| 【科普】集群基础和PBS任务管理常用命令 | 您所在的位置:网站首页 › 100GB是什么情况 › 【科普】集群基础和PBS任务管理常用命令 |
【科普】集群基础和PBS任务管理常用命令
|
最近需要用到集群做实验,学习下集群相关的内容。
什么是服务器集群
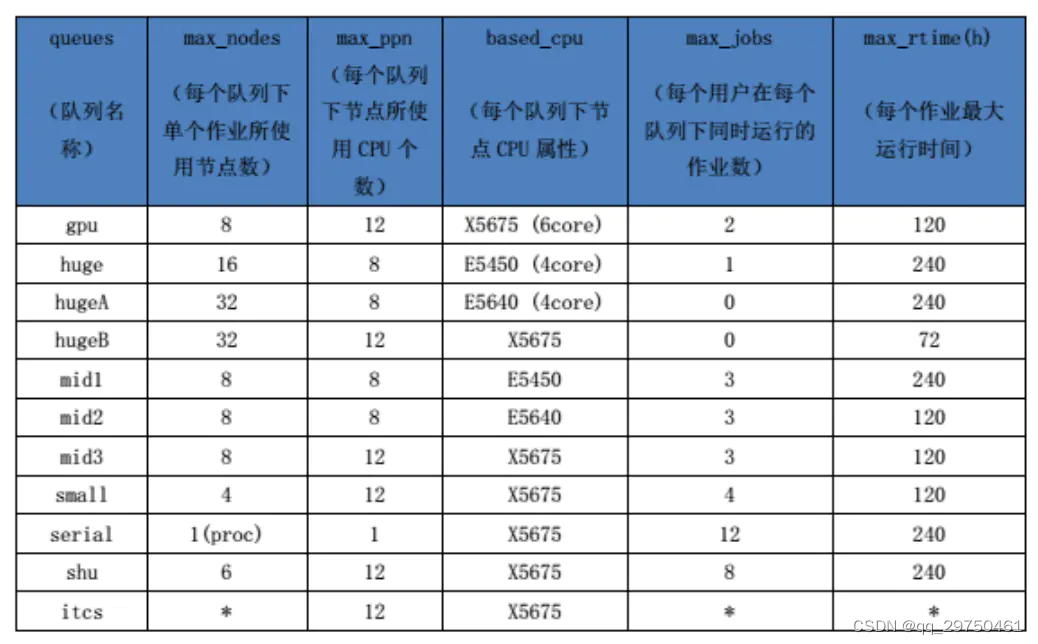
服务器集群其实就是将很多服务器(或者简单理解为主机)集中起来一起进行同一种服务,在客户端看来就像是只有一个服务器。集群可以利用多个计算机进行并行计算从而获得很高的计算速度,也可以用多个计算机做备份,若使用过程中任何一个机器坏了,整个系统不影响正常使用,但是如果同时坏的机器过多,一般是半数以上,则需要维修了。 集群各服务器节点间通过高性能的互连网络连接;各节点除了可以作为一个单一的计算资源供交互式用户使用外,还可以协同工作并表现为一个单一的、集中的计算资源供并行计算任务使用。 集群的硬件基础1 集群一般配制刀片计算节点的CPU或GPU作为计算节点 系统配备并行文件系统,各组刀片机之间的网络连接 系统配制登陆管理节点(一个性能强大的主机,类似台式机,主要负责管理节点,计算一般放在GPU上进行,另外配的有专门的存储装置,一般容量TB为计量),部署的集群管理系统。用户可根据登录节点IP,登录集群,提交作业,编译程序。 资源信息简表计算资源信息如下表。 1 会将整个集群划分为若干个队列(Queue),并根据队列的资源配置情况进行相应的命名; 2 每个队列下有若干个计算节点(nodes),每个计算节点配制若干个CPU(ppn); 3 对集群的一些其他信息说明和限制情况说明,如,CPU的型号和核数,用户可提交的作业树,每个作业的最大运行时间等。 在往集群上投递任务之前,首先要了解一下,该任务所需的计算资源是否能被集群所满足。 PBS 是一种常用的作业管理系统,其他类似的还有 LSF 和 SLURM。PBS会根据一个集群上的可用计算节点的计算资源管理和调度所有计算作业(无论是批处理作业还是交互式作业)。 PBS的目前包括openPBS, PBS Pro和Torque三个主要分支. 其中OpenPBS是最早的PBS系统, 目前已经没有太多后续开发,PBS pro是PBS的商业版本, 功能最为丰富. Torque是Clustering公司接过了OpenPBS, 并给与后续支持的一个开源版本。 其中,开源版本Torque主要包含下面的进程: 1 PBS服务守护进程: pbs_server 负责接收作业提交,位于服务节点 2 PBS调度守护进程: pbs_sched 负责调度作业,位于服务节点 3 PBS MOM守护进程: pbs_mom 负责监控本机并执行作业,位于所有计算节点 PBS — Torque 安装配置步骤1 在 master(管理结点上)解压安装包 [root@master tmp]# tar zxvf torque-2.3.0.tar.gz2 进入到解压后的文件夹 [root@master torque-2.3.0]# ./configure--with-default-server=master [root@master torque-2.3.0]# make [root@master torque-2.3.0]# make install3 生成后面安装计算节时需要的5个脚本文件, 作为在其它机器上安装用的安装包,运行完后会生成几个torque-package-*.sh文件 [root@master torque-2.3.0]# make packages4 初始化配置 [root@master torque-2.3.0]# sudo ./torque.setup wangwei #设置wangwei用户为管理用户5 设置计算节点 配置 /var/spool/torque/server_priv/nodes 文件(如果没有就手动添加),指定哪些节点作为计算节点,若管理节点不参与计算则去掉ww-master ww-master np=8 ww-slave1 np=8 ww-slave2 np=86 Torque主要是由三个主要部件组成 pbs_server PBS服务守护进程,负责接收作业提交,位于服务节点上 pbs_sched PBS调度守护进程,负责调度作业,位于服务节点上 pbs_mom PBS MOM守护进程, 负责监控本机并执行作业,位于所有计算节点上 # sudo pbs_server //在服务器节点执行 # sudo pbs_sched //在服务器节点执行 # sudo pbs_mom //在计算节点执行 # sudo trqauthd源码安装命令细节(这种最好就是root权限了,不然有些包,无法安装) linux下,源码的安装一般由3个步骤组成:配置(configure)、编译(make)、安装(make install) ./configure的作用是检测系统配置,生成makefile文件,以便你可以用make和make install来编译和安装程序。 ./configure --prefix --with;其中–prefix指的是安装路径,–with指的是安装本文件所依赖的库文件 如果不指定prefix,则可执行文件默认放在/usr/local/bin,库文件默认放在/usr/local/lib,配置文件默认放在/usr/local/etc。其它的资源文件放在/usr /local/share ./configure是源代码安装的第一步,主要的作用是对即将安装的软件进行配置,检查当前的环境是否满足要安装软件的依赖关系,但并不是所有的tar包都是源代码的包, 你先ls,看有没有configure或者makefile文件。 如果有configure,就./configure,有很多参数。如果系统环境合适,就会生成makefile,否则会报错。 如果有makefile,就直接make,然后make install。 PBS常用命令(有些商业集群,相关命令已改变,即以下的命令可能不完全适用于您的集群) 查看节点状态 pbsnodes (查看所有节点) pbsnodes -l free (查看空闲节点) pbsnodes 某节点 (查看某节点状态) 节点切换 ssh 某节点 (转到某节点) 退出节点 exit (离开节点) 查看任务运行状态 qstat (列出所有作业运行状态)其中使用 qstat 列出所有节点的状态,包含下面的信息 主要会包括以下几个方面信息: Job ID 任务ID号 Name 任务脚本名称 User 用户名 Time Use 任务运行时间 S State 任务状态 B 只用于任务向量,表示任务向量已经开始执行 E 任务在运行后退出 H 任务被服务器或用户或者管理员阻塞 Q 任务正在排队中,等待被调度运行 R 任务正在运行 S 任务被服务器挂起,由于一个更高优先级的任务需要当前任务的资源 T 任务被转移到其它执行节点了 U 由于服务器繁忙,任务被挂起 W 任务在等待它所请求的执行时间的到来(qsub -a) X 只用于子任务,表示子任务完成 C 表示程序正在被关闭,一般是程序运行错误,报错 Queue 任务执行所在队列 qstat -q (列出队列使用信息) qstat -n (列出队列中使用的节点) qstat -f jobid (查看jobid任务的详细信息) 提交任务到集群 qsub 文件名.pbs/.sh (提交任务) echo "script.py" | qsub -l q batch1 -l nodes=1:ppn=2 (直接在终端设置PBS资源命令,并在此资源下提交可执行脚本) 任务挂起,释放,重新加载 qhold:挂起作业 qrls:释放挂起的作业 qrerun:重新运行作业 任务更改 qmove:将作业移动到另一个队列 qalter: 更改作业资源属性 修改pbs队列: 将任务号为JOBID的任务,转移到Batch5 队列继续排队 qalter -W queue=Batch5 改变cpu数量: qalter -l nodes=1:ppn=10 qalter pbs 删除任务 qdel jobid (取消任务) 任务提交qsub 1 通过终端提交任务通过命令行参数传递给 qsub 命令 echo "python script.py -i inputdir -o outdir " | qsub -q Batch1 -l nodes=1:ppn=1 -l mem=40gb -N jobname执行script.py 脚本, 通过pbs投递任务, 任务提交到Batch1队列,所需资源为,1个节点,节点使用1个cpu, 40GB物理内存,该任务命名jobname 更多命令 -N 任务名称 -q 指定Queue -l resource_list 指定任务所需资源 一般包括: * cput=N, 请求N秒CPU时间,N也可以写成hh:mm::ss,单位分别是 时:分:秒 * mem=N[K|M|G|][B|W], 请求N大小的内存 * nodes=N, N个节点 * ppn=M, 每个节点需要M个cpu -e path 将标准错误重定向到path -o path 标准输出重定向到path -j join 将标准输出信息与标准错误信息合并到同一个文件join中去 -p priority 任务优先级,整数,无定义默认0 -m mail_options mail_option =a:左右abort时给用户发信;=b:作业开始时发信;=e:作业结束时发信. 默认=a 2 PBS通过sh脚本执行命令在 PBS 脚本中以 #PBS 方式指定 在PBS系统中,用户使用qsub命令提交用户程序。用户运行程序的命令 以及 PBS环境变量设置 共同组成了PBS作业脚本。 注释为 “#” 开头 PBS指令为 “#PBS” 开头 shell命令 (运行脚本的命令) #参数解析 #指定节点数目 ppn指每个节点运行的cpu数量(4个小节点,每个48个CPU) #PBS -l nodes=1:ppn=16 #指定合并到标准输出文件中 #PBS -j oe #设置程序运行的最大时间192小时 #PBS -l walltime=192:00:00 #指定qsub的所有环境变量都传递到批处理作业中 #PBS -V #输出文件 #PBS -o /public/home/tang/chaim/back_info/$jobname.out #错误输出文件 #PBS -e /public/home/tang/chaim/back_info/$jobname.err cd PBS_O_OUTDIR # 程序执行命令 python script.py -i inputdir -o outdir执行脚本命令 # 执行脚本 qsub run.sh # 制定命令开始运行的时间 qusb -a 070000 run.s #7天后运行程序,此时是处于W状态(等待状态) qsub -a 2400 run.s #24h后运行程序 3 通过交互式的方式执行任务 [#11#Rd01@login ~]$ $qsub -I -q Batch1 -l nodes=1:ppn=1 -l mem=80gb -N jobname qsub: waiting for job 1230615.admin to start qsub: job 1230615.admin ready [#1#Rd01@comput4 ~]$ $ 4 PBS常用环境变量PBS_ENVIRONMENT:批处理作业为 PBS_BATCH,交互式作业为 PBS_INTERACTIVE PBS_JOBID:PBS 系统给作业分配的标识号 PBS_JOBNAME:用户指定的作业名称 PBS_NODEFILE:包含作业所用计算节点的文件名 PBS_QUEUE:作业所执行的队列名称 PBS_O_HOME:执行 qsub 命令的 HOME 环境变量值 PBS_O_PATH:执行 qsub 命令的 PATH 环境变量值 PBS_O_SHELL:执行 qsub 命令的 SHELL 环境变量值 PBS_O_HOST:执行 qsub 命令节点名称 PBS_O_QUEUE:提交的作业的最初队列名称 PBS_O_WORKDIR:执行 qsub 命令所在的绝对路径 REF:http://events.jianshu.io/p/45e3f88086f3#1675845949194 |
【本文地址】