如 CPU 数量、物理内存、虚拟内存等等; 第五部分是 JVM 启动参数和几个关键路径,这些信息其实跟 jinfo 命令看到的差不多。 JVisualVM 图形界面监控工具Visual vm是一个功能强大的多合一故障诊断和性能监控的可视化工具。它集成了多个JDK命令行工具,使用visual vm可用于显示虚拟机进程及进程的配置和环境信息(jps、jinfo),监视应用程序的CPU、GC、堆、方法区及线程的信息(jstat、jstack)等,甚至代替Jconsole。在JDK 6 Update 7 以后,Visual VM便成为JDK的一部分发布。此外,Visual VM也可以作为独立的软件安装。 连接方式 本地连接:监控本地Java进程的CPU、类、线程等 远程连接: 确定远程服务器的ip地址 添加JMX(通过JMX技术具体监控远端服务器的某个Java进程) 修改bin/catalina.sh文件,连接远程的tomcat 在…/conf中添加jmxremote.access和jmxremote.password文件 将服务器地址改成公网ip地址 设置阿里云安全策略和防火墙策略 启动tomcat,查看tomcat启动日志和端口监听 JMX中输入端口号、用户名、密码登录 主要功能 生成/读取堆内存快照 查看JVM参数和系统属性 查看运行中的虚拟机进程 生成/读取线程快照 程序资源的实时监控 其他功能:JMX代理连接,远程环境监控,CPU分析和内存分析在命令行或者运行窗口直接输入 jvisualvm 即可启动,JVisualVM 启动后的界面大致如下:
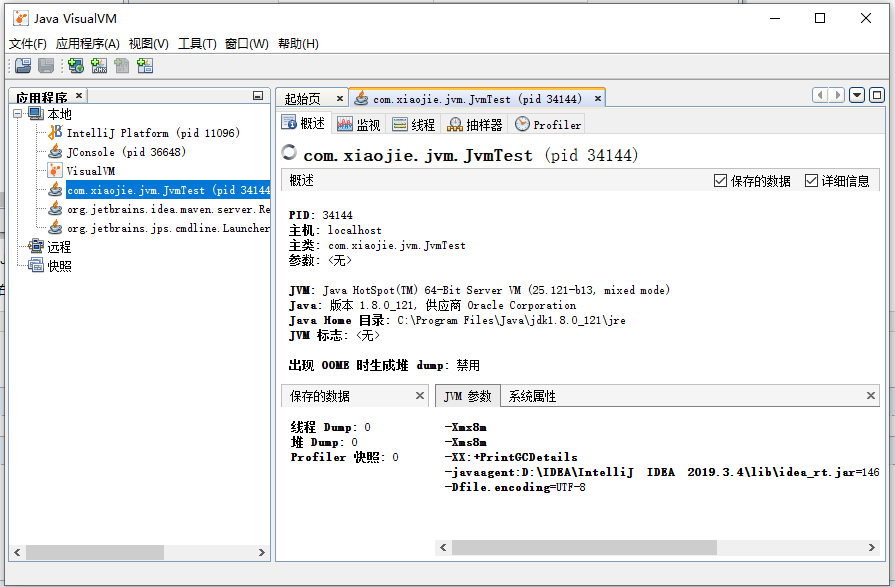
在其中可以看到本地的 JVM 实例。 通过双击本地进程或者右键打开,就可以连接到某个 JVM,此时显示的基本信息如下图所示:
可以看到,在概述页签中有 PID、启动参数、系统属性等信息。 切换到监视页签: 如果没有监视页签选项,需要安装插件,但是默认的下载地址不对,需要配置,修改的具体地址可以在下面的地址中找到https://visualvm.github.io/pluginscenters.html
修改以后,就可以看见能安装的插件列表
现在点开监视页签
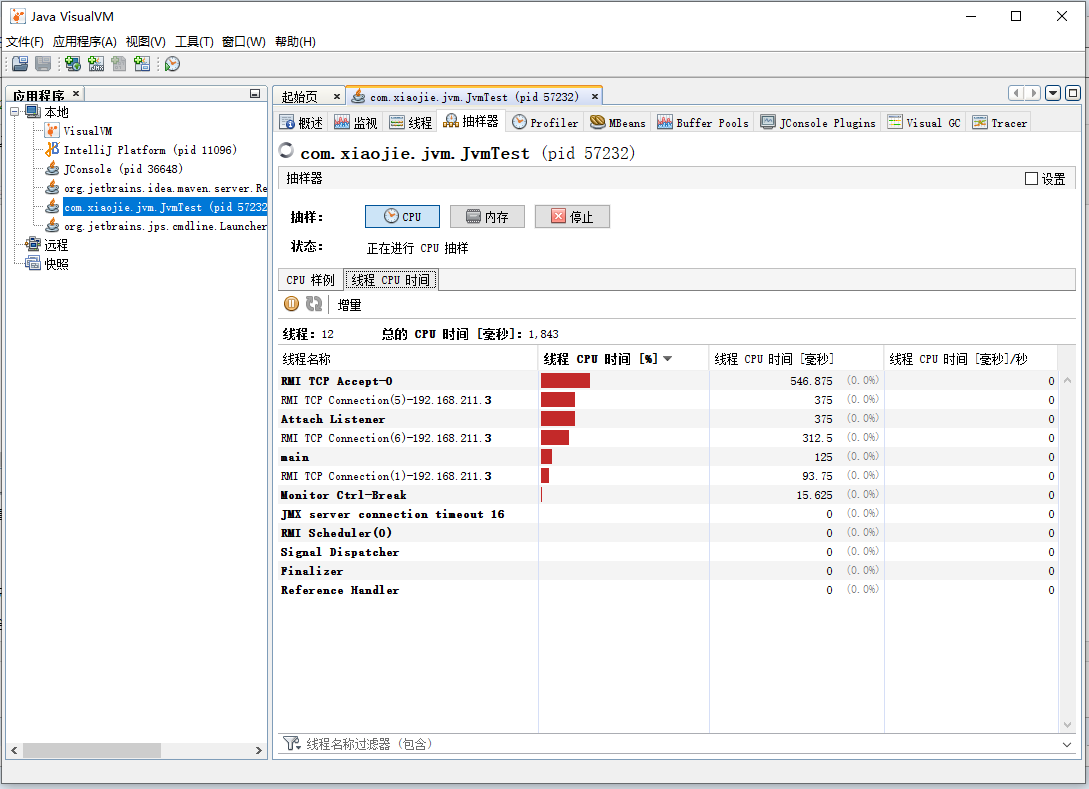
在监视页签中可以看到 JVM 整体的运行情况。比如 CPU、堆内存、类、线程等信息。还可以执行一些操作,比如“强制执行垃圾回收”、“堆 Dump”等。 "线程"页签则展示了 JVM 中的线程列表。
与 JConsole 只能看线程的调用栈和状态信息相比,这里可以直观看到所有线程的状态颜色和运行时间,从而帮助我们分析过去一段时间哪些线程使用了较多的 CPU 资源。 抽样器与 ProfilerJVisualVM 默认情况下,比 JConsole 多了抽样器和 Profiler 这两个工具。 例如抽样,可以配合我们在性能压测的时候,看压测过程中,各个线程发生了什么、或者是分配了多少内存,每个类直接占用了多少内存等等。
使用 Profiler 时,需要先校准分析器。
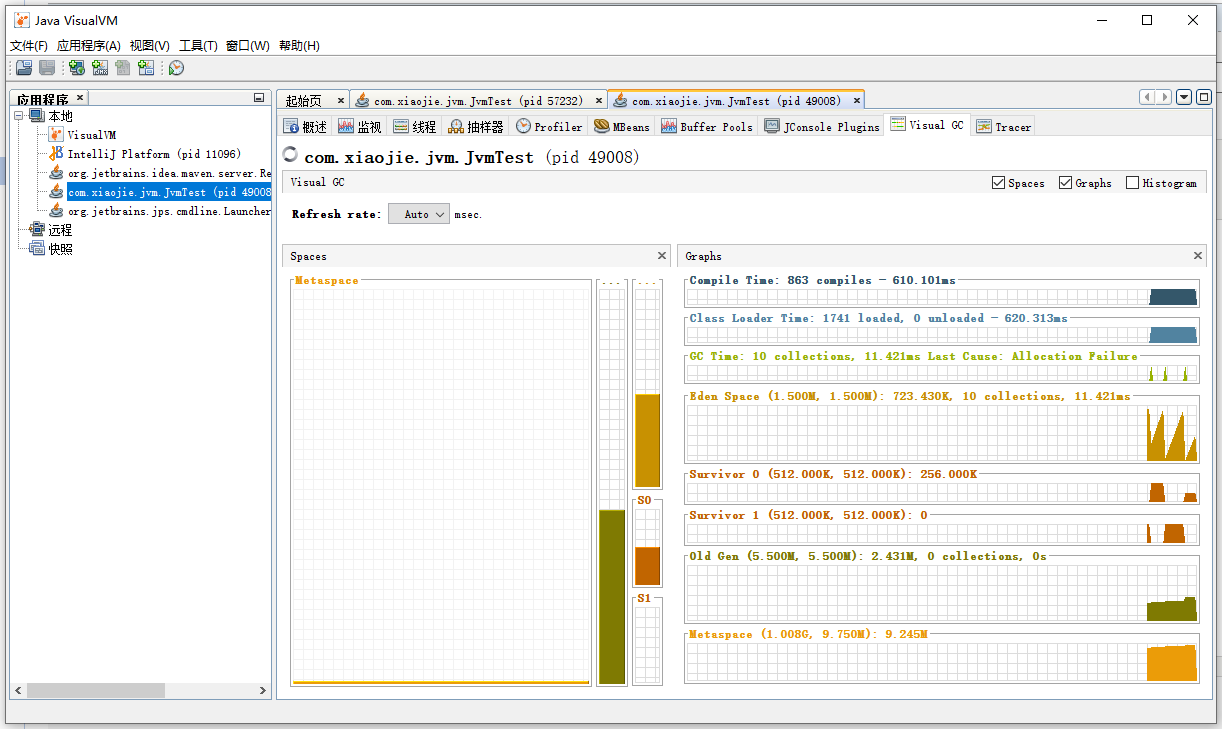
然后可以像抽样器一样使用了。 Profiler 面板直接能看到热点方法与执行时间、占用内存以及比例,还可以设置过滤条件。 同时我们可以直接把当前的数据和分析,作为快照保存,或者将数据导出,以后可以继续加载和分析。 VisualGC 页签:
在其中可以看到各个内存池的使用情况,以及类加载时间、GC 总次数、GC 总耗时等信息。比起命令行工具要简单得多。 MBeans 标签:
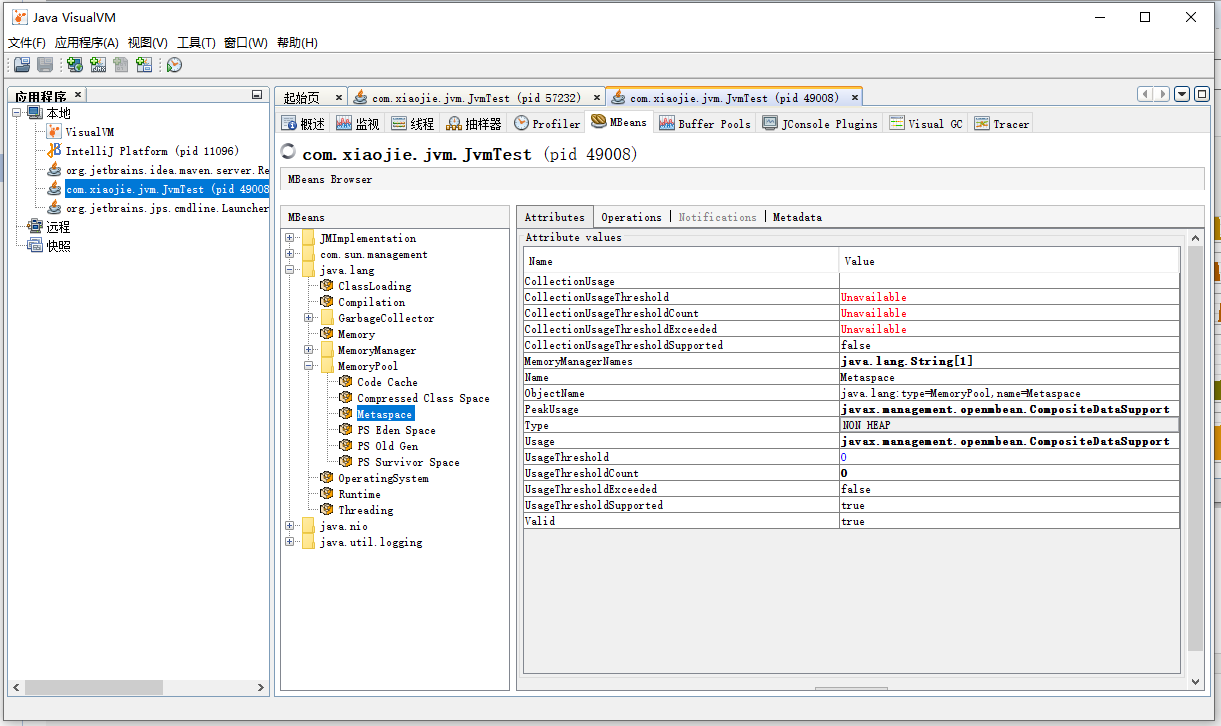
主要看 java.lang 包下面的 MBean。比如内存池或者垃圾收集器等。 从图中可以看到,Metaspace 内存池的 Type 是 NON_HEAP。 当然,还可以看垃圾收集器(GarbageCollector)。 对所有的垃圾收集器,通过 JMX API 获取的信息包括: CollectionCount:垃圾收集器执行的 GC 总次数。 CollectionTime:收集器运行时间的累计,这个值等于所有 GC 事件持续时间的总和。 LastGcInfo:最近一次 GC 事件的详细信息。包括 GC 事件的持续时间(duration)、开始时间(startTime)和结束时间(endTime),以及各个内存池在最近一次 GC 之前和之后的使用情况。 MemoryPoolNames:各个内存池的名称。 Name:垃圾收集器的名称。 ObjectName:由 JMX 规范定义的 MBean 的名字。 Valid:此收集器是否有效。本人只见过 "true" 的情况。这些信息对分析GC性能来说,不能得出什么结论。只有编写程序,获取GC相关的 JMX 信息来进行统计和分析。 下面看怎么执行远程实时监控。
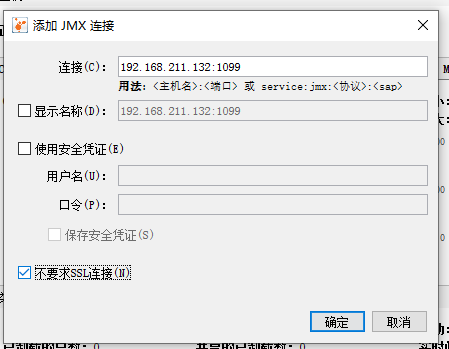
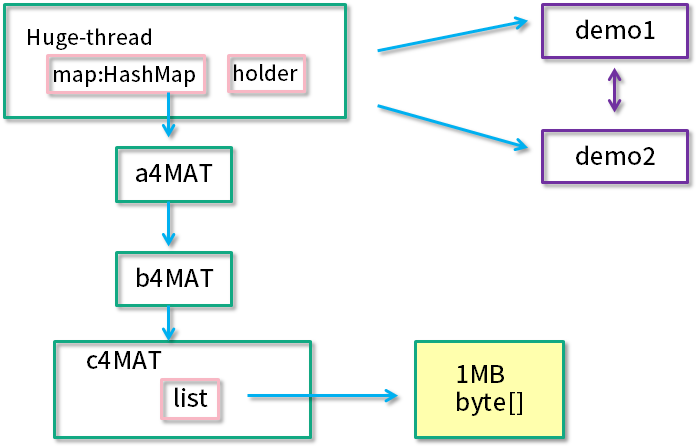
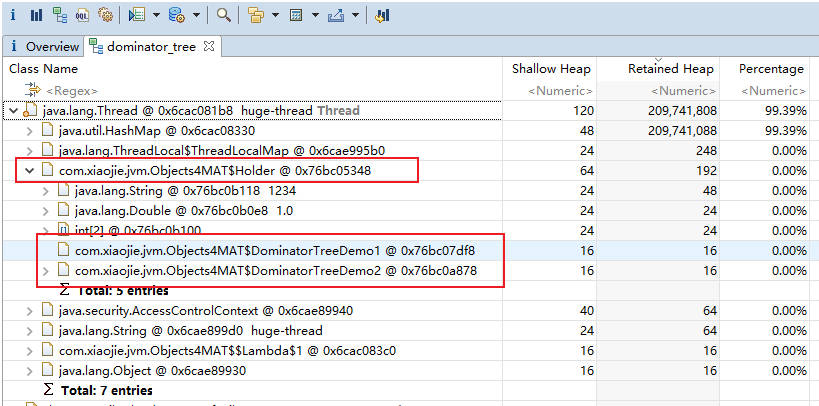
如上图所示,从文件菜单中,我们可以选择“添加远程主机”,以及“添加 JMX 连接”。 比如“添加 JMX 连接”,填上 IP 和端口号之后,勾选“不要求 SSL 连接”,点击“确定”按钮即可。 关于目标 JVM 怎么启动 JMX 支持,后续再讨论。 远程主机则需要 JStatD 的支持,后续再讨论。 MAT(Memory Analyzer Tool)一款功能强大的Java堆内存分析器。可以用来查找内存泄漏以及查看内存消耗情况。MAT是基于Eclipse开发的,不仅可以单独使用,还可以作为插件的形式嵌入在Eclipse中使用。是一款免费的性能分析工具,使用起来非常方便。 获取堆dump文件dump文件内容 MAT可以分析heap dump文件。在进行内存分析时,只要获得了反映当前设备内存映像的hprof文件,通过MAT打开就可以直观地看到当前的内存信息。 一般说来,这些内存信息包含: 所有的对象信息,包括对象实例、成员变量、存储于栈中的基本类型值和存储于堆中的其他对象的引用值。 所有的类信息,包括classloader、 类名称、父类、静态变量等 GCRoot到所有的这些对象的引用路径 线程信息,包括线程的调用栈及此线程的线程局部变量(TLS)说明: MAT 不是一个万能工具,它并不能处理所有类型的堆存储文件。但是比较主流的厂家和格式,例如 Sun, HP, SAP所采用的HPROF 二进制堆存储文件,以及IBM的PHD堆存储文件等都能被很好的解析。 最吸引人的还是能够快速为开发人员生成内存泄漏报表,方便定位问题和分析问题。虽然MAT有如此强大的功能,但是内存分析也没有简单到-键完成的程度,很多内存问题还是需要我们从MAT展现给我们的信息当中通过经验和直觉来判断才能发现。获取dump文件 通过前文介绍的jmap工具生成,可以生成任意-一个java进程的dump文件; 通过配置JVM参数生成。 选项"-XX:+HeapDumpOnOutOfMemoryError"或"-XX:+HeapDumpBeforeFullGC" 选项"-XX:HeapDumpPath"所代表的含义就是当程序出现0utofMemory时,将会在相应的目录下 生成一份dump文件。如果不指定选项“-XX:HeapDumpPath" 则在当前目录下生成dump文件。 对比:考虑到生产环境中几乎不可能在线对其进行分析,大都是采用离线分析,因此使用jmap+MAT工具是最常见的组合。 使用VisualVM可以导出堆dump文件 使用MAT既可以打开一个已有的堆快照,也可以通过MAT直接从活动Java程序中导出堆快照。 该功能将借助jps列出当前正在运行的Java 进程,以供选择并获取快照。 分析堆dump文件如果dump文件过大,可以修改 MAT 的配置参数。在 MAT 安装目录下,修改配置文件:MemoryAnalyzer.ini。默认的内存配置是 1024MB,修改如下部分: -vmargs -Xmx1024m根据 Dump 文件的大小,适当增加最大堆内存设置,要求是 4MB 的倍数,例如改为: -vmargs -Xmx4g demo演示新建demo: public class Objects4MAT { static class A4MAT { B4MAT b4MAT = new B4MAT(); } static class B4MAT { C4MAT c4MAT = new C4MAT(); } static class C4MAT { List list = new ArrayList(); } static class DominatorTreeDemo1 { DominatorTreeDemo2 dominatorTreeDemo2; public void setValue(DominatorTreeDemo2 value) { this.dominatorTreeDemo2 = value; } } static class DominatorTreeDemo2 { DominatorTreeDemo1 dominatorTreeDemo1; public void setValue(DominatorTreeDemo1 value) { this.dominatorTreeDemo1 = value; } } static class Holder { DominatorTreeDemo1 demo1 = new DominatorTreeDemo1(); DominatorTreeDemo2 demo2 = new DominatorTreeDemo2(); Holder() { demo1.setValue(demo2); demo2.setValue(demo1); } private boolean aBoolean = false; private char aChar = '\0'; private short aShort = 1; private int anInt = 1; private long aLong = 1L; private float aFloat = 1.0F; private double aDouble = 1.0D; private Double aDouble_2 = 1.0D; private int[] ints = new int[2]; private String string = "1234"; } Runnable runnable = () -> { Map map = new HashMap(); IntStream.range(0, 100).forEach(i -> { byte[] bytes = new byte[1024 * 1024]; String str = new String(bytes).replace('\0', (char) i); A4MAT a4MAT = new A4MAT(); a4MAT.b4MAT.c4MAT.list.add(str); map.put(i + "", a4MAT); }); Holder holder = new Holder(); try { //sleep forever , retain the memory Thread.sleep(Integer.MAX_VALUE); } catch (InterruptedException e) { e.printStackTrace(); } }; void startHugeThread() throws Exception { new Thread(runnable, "huge-thread").start(); } public static void main(String[] args) throws Exception { Objects4MAT objects4MAT = new Objects4MAT(); objects4MAT.startHugeThread(); } }代码创建了一个新的线程 "huge-thread",并建立了一个引用的层级关系,总的内存大约占用 100 MB。同时,demo1 和 demo2 展示了一个循环引用的关系。最后,使用 sleep 函数,让线程永久阻塞住,此时整个堆处于一个相对“静止”的状态。
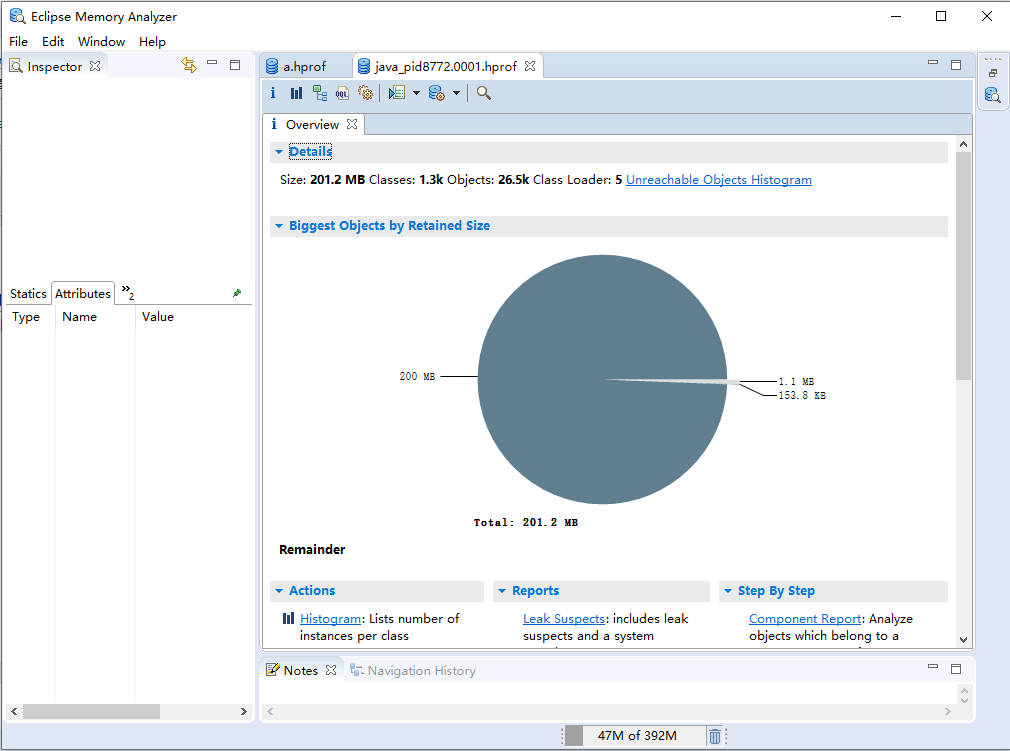
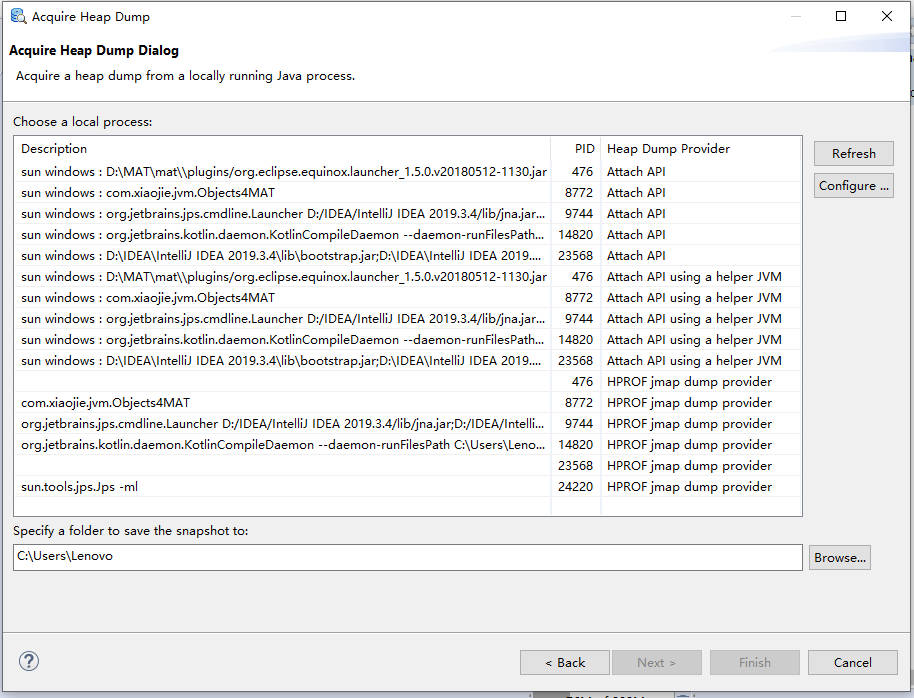
运行上面代码,并通过jps获取进程号,接着执行以下命令行获取dump文件。 jmap -dump:format=b,file=d:\test\a.hprof 25876通过MAT打开a.hprof文件。
这种方式对应的是获取dump文件的方法一。 也可以通过方法四获取:
选择指定进程生成dump文件 如果问题特别突出,则可以通过 Find Leaks 菜单快速找出问题。
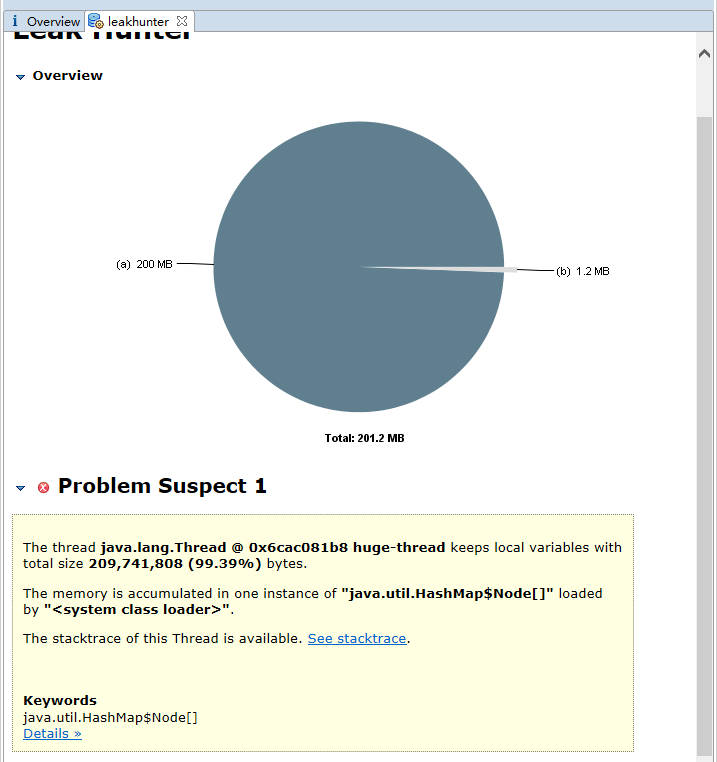
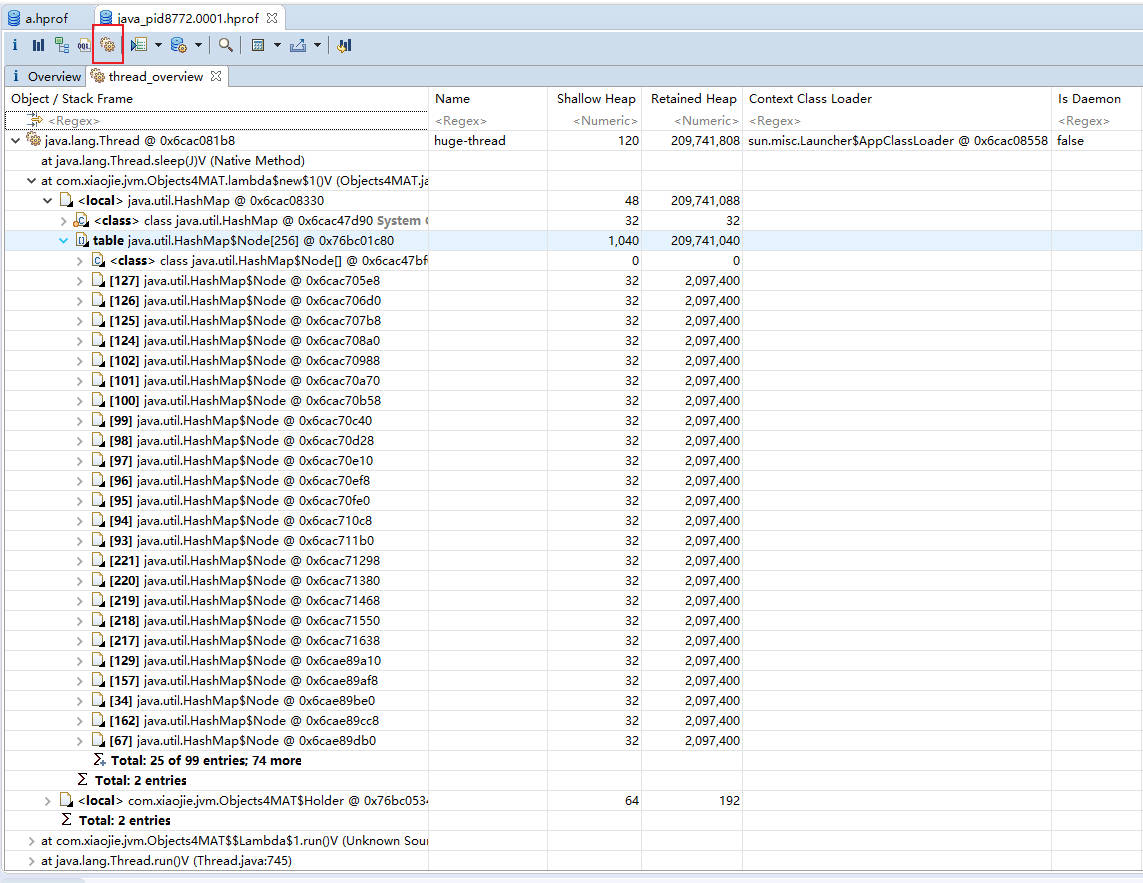
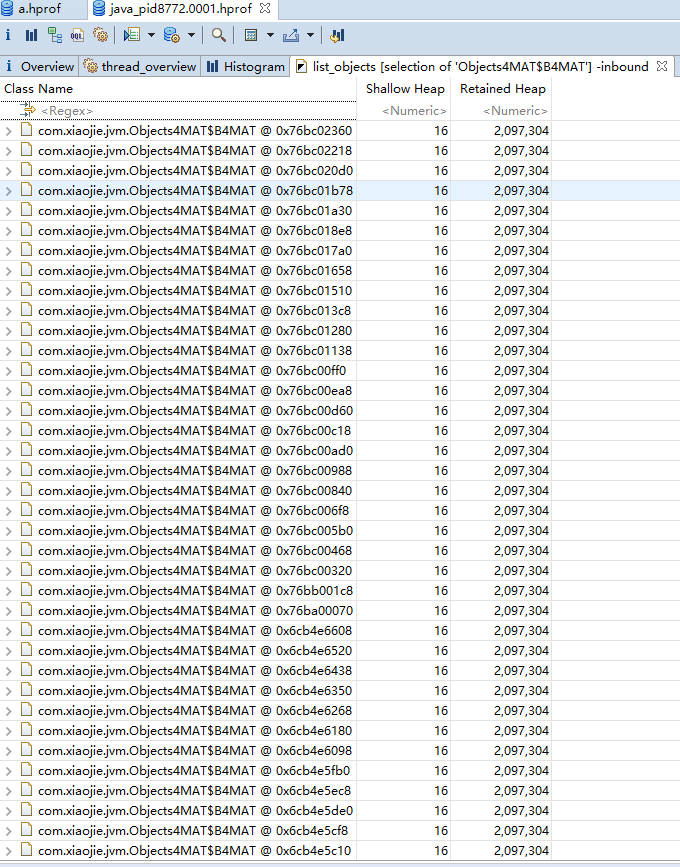
如下图所示,展示了名称叫做 huge-thread 的线程,持有了超过 99% 的对象,数据被一个 HashMap 所持有。
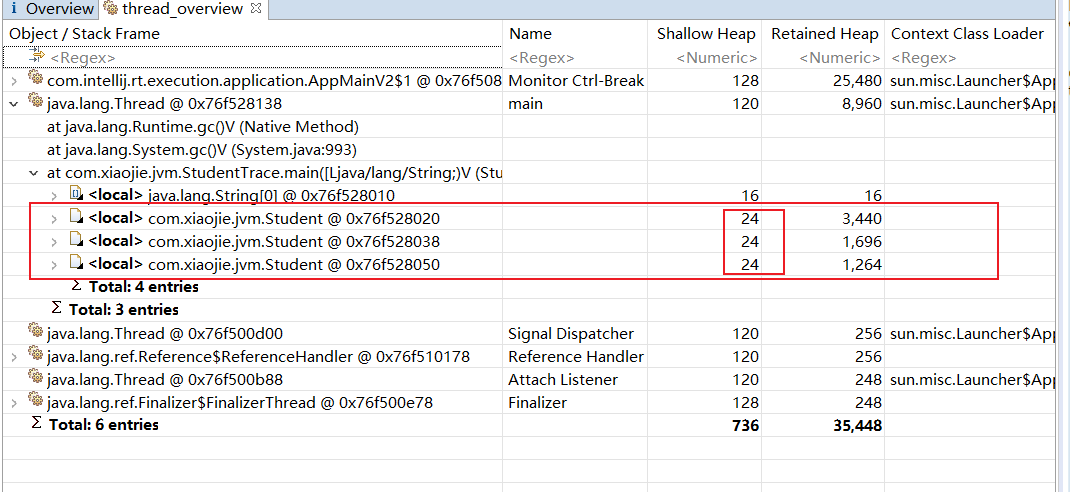
展示了各个类的实例数目以及这些实例的Shallow heap或者Retained heap的总和,并支持基于实例数目或 Retained heap 的排序方式(默认为 Shallow heap)。此外,还可以将直方图中的类按照超类、类加载器或者包名分组。 2.thread overview:查看系统中的Java线程,查看局部变量的信息 如图展示了线程内对象的引用关系,以及方法调用关系,相对比 jstack 获取的栈 dump,我们能够更加清晰地看到内存中具体的数据。而且,我们找到了 huge-thread,依次展开找到 holder 对象,可以看到循环依赖已经陷入了无限循环的状态。这在查看一些 Java 对象的时候,经常发生。
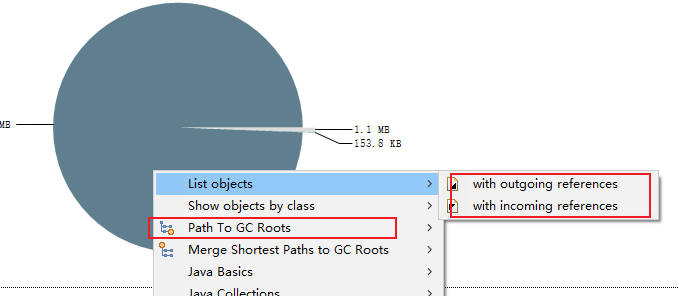
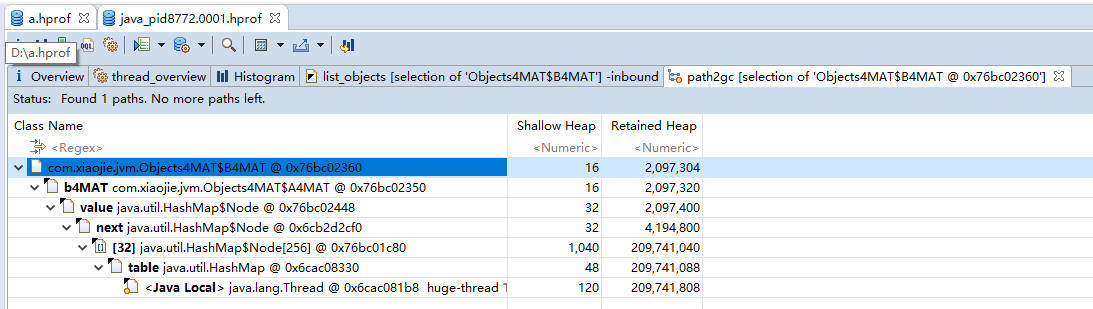
3.获得对象相互引用的关系 with outgoing references(对象的引出) 和 with incoming reference(对象的引入) path to GC Roots 显示和 GC Roots 之间的路径。
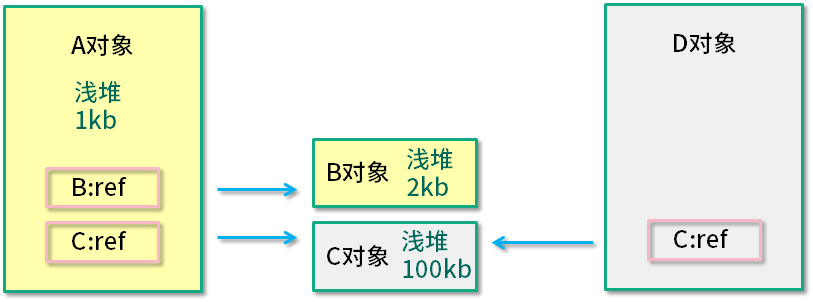
4.浅堆和深堆 MAT 计算对象占据内存的两种方式。shallow heap和retained heap。 浅堆(shallow heap)是指一个对象所消耗的内存,包括对象自身的内存占用,以及“为了引用”其他对象所占用的内存。。 深堆(Retained Heap)是指对象的保留集中所有的对象的浅堆大小之和。 注意:浅堆指对象本身占有的内存,不包括其内部引用对象的大小,一个对象的深堆指只能通过该对象访问到的(直接或间接)所有对象的浅堆之和,即对象被回收,可以释放的总内存,包括对象自身所占据的内存,以及仅能够通过该对象引用到的其他对象所占据的内存,这些其他对象集合,叫做保留集(Retained Set)。
如上图所示,A 对象浅堆大小 1 KB,B 对象 2 KB,C 对象 100 KB。A 对象同时引用了 B 对象和 C 对象,但由于 C 对象也被 D 引用,所以 A 对象的深堆大小为 3 KB(1 KB + 2 KB)。 A 对象大小(1 KB + 2 KB + 100 KB)> A 对象深堆 > A 对象浅堆。 一个对象占用的内存大小可以分为下面三部分: 对象头 对象成员占用内存 内存对齐对象头主要分为三部分: 运行时元数据:这个主要保存了对象的哈希值、GC分代年龄、锁信息等等占用8个字节。 类型指针:指向方法区该类的Klass 数组长度:如果当前对象是数组类型的,那么还会拥有4字节的数组长度 那么对象头的大小=8 + 指针大小 + [4:如果是数组的话] 在内存小于32G的情况下,我们默认采用了压缩指针,指针长度为32位。我们也可以禁用压缩指针,那么指针长度将为64位。一般我们个人开发的情况下,内存基本都小于32G,所以我们可以认为普通对象的对象头大小为12字节,数组为16字节。 在32位系统中,一个对象引用会占用4个字节,一个int类型会占用4个字节,long类型会占用8个字节,每个对象头会占用12或16个字节。根据堆快照格式不同,对象的大小可能会向8字节进行对齐。对象头除去类型指针的大小为8字节,然后类型指针看是否启用了引用压缩,如果启用了,对象头总共就是12字节,否则就是16字节。 以String为例:1个int值共占4个字节,对象引用占用4个字节,对象头12个字节,合计20个字节。向8字节对齐,故占24字节。这24 字节为String对象的浅堆大小。它与String的value实际取值无关,无论字符串长度如何,浅堆大小始终是24字节。
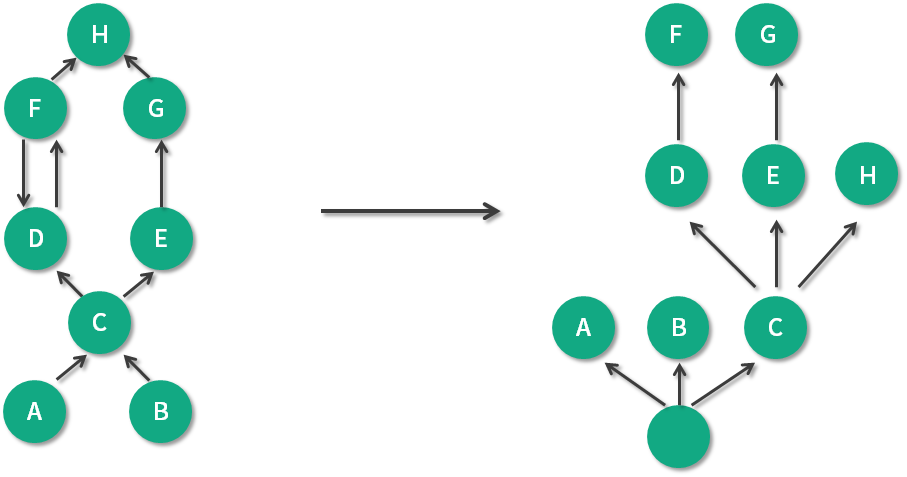
保留集(Retained Set): 对象A的保留集指当对象A被垃圾回收后,可以被释放的所有的对象集合(包括对象A本身),即对象A的保留集可以被认为是只能通过对象A被直接或间接访问到的所有对象的集合。通俗地说,就是指仅被对象A所持有的的对象的集合。 MAT 包括了两个比较重要的视图,分别是直方图(histogram)和支配树(dominator tree)。 支配树(Dominator Tree)MAT提供了一个称为支配树的对象图。支配树视图对数据进行了归类,体现了对象实例间的支配关系。在对象引用图中,所有指向对象B的路径都经过对象A ,则认为对象A支配了对象B。如果对象A时离对象B最近的一个支配对象,则认为对象A为对象B的直接支配者,支配树是基于对象间的引用图所建立的,它有以下基本性质: 对象A的子树(所有被对象A支配的对象集合)表示对象A的保留集(retained set),即深堆。 如果对象A支配对象B,那么对象A的直接支配者也支配对象B。 支配树的边与对象引用图的边不直接对应。如下图所示:左图表示对象引用图,右图表示左图所对应的支配树。对象A和B由根对象直接支配,由于在到对象C的路径中,可以经过A,也可以经过B,因此对象C的直接支配者也是根对象。对象F与对象D相互引用,因为到对象F的所有路径必然经过对象D,因此,对象D时对象F的直接支配者。而到对象D的所有路径中,必然经过对象C,即使是从对象F到对象D的引用,从根节点触发,也是经过对象C的,所以,对象D的直接支配者为对象C。
同理,对象E支配对象G,支配关系是可传递的,因为 C 支配 E,所以 C 也支配 G。到达对象H可以通过对象D,也可以通过对象E,因此对象D和E都不能支配对象H,而经过对象C既可以到达D也可以到达E,因此对象C为对象H的直接支配者。 MAT支配树视图
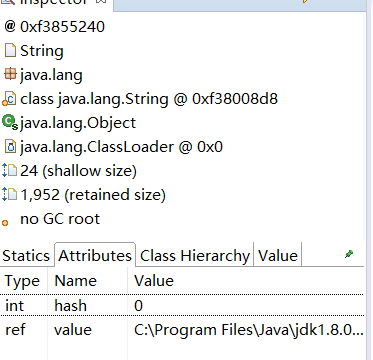
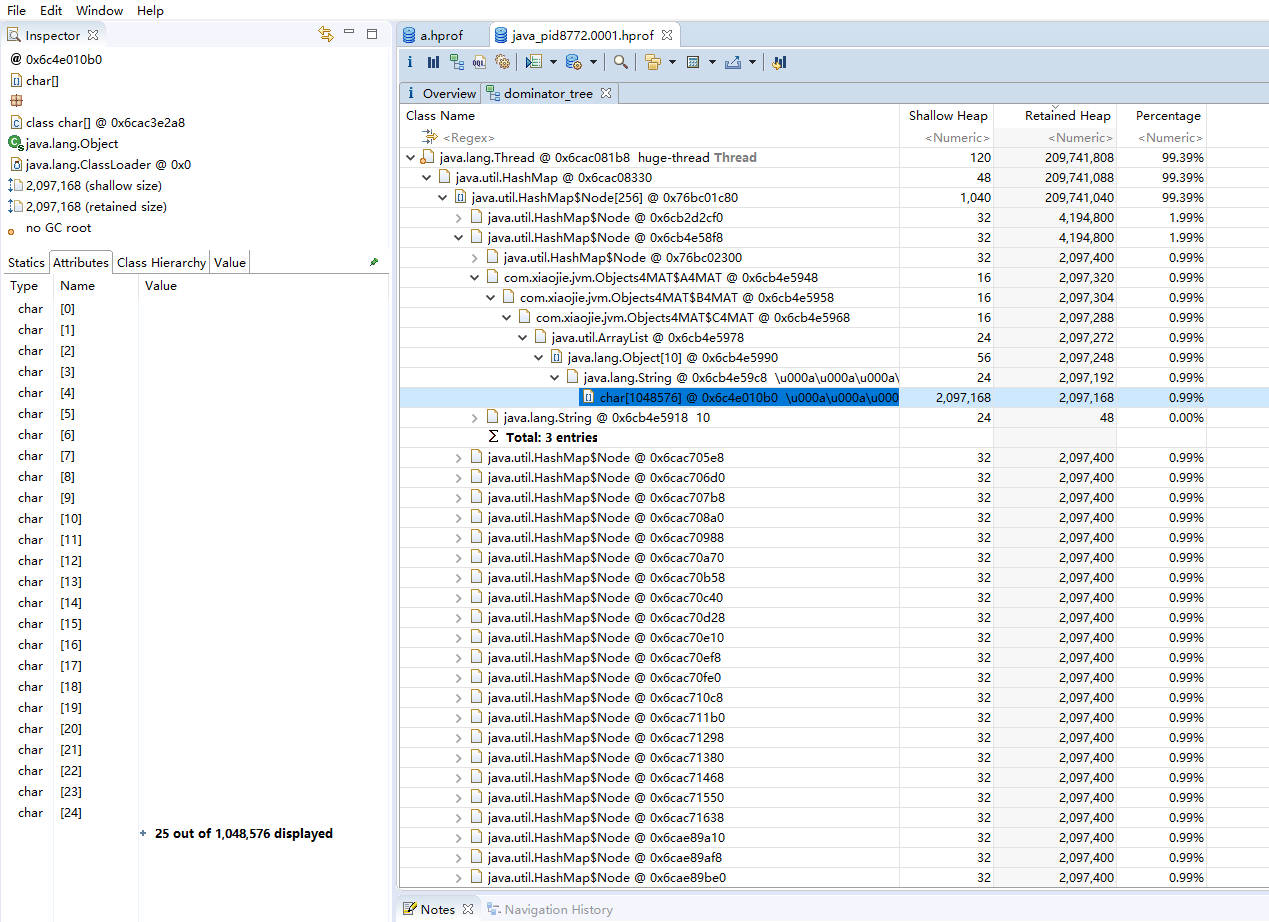
如图,我们通常会根据“深堆”进行倒序排序,可以很容易的看到占用内存比较高的几个对象,点击前面的箭头,即可一层层展开支配关系。 图中显示的是其中的 2 MB 数据,从左侧的 inspector 视图,可以看到这 2 MB 的 byte 数组具体内容。 从支配树视图同样能够找到我们创建的两个循环依赖,但它们并没有显示这个过程。
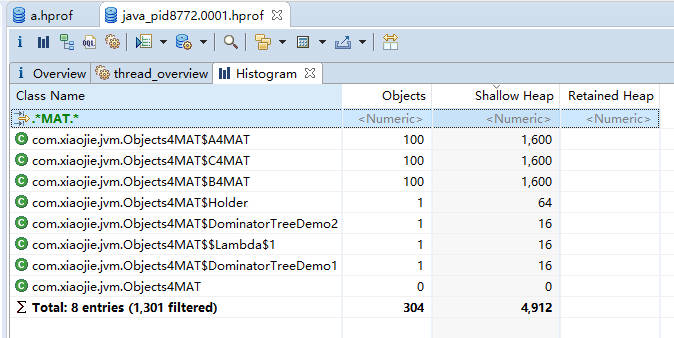
看一下柱状图视图,可以看到除了对象的大小,还有类的实例个数。结合 MAT 提供的不同显示方式,往往能够直接定位问题。也可以通过正则过滤一些信息,我们在这里输入 MAT,过滤猜测的、可能出现问题的类,可以看到,创建的这些自定义对象,不多不少正好一百个。
右键点击类,然后选择 incoming,这会列出所有的引用关系。
再次选择某个引用关系,然后选择菜单“Path To GC Roots”,即可显示到 GC Roots 的全路径。通常在排查内存泄漏的时候,会选择排除虚弱软等引用。使用这种方式,即可在引用之间进行跳转,方便的找到所需要的信息。
再介绍一个比较高级的功能。 我们对于堆的快照,其实是一个“瞬时态”,有时候仅仅分析这个瞬时状态,并不一定能确定问题,这就需要对两个或者多个快照进行对比,来确定一个增长趋势。
可以将代码中的 100 改成 10 或其他数字,再次 dump 一份快照进行比较。 OQLMAT 支持一种类似于 SQL 的查询语言 OQL(Object Query Language),这个查询语言 VisualVM 工具也支持。
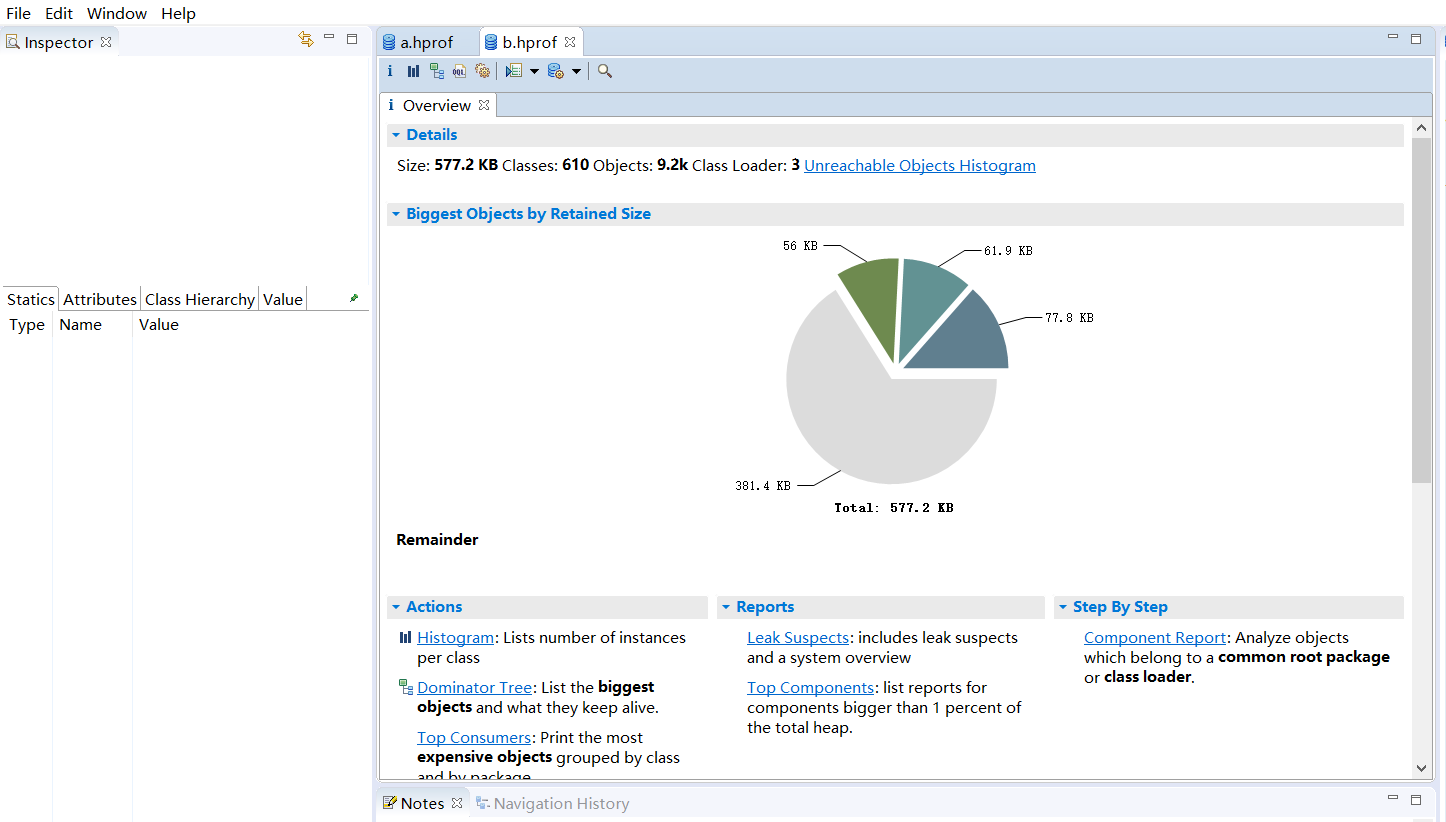
以下是几个例子 查询 A4MAT 对象: SELECT * FROM com.xiaojie.jvm.Objects4MAT$A4MAT正则查询 MAT 结尾的对象: SELECT * FROM ".*MAT"查询包含 java 字样的所有字符串: SELECT * FROM java.lang.String s WHERE toString(s) LIKE ".*java.*"查找所有深堆大小大于 1 万的对象: SELECT * FROM INSTANCEOF java.lang.Object o WHERE o.@retainedHeapSize>10000分析对象大小demo演示 代码 public class StudentTrace { static List webPages = new ArrayList(); public static void createWebPages() { for (int i = 0; i < 100; i++) { WebPage webPage = new WebPage(); webPage.setUrl("www." + Integer.toString(i) + ".com"); webPage.setContent(Integer.toString(i)); webPages.add(webPage); } } public static void main(String[] args) { createWebPages(); Student student3 = new Student(3, "张三"); Student student5 = new Student(5, "李四"); Student student7 = new Student(7, "王五"); for (int i = 0; i < webPages.size(); i++) { if (i % student3.getId() == 0) { student3.visit(webPages.get(i)); } if (i % student5.getId() == 0) { student5.visit(webPages.get(i)); } if (i % student7.getId() == 0) { student7.visit(webPages.get(i)); } } webPages.clear(); System.gc(); } } class Student { private int id; private String name; private List history = new ArrayList(); public Student(int id, String name) { this.id = id; this.name = name; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public List getHistory() { return history; } public void setHistory(List history) { this.history = history; } public void visit(WebPage webPage) { if (webPage != null) { history.add(webPage); } } } class WebPage { private String url; private String content; public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } public String getContent() { return content; } public void setContent(String content) { this.content = content; } }vm options配置: -XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=d:\tmp\b.hprof利用MAT打开b.hprof
三个对象的浅堆大小为24字节,因为两个引用占用8字节,一个int占用4字节,对象头12字节,总共24字节。
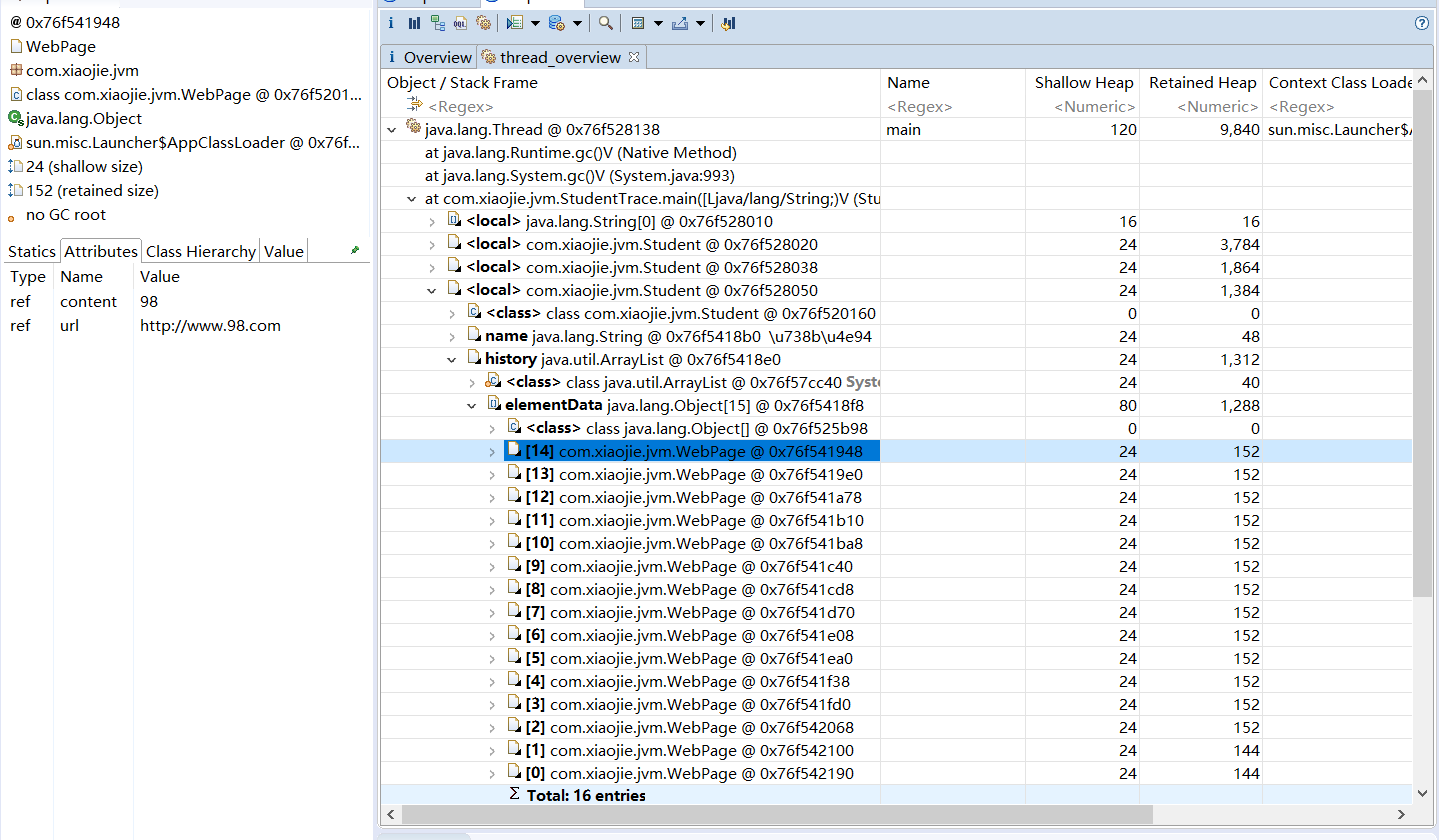
每个student对象的网页集合字段中的每个对象所占用的深堆大小为152和144。 1.为什么有152字节和144字节:因为我们的URL和content存在两种情况 URL:"http://www.7.com"、content:"7" URL:"http://www.14.com"、content:"14" 第一种URL长度为16,底层的char数组的占用空间为(【】方括号里面整个都属于对象头,分开写方便大家理解)【普通对象头(12) + 数组长度(4)】 + 16个字符(32) = 48字节,符合8字节对齐同理content 占用 【普通对象头(12) +数组长度(4)】+ 一个字符(2) = 18字节,八字节对齐=24字节 第二种URL长度为17,底层的插入数组的占用空间为【普通对象头(12) + 数组长度(4)】 + 17个字符(34) = 50字节,不符合8字节对齐,对齐为56同理content 占用 【普通对象头(12) +数组长度(4)】+ 两个字符(4) = 20字节,八字节对齐=24字节 所以第一种总字节为48 + 24 = 72,第二种总字节为56 + 24 = 80。因此第二种比第一种多了8字节,所以是152和144。 (为什么总大小是152而不是72是因为我们只计算了String底层的char数组的区别没有计算各变量本身的浅堆,因为结构都想相同,所以差别就差在内容的占用上)2.为什么最终结果是1288首先ElementData数组本身的浅堆大小为 【普通对象头(12) + 数组长度(4)】 + 数组内容【15个Obejct引用=16*4】 = 76,八字节对齐=80字节15个Object分为13个152字节+2个144字节,总大小为=2264字节7号和其他student重复的有0、21、42、63、84、35、70总计6个152和1一个144所以2264 - 6 * 152 - 144 = 1208字节所以ElementData本身的浅堆80 + 仅能通过它到达的浅堆1208 = 1288
JProfiler数据采集方式分为两种:Sampling(样本采集)和 Instrumentation(重构模式) Instrumentation:这是JProfiler全功能模式。在class加载之前,JProfiler吧相关功能代码写入到需要分析的class的bytecode中,对正在运行的JVM有一定影响。 优点:功能强大。在此设置中,调用堆栈信息时准确的。 缺点:若要分析的class较多,则对应用的性能影响较大,CPU开销可能很高(取决于Filter的控制)。因此使用此模式一般配合Filter使用,只对特定的类或包进行分析。 Sampling:类似样本统计,每个一定时间(5ms)将每个线程栈中的信息统计出来。 优点:对CPU的开销非常低,对应用影响小(即使不配置任何Filter) 缺点:一些数据、特性不能提供(例如:方法的调用次数、执行时间)注意:JProfiler本身没有指出数据的采集类型,这里的采集类型是针对方法调用的采集类型。因为JProfiler的绝大多数核心功能都依赖方法调用采集的数据,所以可以直接认为是JProfiler的数据采集类型。 Telemetries(遥感监测)
Live Memory(内存视图)
Live memory 内存剖析:class、class instance的相关信息。例如对象的个数,大小,对象创建的方法执行栈,对象创建的热点。 ALL Objects(所有对象) :显示所有加载的类的列表和在堆上分配的实例数。 Record Objects(记录对象):查看特定时间段对象的分配,并记录分配的调用堆栈。 Allocation Call Tree(分配访问树):显示一颗请求树或者方法、类、包或对已选择类由带注释的分配信息的J2EE组件。 Allocation Hot Spots(分配热点):显示一个列表,包括方法、类、包或分配已选类的J2EE组件。你可以标注当前值并且显示差异值。对于每个热点都可以显示它的跟踪记录树。 Class Tracker(类追踪器):类追踪视图可以包含任意数量的图表,显示特定的类型和包的实例和时间。注意: All Objects后面的Size大小是浅堆大小 Record Objects在判断内存泄露的时候使用,可以通过观察Telemetries中的Memory,如果里面出现垃圾回收之后的内存占用逐步提高,这就有可能出现内存泄露问题,所以可以使用Record Objects查看,但是该分析默认不开启,毕竟占用CPU性能太多。 堆遍历如果通过内存视图 Live Memory已经分析出哪个类的对象不能进行垃圾回收,并且有可能导致内存溢出,如果想进一步分析,我们可以在该对象上点击右键,选择Show Selection In Heap Walker,如下图:
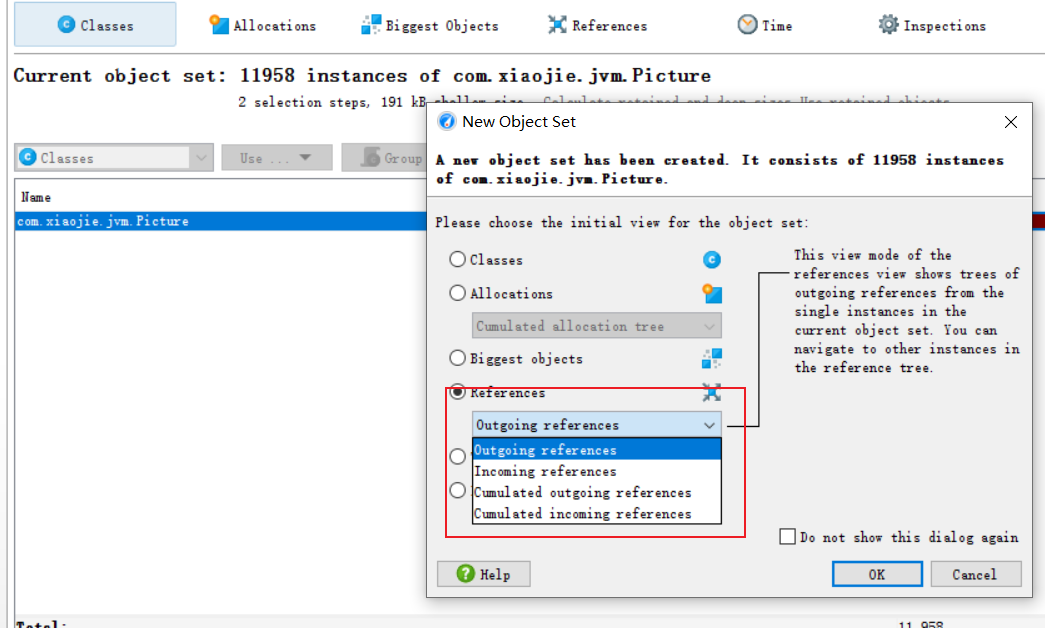
之后进行溯源,操作如下: 在Picture上双击左键,或者单击右键之后选择 Select Object,之后选择reference,里面我们用到outgoing reference,这个就是找我们会用到谁,而incoming reference 是找谁用了我们。
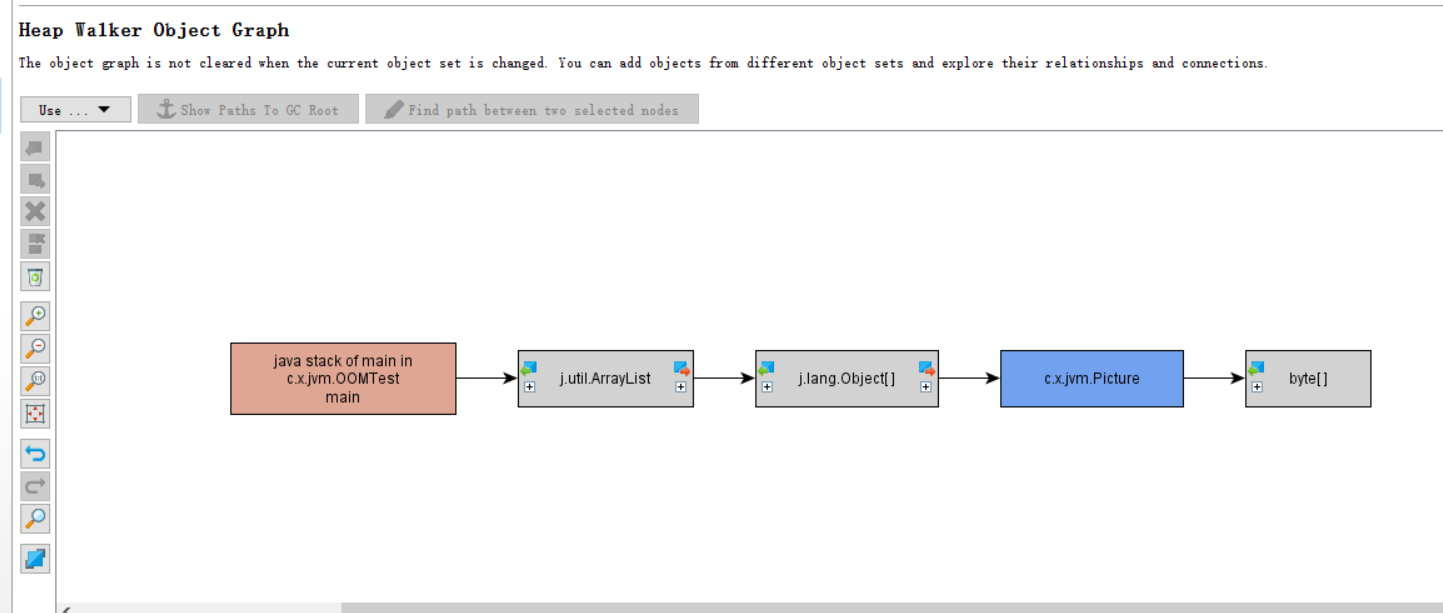
查看结果,并根据结果去看对应的图表:
也可以点击show inGraph 查看图表 以下是图表的展示情况:
方法统计
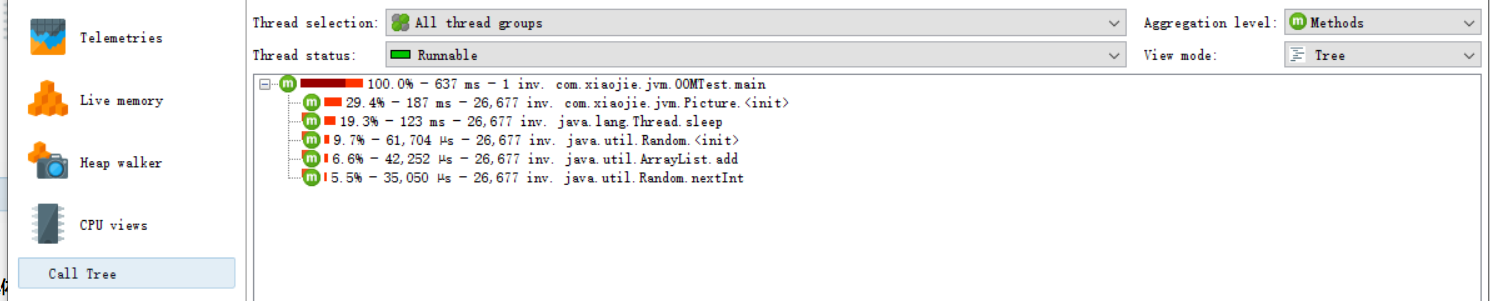
具体分析
可以用来查看方法直接的调用情况,上面的100.0%代表该方法会100.0%调用下面方法,637ms代表调用时间花费637ms,1inv代表调用下面方法1次。 线程视图 threadsJProfiler通过对线程历史的监控判断其运行状态,并监控是否有线程阻塞产生,还能将一个线程所管理的方法以树状形式呈现。对线程剖析。 线程历史 Thread History 显示一个与线程活动和线程状态在一起的活动时间表。 线程监控 Thread Monitor 显示一个列表,包括所有的活动线程以及它们目前的活动状况。 线程转储 Thread Dumps 显示所有线程的堆栈跟踪。 线程分析主要关心三个方面: web容器的线程最大数。比如:Tomcat的线程容量应该略大于最大并发数 线程阻塞 线程死锁 监视器&锁 Monitors&locks ArthasArthas(阿尔萨斯)是阿里巴巴推出了一款开源的 Java 诊断工具,深受开发者喜爱。为什么这么说呢? Arthas 支持 JDK 6 以及更高版本的 JDK; 支持 Linux/Mac/Winodws 操作系统; 采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,方便进行问题的定位和诊断; 支持 WebConsole,在某些复杂的情况下,打通 HTTP 路由就可以访问。当我们遇到以下类似问题而束手无策时,可以使用 Arthas 来帮助我们解决: 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception? 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了? 遇到问题无法在线上 Debug,难道只能通过加日志再重新发布吗? 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现! 是否有一个全局视角来查看系统的运行状况? 有什么办法可以监控到 JVM 的实时运行状态? 怎么快速定位应用的热点,生成火焰图?官方文档:https://arthas.aliyun.com/doc/ 安装安装方式一:可以直接在linux上通过命令下载 # 准备目录 mkdir -p /usr/local/tools/arthas cd /usr/local/tools/arthas # 执行安装脚本 curl -L https://alibaba.github.io/arthas/install.sh | sh ······
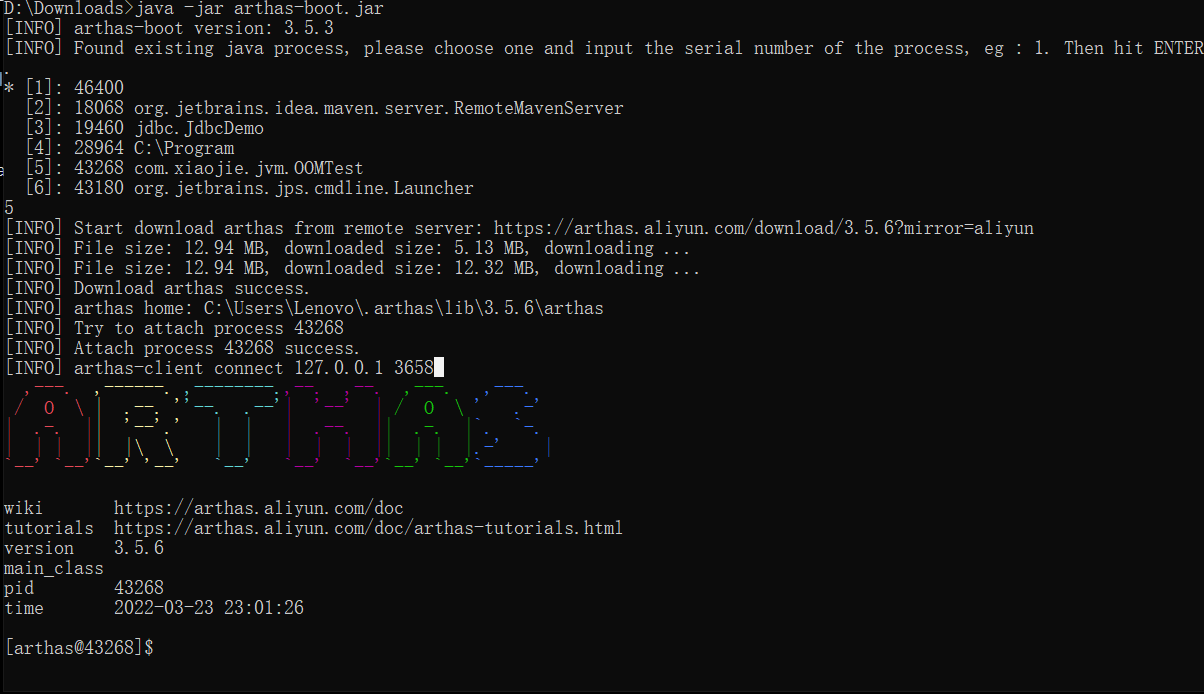
可以在官方Github上进行下载,也可以通过Gitee下载 github:wget https://alibaba.github.io/arthas/arthas-boot.jar gitee:wget https://arthas.gitee.io/arthas-boot.jar安装方式二:本地访问 https://alibaba.github.io/arthas/arthas-boot.jar,下载成功后,上传到Linux服务器。 启动方式一:直接使用 java -jar arthas-boot.jar 启动
选择进程(输入[]内编号,回车)
方式二:运行时选择Java进程PID : java -jar arthas-boot.jar [PID] 除了在命令行查看外,也可以通过web页面访问,http://127.0.0.1:3658/,操作模式和控制台一样。 指令help:查看命令帮助信息,可以查看当前arthas版本支持的指令,或者查看具体指令的使用说明。 cat:打印文件内容,和linux里的cat命令类似。 echo:打印参数,和linux里的echo命令类似。 jvm:查看当前JVM信息。 dashboard:当前系统的实时数据面板。 JMC 图形界面客户端Java Mission Control(JMC)是 Java 虚拟机平台上的性能监控工具。它包含一个 GUI 客户端,以及众多用来收集 Java 虚拟机性能数据的插件,如 JMX Console(能够访问用来存放虚拟机各个子系统运行数据的MXBeans),以及虚拟机内置的高效 profiling 工具 Java Flight Recorder(JFR)。 JMC 和 JVisualVM 功能类似,因为 JMC 的前身是 JRMC,JRMC 是 BEA 公司的 JRockit JDK 自带的分析工具,被 Oracle 收购以后,整合成了 JMC 工具。Oracle 试图用 JMC 来取代 JVisualVM,在商业环境使用 JFR 需要付费获取授权。 在命令行输入 jmc 后,启动后的界面如下:
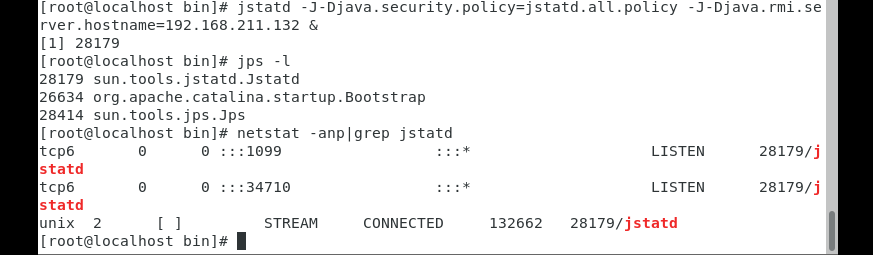
点击相关的按钮或者菜单即可启用对应的功能,JMC 提供的功能和 JVisualVM 差不多。 飞行记录器除了 JConsole 和 JVisualVM 的常见功能(包括 JMX 和插件)以外,JMC 最大的亮点是飞行记录器。 这里需要注意的一点是,JMC可以用于java7以上的所有版本,而飞行记录器,只能用于oracle jre,且是java7及以上的版本,因为要使用飞行记录器,需要开启jvm的商业特性,也就是在启动的时候加上参数:"-XX:+UnlockCommercialFeatures","-XX:+FlightRecorder"。如果是open jdk,尝试加这两个参数的时候,会直接导致虚拟机终止,无法正常启动。所以,飞行记录器只能局限在oracle jdk里面使用。这里就不展示了,自行网上研究下。 JStatD 服务端工具JStatD 是一款强大的服务端支持工具,用于配合远程监控jvm的创建和结束,并且提供接口让监控工具可以远程连接到本机的jvm 。JStatD 位于 $JAVA_HOME/bin目录下,具体使用方法如下: 1,启动RMI服务在需要被监控的服务器上面,通过jstatd来启动RMI服务。但因为涉及暴露一些服务器信息,所以需要配置安全策略文件。 配置java安全访问,在jdk的bin目录下创建文件jstatd.all.policy 写入下面的安全配置 grant codebase "file:${java.home}/../lib/tools.jar" { permission java.security.AllPermission; };然后在进入jstatd.all.policy所在目录下,通过如下的命令启动RMI服务: jstatd -J-Djava.security.policy=jstatd.all.policy -J-Djava.rmi.server.hostname=192.168.211.132 &其中 192.168.211.132 是公网 IP,如果没有公网,那么就是内网 IP。 验证是否启动成功 服务器:
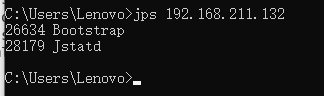
客户端:
若出现以上文案,则启动成功 2.然后使用 JVisualVM 或者 JConsole 连接远程服务器。其中 IP 为 192.168.211.132,端口号是默认的 1099。当然,端口号可以通过参数自定义。 说明:客户端与服务器的 JVM 大版本号必须一致或者兼容。 CPU 图形没有显示,原因是 JStatD 不监控单个实例的 CPU。可以在对应 Java 应用的启动参数中增加 JMX 监控配置。 BTrace 诊断分析工具BTrace 是基于 Java 语言的一款动态追踪工具,可用于辅助问题诊断和分析。BTrace 基于 ASM、Java Attach API、Instruments 开发,提供很多注解。通过这些注解,可以通过 Java 代码来编写 BTrace 脚本进行只读监控,而无需深入了解 ASM 对字节码的操纵。 BTrace 项目地址:https://github.com/btraceio/btrace/ 下面我们来实际操作一下。 BTrace 下载找到 Release 页面,找到最新的压缩包下载: btrace-bin.tar.gz btrace-bin.zip下载完成后解压即可使用:
可以看到,bin 目录下是可执行文件,samples 目录下是脚本示例。 示例程序我们先编写一个有入参有返回值的方法,示例如下: public class RandomSample { public static void main(String[] args) throws Exception { // int count = 10000; int seed = 0; for (int i = 0; i < count; i++) { seed = randomHash(seed); TimeUnit.SECONDS.sleep(2); } } public static int randomHash(Integer seed) { String uuid = UUID.randomUUID().toString(); int hashCode = uuid.hashCode(); System.out.println("prev.seed=" + seed); return hashCode; } }运行程序,可以看到控制台每隔一段时间就有一些输出: prev.seed=0 prev.seed=-1498044692 prev.seed=-266090177 prev.seed=-1269488296 prev.seed=-354526660 prev.seed=1226660026 prev.seed=662501151 prev.seed=-917015412 prev.seed=743781789 prev.seed=840693320 prev.seed=1161830176 prev.seed=-517897036 prev.seed=150130649 prev.seed=-1379375222 prev.seed=-439945231 prev.seed=-302528351BTrace 提供了命令行工具,但使用起不如在 JVisualVM 中方便,下面通过 JVisualVM 中集成 BTrace 插件进行简单的演示。 JVisualVM 环境中使用 BTrace安装 JVisualVM 插件的操作,我们在介绍JVisualVM的时候讲过。在安装 JVisualVM 的插件时,有一款插件叫做“BTrace Workbench”。安装这款插件之后,在对应的 JVM 实例上点右键,就可以进入 BTrace 的操作界面。
打开后默认的界面如下:
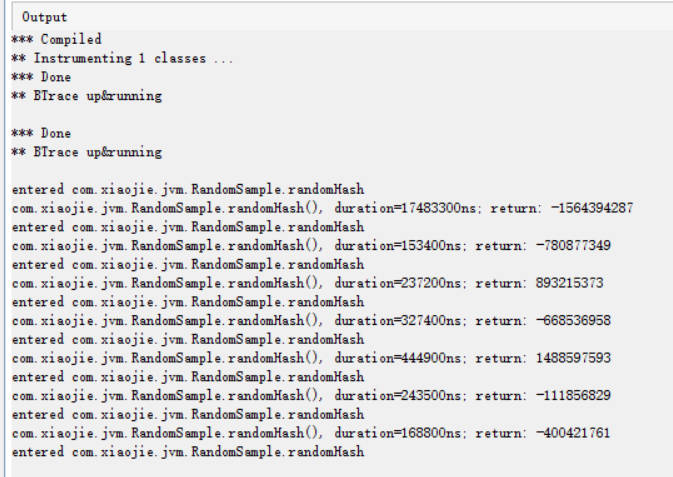
可以看到这是一个 Java 文件的样子。然后我们参考官方文档,加一些脚本进去。 BTrace 脚本示例我们下载的 BTrace 项目中,samples 目录下有一些脚本示例。 参照这些示例,编写一个简单的 BTrace 脚本: import com.sun.btrace.annotations.*; import static com.sun.btrace.BTraceUtils.*; @BTrace public class TracingScript { @OnMethod( clazz = "/com.xiaojie.jvm.*/", method = "/.*/" ) // 方法进入时 public static void simple( @ProbeClassName String probeClass, @ProbeMethodName String probeMethod) { print("entered " + probeClass); println("." + probeMethod); } @OnMethod(clazz = "com.xiaojie.jvm.RandomSample", method = "randomHash", location = @Location(Kind.RETURN) ) // 方法返回时 public static void onMethodReturn( @ProbeClassName String probeClass, @ProbeMethodName String probeMethod, @Duration long duration, @Return int returnValue) { print(probeClass + "." + probeMethod); print(Strings.strcat("(), duration=", duration+"ns;")); println(Strings.strcat(" return: ", ""+returnValue)); } }点击 start 执行 执行结果可以看到,输出了简单的执行结果:
和示例程序的控制台输出比对,结果一致。 更多工具 OOM KillerLinux 系统上的 OOM Killer(Out Of Memory killer,OOM 终结者)。假如物理内存不足,Linux 会找出“一头比较壮的进程”来杀掉。 OOM Killer 参数调优Java 的堆内存溢出(OOM),是指堆内存用满了,GC 没法回收导致分配不了新的对象。 而操作系统的内存溢出(OOM),则是指计算机所有的内存(物理内存 + 交换空间),都被使用满了。 这种情况下,默认配置会导致系统报警,并停止正常运行。当然,将 /proc/sys/vm/panic_on_oom 参数设置为 0 之后,则系统内核会在发生内存溢出时,自动调用 OOM Killer 功能,来杀掉最壮实的那头进程(Rogue Process,流氓进程),这样系统也许就可以继续运行了。 以下参数可以基于单个进程进行设置,以手工控制哪些进程可以被 OOM Killer 终结。这些参数位于 proc 文件系统中的 /proc/pid/ 目录下,其中 pid 是指进程的 ID。 oomadj:正常范围是 -16 到 15,用于计算一个进程的 OOM 评分(oomscore)。这个分值越高,该进程越有可能被 OOM Killer 给干掉。如果设置为 -17,则禁止 OOM Killer 杀死该进程。 proc 文件系统是虚拟文件系统,某个进程被杀掉,则 /proc/pid/ 目录也就被销毁了。 OOM Killer 参数调整示例例如进程的 pid=12884,root 用户执行: $ cat /proc/12884/oom_adj 0 # 查看最终得分 $ cat /proc/12884/oom_score 161 $ cat /proc/12884/oom_score_adj 0 # 修改分值 ... $ echo -17 > /proc/12884/oom_adj $ cat /proc/12884/oom_adj -17 $ cat /proc/12884/oom_score 0 # 查看分值修正值 $ cat /proc/12884/oom_score_adj -1000 # 修改分值 $ echo 15 > /proc/12884/oom_adj $ cat /proc/12884/oom_adj 15 $ cat /proc/12884/oom_score 1160 $ cat /proc/12884/oom_score_adj 1000这样配置之后,就允许某个占用了最多资源的进程,在操作系统内存不足时,也不会杀掉他,而是先去杀别的进程。 抽样分析器(Profilers)相对于前面的工具,分析器只关心 GC 中的一部分领域,这里只简单介绍分析器相关的 GC 功能。 需要注意:不要认为分析器适用于所有的场景。分析器有时确实作用很大,比如检测代码中的 CPU 热点时,但某些情况使用分析器不一定是个好方案。 对 GC 调优来说也是一样的。要检测是否因为 GC 而引起延迟或吞吐量问题时,不需要使用分析器。前面提到的工具(jstat 或原生/可视化 GC 日志)就能更好更快地检测出是否存在 GC 问题.。特别是从生产环境中收集性能数据时,最好不要使用分析器,因为性能开销非常大,对正在运行的生产系统会有影响。 如果确实需要对 GC 进行优化,那么分析器就可以派上用场了,可以对 Object 的创建信息一目了然。换个角度看,如果 GC 暂停的原因不在某个内存池中,那就只会是因为创建对象太多了。所有分析器都能够跟踪对象分配(via allocation profiling),根据内存分配的轨迹,让你知道 实际驻留在内存中的是哪些对象。 分配分析能定位到在哪个地方创建了大量的对象。使用分析器辅助进行 GC 调优的好处是,能确定哪种类型的对象最占用内存,以及哪些线程创建了最多的对象。 下面我们通过实例介绍 3 种分配分析器:hprof、JVisualVM 和 AProf。实际上还有很多分析器可供选择,有商业产品,也有免费工具,但其功能和应用基本上都是类似的。 hprofhprof 分析器内置于 JDK 之中。在各种环境下都可以使用,一般优先使用这款工具。 性能分析工具——HPROF 简介:https://github.com/cncounter/translation/blob/master/tiemao2017/20hprof/20_hprof.md HPROF 参考文档:https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr008.html 要让 hprof 和程序一起运行,需要修改启动脚本,类似这样: java -agentlib:hprof=heap=sites com.yourcompany.YourApplication在程序退出时,会将分配信息 dump(转储)到工作目录下的 java.hprof.txt 文件中。使用文本编辑器打开,并搜索“SITES BEGIN”关键字,可以看到:
JDK 还自带了其他工具,比如 jsadebugd 可以在服务端主机上,开启 RMI Server。jhat 可用于解析 hprof 内存 Dump 文件等。 在此不进行介绍,有兴趣可以搜索看看。 |












【本文地址】