| 使用OpenAI CLIP进行文本到图像和图像到图像的搜索 | 您所在的位置:网站首页 › 算法是怎么应用到程序上 › 使用OpenAI CLIP进行文本到图像和图像到图像的搜索 |
使用OpenAI CLIP进行文本到图像和图像到图像的搜索
|
一、前言
在现如今信息量爆炸的时代,像政府、公安和零售等行业面临着海量的数据处理需求。比如,在车辆卡口数据中,需要快速检索和匹配大量的信息,找到嫌疑车辆进行布控;在物品和商品识别方面,需要进行相似性搜索,找到相关性证据,还有在一些重大节假日,安保问题以及重点人员的布控,以前我们只能基于结构化数据使用Flink或者Spark等大数据框架做海量大数据的实时比对。如果在只有一张图片的时候,如何从庞大的数据仓库中快速检索找到相似性TopN条结果记录也成为了一个重要的业务场景。 在这种情况下,利用最先进的人工智能解决方案能够应对这些挑战。OpenAI的CLIP就是一个深度学习算法,它能够轻松地连接文本和图像。通过使用CLIP,我们可以有效地进行准确且高效的搜索,实现车辆卡扣数据的海量信息检索和基于图片的快速匹配。同时,CLIP还能够自动识别物品和商品的特征,进行相似性搜索,满足嫌疑人比对等业务需求。无论是在政府、公安还是零售行业,利用CLIP进行图像搜索和匹配都具有重要的应用价值。 二、什么是CLIP?CLIP(对比语言-图像预训练)是OpenAI在2021年2月发布的一种最先进的模型。它是一个神经网络,在大约4亿个(文本和图像)对上进行了训练。CLIP使用对比学习的方法来统一处理文本和图像,从而能够通过文本-图像相似度来完成图像分类等任务,而无需直接优化任务,类似于GPT-2和GPT-3的零样本功能。与原始的ResNet50相比,我们发现CLIP在ImageNet上能够匹配性能,而且没有使用任何原始的128万个标记示例,成功克服了计算机视觉中的几个主要挑战。 除了文本和图像搜索,CLIP还可以应用于图像分类、图像生成、图像相似度搜索、图像排名、目标跟踪、机器人控制、图像字幕等多个领域。CLIP的强大之处在于它可以在没有特定领域训练的情况下,判断给定的图像和文本描述是否匹配,使得它成为一个非常强大的开箱即用的文本和图像搜索工具。这也是本文的重点所在。 三、为什么你应该采用CLIP模型?以下是一些促进了AI社区采用CLIP模型的原因 3.1、CLIP效率高使用对比目标提高了CLIP模型在零样本ImageNet分类上的效率,比现有模型高出4到10倍。此外,采用视觉变换器相比标准ResNet又增加了3倍的计算效率。
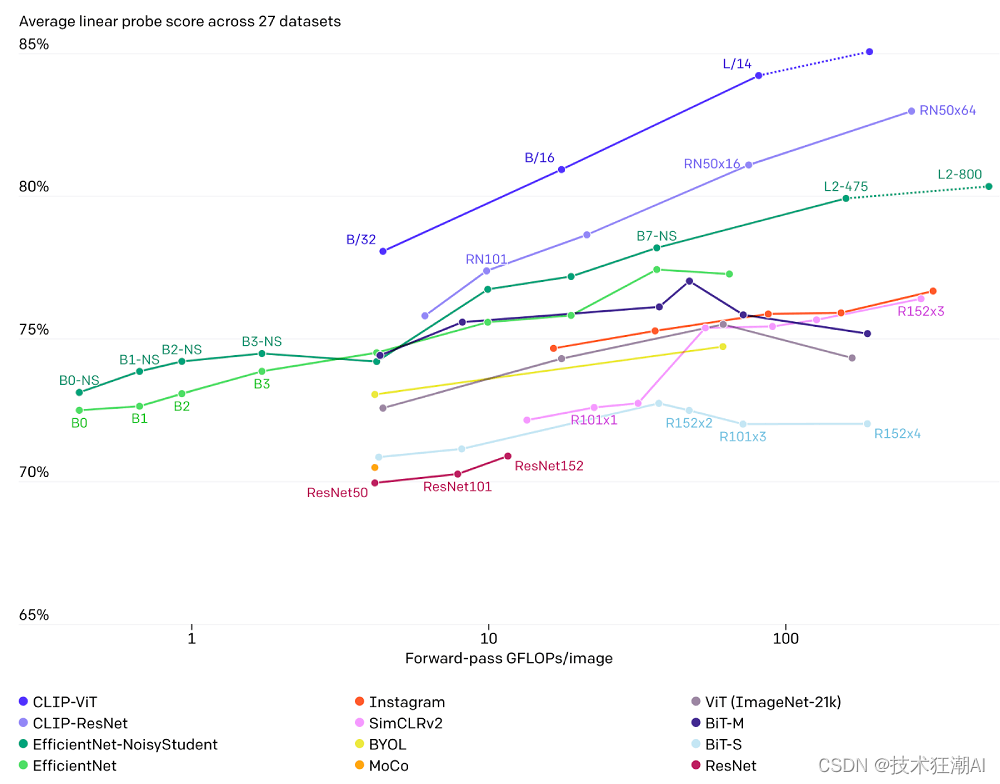
CLIP 在新领域超越了现有的ImageNet模型,因为它能够直接从自然语言中学习各种视觉表示。 下面的图形突出了CLIP零样本性能与ResNet模型少样本线性探测性能在细粒度物体检测、地理定位、动作识别和光学字符识别任务上的比较。
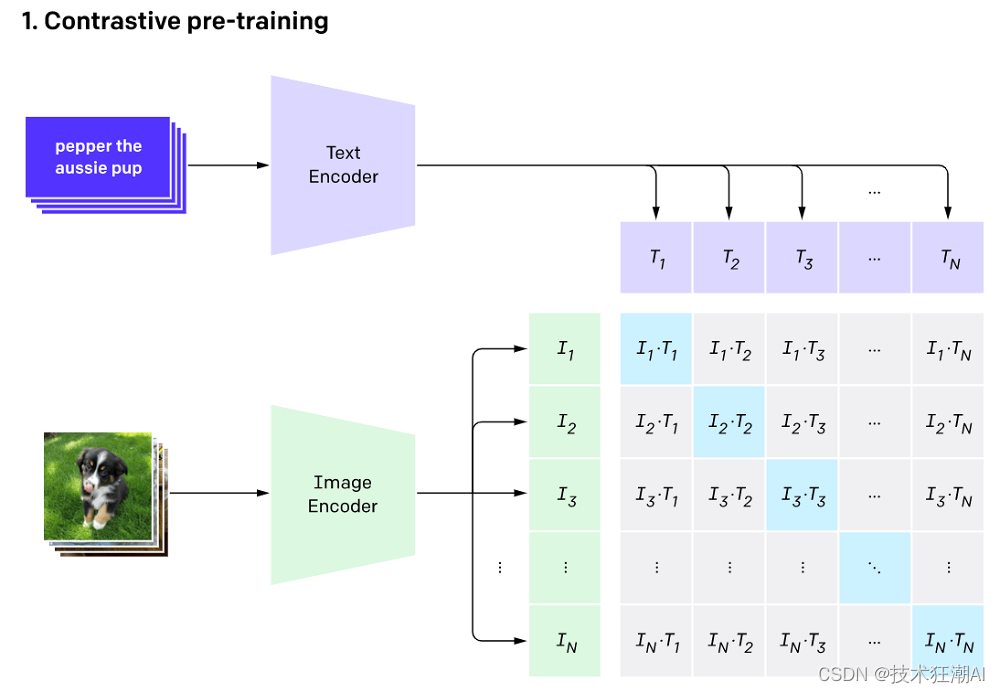
CLIP架构由两个主要组成部分组成:一个文本编码器和一个图像编码器。这两个编码器被联合训练,以预测一批训练样本(图像,文本)的正确配对。 文本编码器的主干是一个变换器模型,其中包含了6300万个参数,12层,并且采用了512宽的模型,其中包含8个注意力头。 图像编码器则使用了视觉变换器(ViT)和ResNet50作为主干,负责生成图像的特征表示。 4.1、CLIP算法是如何工作的?CLIP算法的工作原理可以通过以下三个方法来解释: (1)、对比预训练:CLIP使用对比学习的方法进行预训练。它通过将图像和文本配对作为训练样本,使得模型能够学习到图像和文本之间的相互关系。通过预测给定图像的最相关文本片段,CLIP能够将图像和文本统一起来。 (2)、从标注文本创建数据集分类器:CLIP利用标注文本来创建一个数据集分类器。它使用大量的图像和相关的文本描述来训练一个分类器,使得模型能够根据图像的特征来预测其所属的类别。这样,CLIP可以在没有具体标注的图像数据集上进行分类。 (3)、应用零样本技术进行分类:CLIP使用零样本技术进行分类,即在没有见过的类别上进行分类。通过学习图像和文本之间的关系,CLIP可以根据给定的文本描述来判断图像是否属于某个类别,即使它在训练阶段没有见过该类别的图像样本。 通过这三种方法,CLIP能够实现强大的文本-图像关联能力,并应用于多个领域,如图像分类、图像生成、图像搜索等。
在对比预训练阶段,CLIP算法通过以下步骤进行训练: 将一批大小为32768的图像和文本配对,分别通过文本编码器和图像编码器生成它们的向量表示。 训练过程中,通过在整个批次中搜索每个图像对应的最接近的文本表示,来最大化实际图像和文本对之间的余弦相似度。这意味着将实际图像与最相关的文本进行匹配。 同时,通过最小化实际图像与其他所有文本之间的余弦相似度,使得实际图像与其他文本区分开来。这样可以确保实际图像在向量空间中远离其他文本。 最后,通过对之前计算的相似度分数进行优化,使用对称交叉熵损失来训练模型。这个损失函数可以确保实际图像与其相关文本之间的相似度高,而与其他文本之间的相似度低。 通过这个对比预训练阶段,CLIP算法能够学习到图像和文本之间的关联性,并生成能够将它们统一起来的向量表示。
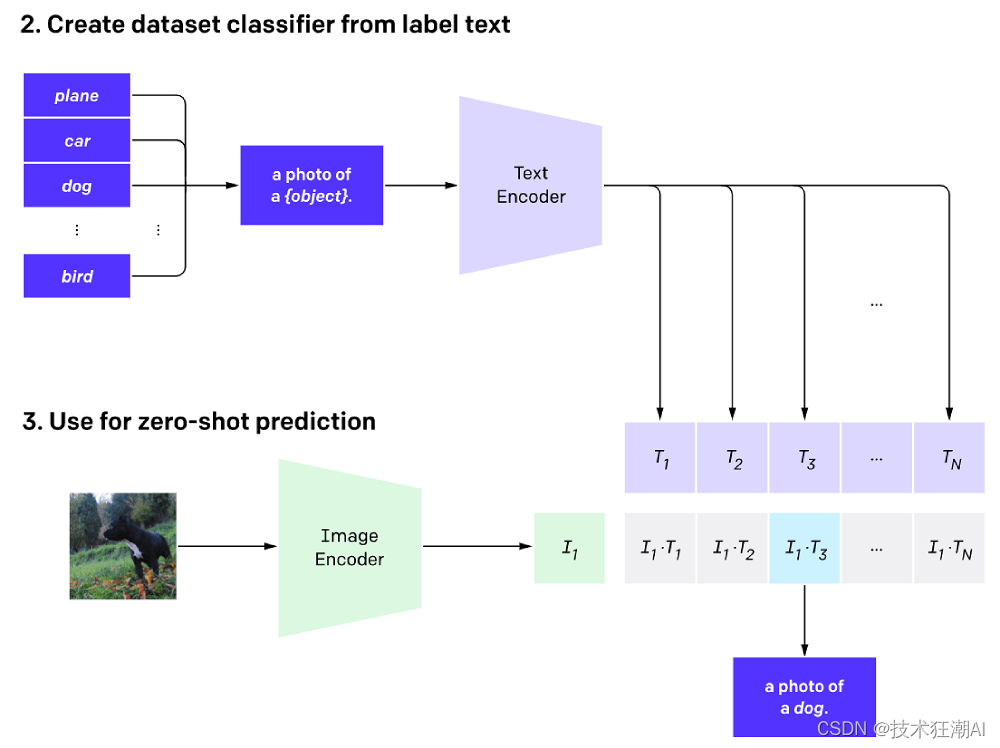
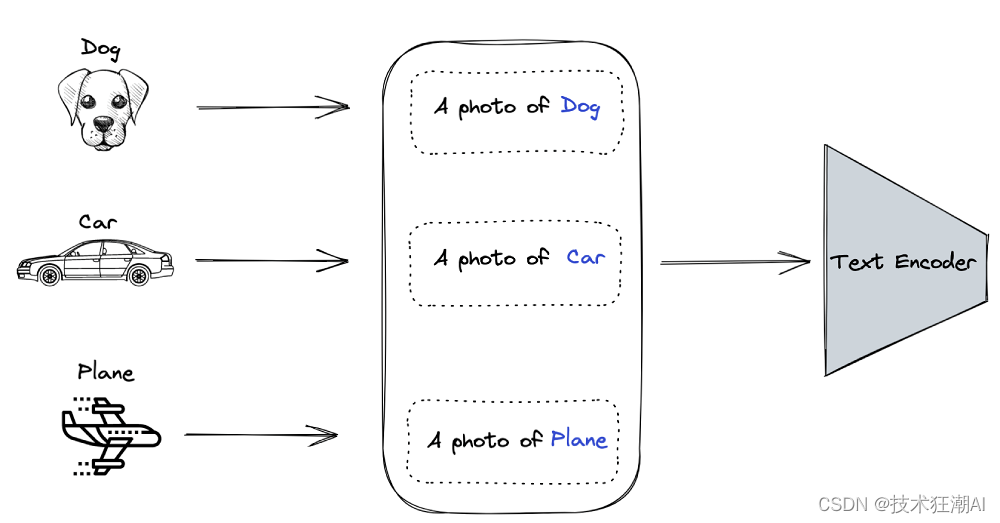
从标注文本创建数据集分类器的过程如下: 1)、将所有的标签/对象编码为特定的上下文格式:“一张{对象}的照片”。每个对象都通过文本编码器生成一个向量表示。 2)、假设我们有狗、汽车和飞机作为数据集的类别,那么我们将生成以下上下文表示: 一张狗的照片 一张汽车的照片 一张飞机的照片 通过这种方式,每个类别都对应一个特定的上下文表示,用于描述该类别的图像。这样,我们就可以使用这些上下文表示来训练数据集分类器,使其能够根据图像的特征来预测其所属的类别。
在使用零样本预测的阶段,我们利用第2节的输出来判断每个图像向量对应于哪个上下文向量。采用零样本预测的方法可以提高CLIP模型在未见过的数据上的泛化能力。 通过零样本预测,CLIP模型可以将先前学习到的图像和文本之间的关联性应用于新的图像数据上。这意味着即使模型在训练过程中没有见过这些新图像,它仍然可以根据图像向量和上下文向量之间的相似性来预测它们的匹配关系。 使用零样本预测的好处在于,它使得CLIP模型能够更好地泛化到未见过的数据上。这意味着即使在面对新的图像数据时,模型也能够准确地识别和分类它们,而不需要重新训练或进行标注。这为模型的应用和推广提供了更大的灵活性和可扩展性。 五、使用Python实现CLIP现在我们已经了解了CLIP的架构和工作原理,接下来我们将通过实现两个真实场景来演示如何使用CLIP。首先,我们将学习如何使用自然语言进行图像搜索,然后我们将学习如何使用图像进行图像搜索。在完成这个过程的最后,我们将了解使用向量数据库在这些用例中的优势。 5.1、用例的一般工作流程通过下面的工作流程来解释端到端的过程。我们从Hugging Face数据集中获取数据,然后使用图像和文本编码器进行处理,生成向量表示。最后,我们使用Pinecone客户端将这些向量插入到向量索引中。 用户可以根据文本或另一张图像来搜索图像。具体流程如下: 1)、收集数据集:从Hugging Face数据集中获取需要的数据。 2)、图像和文本编码:使用CLIP的图像编码器和文本编码器对图像和文本进行编码,生成相应的向量表示。 3)、向量索引:使用Pinecone客户端将生成的向量表示插入到向量索引中。 4)、图像搜索:用户可以根据文本或另一张图像进行搜索,通过计算相似性得分来找到最匹配的图像。 通过这个过程,我们可以利用CLIP模型的能力来实现图像搜索的功能,无论是基于文本还是基于图像的搜索。这种方法能够帮助我们快速准确地找到与我们查询相关的图像,并且具有较高的灵活性和可扩展性。
为了实现CLIP,需要安装以下库。 安装库 !pip install -qU transformers torch datasets gdcm pydicom pinecone-client导入必要的依赖库 import os import torch import skimage import requests import numpy as np import pandas as pd from PIL import Image from io import BytesIO import IPython.display import matplotlib.pyplot as plt from datasets import load_dataset from collections import OrderedDict from transformers import CLIPProcessor, CLIPModel, CLIPTokenizer 5.3、数据获取和探索概念字幕数据集包含大约330万张图像,主要有两列:图像URL和对应的字幕。你可以从对应的Hugging Face链接中获取更多详细信息。 # https://huggingface.co/datasets/conceptual_captions image_data = load_dataset("conceptual_captions", split="train")
并不是数据集中的所有URL都是有效的。为了解决这个问题,我们将测试并删除所有错误的URL条目。 """ 并非所有的URL都是有效的。如果URL有效,该函数返回True;否则返回False。 """ def check_valid_URLs(image_URL): try: response = requests.get(image_URL) Image.open(BytesIO(response.content)) return True except: return False def get_image(image_URL): response = requests.get(image_URL) image = Image.open(BytesIO(response.content)) # 如果图像有透明度通道,则转换为RGBA格式 if image.mode == "P" and "transparency" in image.info: image = image.convert("RGBA") else: image = image.convert("RGB") return image def get_image_caption(image_ID): return image_data[image_ID]["caption"]下面的代码会创建一个新的数据框,其中包含一个新的列"is_valid",当URL有效时为True,否则为False。 # 转换 dataframe image_data_df["is_valid"] = image_data_df["image_url"].apply(check_valid_URLs) # 获取有效的URL image_data_df = image_data_df[image_data_df["is_valid"]==True] # 从URL获取图像 image_data_df["image"] = image_data_df["image_url"].apply(get_image)然后,我们将从URL下载图像。这样做可以避免频繁进行网络请求。 5.3.2、图像和文本嵌入实现要成功实现编码器,我们需要使用模型、处理器和分词器。下面的函数可以满足这些要求,根据给定的模型ID和设备(CPU或GPU)来创建相应的编码器。 def get_model_info(model_ID, device): # 将模型保存到设备上 model = CLIPModel.from_pretrained(model_ID).to(device) # 获取处理器 processor = CLIPProcessor.from_pretrained(model_ID) # 获取分词器 tokenizer = CLIPTokenizer.from_pretrained(model_ID) # 返回模型、处理器和分词器 return model, processor, tokenizer # 设置设备 device = "cuda" if torch.cuda.is_available() else "cpu" # 定义模型ID model_ID = "openai/clip-vit-base-patch32" # 获取模型、处理器和分词器 model, processor, tokenizer = get_model_info(model_ID, device) 5.3.3、文本嵌入我们首先从生成单个文本的嵌入开始,然后将相同的函数应用于整个数据集。 def get_single_text_embedding(text): inputs = tokenizer(text, return_tensors = "pt").to(device) text_embeddings = model.get_text_features(**inputs) # 将嵌入转换为NumPy数组 embedding_as_np = text_embeddings.cpu().detach().numpy() return embedding_as_np def get_all_text_embeddings(df, text_col): df["text_embeddings"] = df[str(text_col)].apply(get_single_text_embedding) return df # 将这些函数应用于数据集 image_data_df = get_all_text_embeddings(image_data_df, "caption") image_data_df.head()前五行看起来是这样的:
图像嵌入使用相同的过程,但使用不同的函数。 def get_single_image_embedding(my_image): image = processor( text = None, images = my_image, return_tensors="pt" )["pixel_values"].to(device) embedding = model.get_image_features(image) # 将嵌入转换为NumPy数组 embedding_as_np = embedding.cpu().detach().numpy() return embedding_as_np def get_all_images_embedding(df, img_column): df["img_embeddings"] = df[str(img_column)].apply(get_single_image_embedding) return df image_data_df = get_all_images_embedding(image_data_df, "image") image_data_df.head()文本和图像向量索引的最终格式如下:
在本节中,我们将讨论两种不同的向量存储和搜索方法:一种是使用本地数据框作为向量索引,另一种是使用Pinecone进行基于云的向量索引。这两种方法都使用余弦相似度度量。 5.4.1、使用本地数据框作为向量索引辅助函数gettopN_images可以生成与工作流程中描述的两种情况相关的相似图像:文本到图像搜索或图像到图像搜索。 from sklearn.metrics.pairwise import cosine_similarity def get_top_N_images(query, data, top_K=4, search_criterion="text"): """ 检索与查询相似的前K篇文章(默认值为5) """ # 文本到图像搜索 if(search_criterion.lower() == "text"): query_vect = get_single_text_embedding(query) # 图像到图像搜索 else: query_vect = get_single_image_embedding(query) # 相关列 revevant_cols = ["caption", "image", "cos_sim"] # 运行相似度搜索 data["cos_sim"] = data["img_embeddings"].apply(lambda x: cosine_similarity(query_vect, x)) data["cos_sim"] = data["cos_sim"].apply(lambda x: x[0][0]) """ 按余弦相似度列降序排序 在排序时从1开始,以排除与自身的相似度(因为它始终为1) """ most_similar_articles = data.sort_values(by='cos_sim', ascending=False)[1:top_K+1] return most_similar_articles[revevant_cols].reset_index()让我们来看看推荐图像的方法: 用户提供一个文本或一个图像作为搜索条件,默认情况下,模型执行文本到图像搜索。 在第20行,计算每个图像向量与用户输入向量之间的余弦相似度。 最后,在第28行,根据相似度分数对结果进行降序排序,并返回最相似的图像,排除与查询本身对应的第一个图像。 5.4.2、搜索示例这个辅助函数可以方便地可视化推荐的图像。每个图像都有相应的字幕和相似度分数。 import matplotlib.pyplot as plt import numpy as np def plot_images(images): for image in images: plt.imshow(image) plt.show() def plot_images_by_side(top_images): index_values = list(top_images.index.values) list_images = [top_images.iloc[idx].image for idx in index_values] list_captions = [top_images.iloc[idx].caption for idx in index_values] similarity_score = [top_images.iloc[idx].cos_sim for idx in index_values] n_row = n_col = 2 _, axs = plt.subplots(n_row, n_col, figsize=(12, 12)) axs = axs.flatten() for img, ax, caption, sim_score in zip(list_images, axs, list_captions, similarity_score): ax.imshow(img) sim_score = 100*float("{:.2f}".format(sim_score)) ax.title.set_text(f"Caption: {caption}\nSimilarity: {sim_score}%") plt.show() 5.5、文本到图像首先,用户提供用于搜索的文本。 然后,我们运行一个相似度搜索。 最后,我们绘制算法推荐的图像。 query_caption = image_data_df.iloc[8].caption top_images = get_top_N_images(query_caption, image_data_df) print("Query: {}".format(query_caption)) top_images plot_images_by_side(top_images)第3行生成以下文本: 查询:运动队的队员在比赛中与另一支运动队进行滑冰比赛。 第9行产生以下绘制结果。
相同的过程适用于图像到图像搜索。唯一的区别是用户提供了一张图片而不是字幕。 query_image = image_data_df.iloc[27].image query_image
我们可以通过指定搜索标准来减少噪音。例如,只考虑与查询图片至少有60%相似度的图片。 最终结果如下所示。
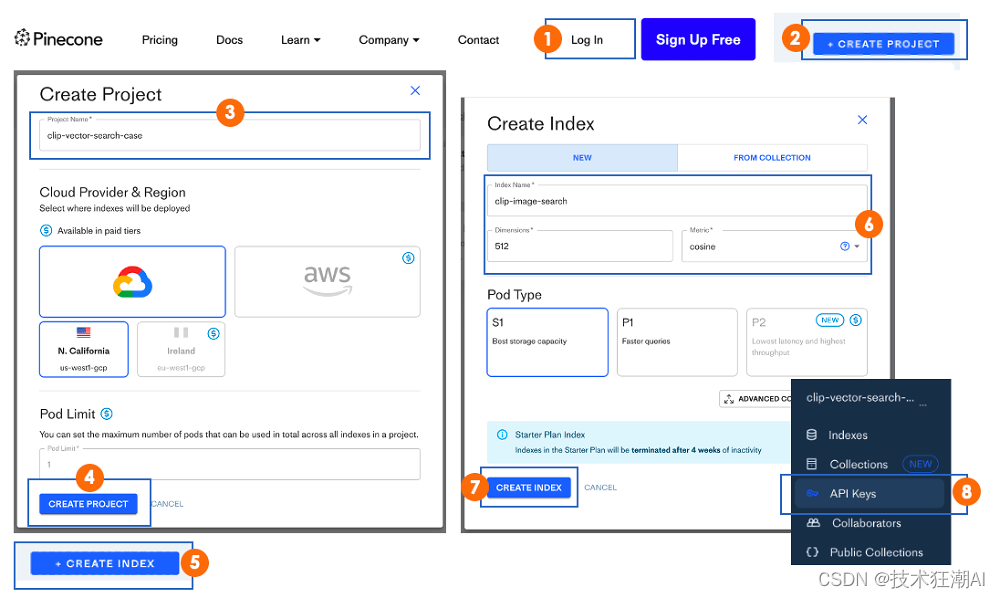
Pinecone提供了一个完全管理、易于扩展的向量数据库,可以轻松构建高性能的向量搜索应用。在本节中,我们将介绍从获取Pinecone API凭证到实现搜索引擎的步骤。 5.7.1、获取Pinecone API以下是从Pinecone网站获取API凭证的八个步骤。
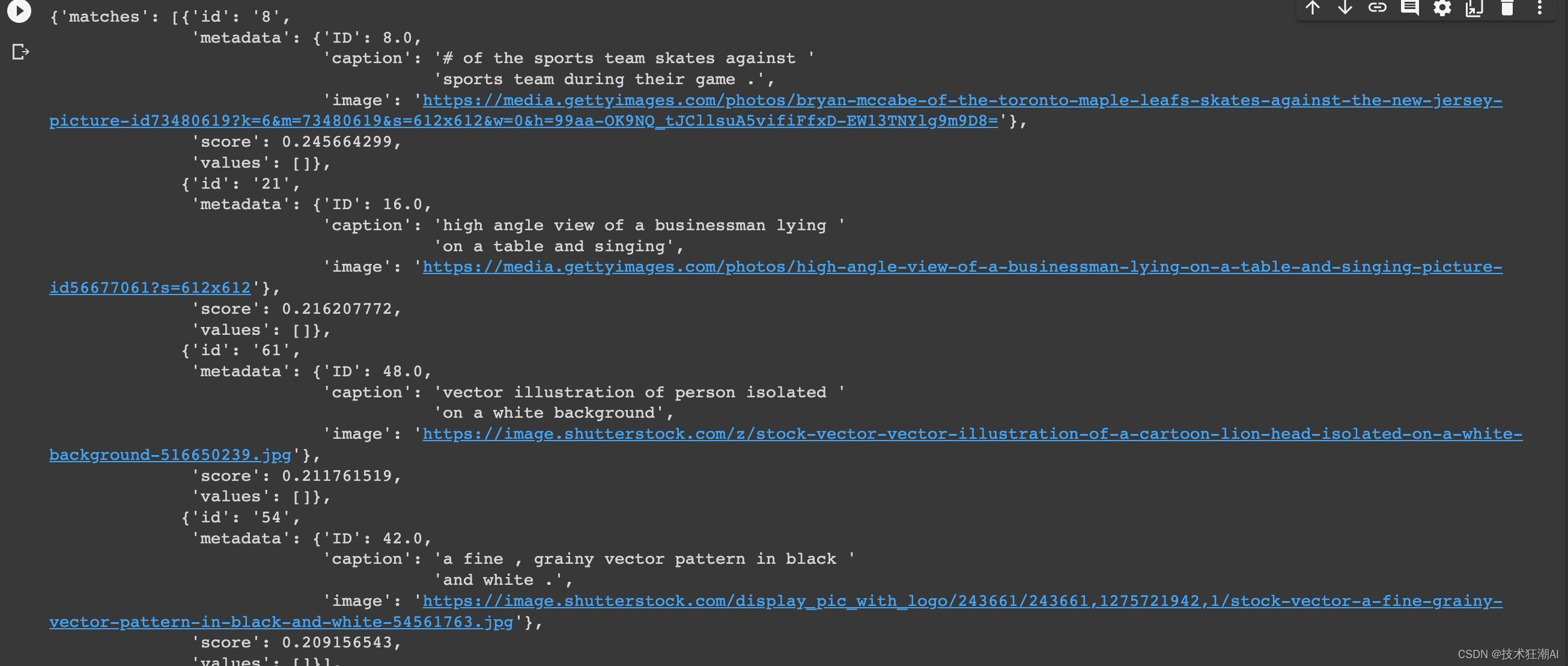
我们可以创建一个索引,用于执行创建、更新、删除和插入操作。 pinecone.init( api_key = "", # app.pinecone.io environment="us-west1-gcp-free" ) my_index_name = "clip-image-search" vector_dim = image_data_df.img_embeddings[0].shape[1] if my_index_name not in pinecone.list_indexes(): # 创建向量维度 pinecone.create_index(name = my_index_name, dimension=vector_dim, metric="cosine", shards=1, pod_type='s1.x1') # 连接到索引 my_index = pinecone.Index(index_name = my_index_name)pinecone.init部分初始化Pinecone工作区,以便进行后续的交互。 从第6行到第7行,我们指定了要创建的向量索引的名称以及向量的维度(在我们的场景中为512)。 从第9行到第14行,我们创建索引(如果它不存在)。 在下面的输出中,我们可以看到索引中没有数据。 my_index.describe_index_stats()我们只知道维度为512。 {'dimension': 512, 'index_fullness': 0.0, 'namespaces': {}, 'total_vector_count': 0} 5.7.3、填充数据库现在我们已经配置了Pinecone数据库,下一步是用以下代码填充它。 image_data_df["vector_id"] = image_data_df.index image_data_df["vector_id"] = image_data_df["vector_id"].apply(str) # 获取所有元数据 final_metadata = [] for index in range(len(image_data_df)): final_metadata.append({ 'ID': index, 'caption': image_data_df.iloc[index].caption, 'image': image_data_df.iloc[index].image_url }) image_IDs = image_data_df.vector_id.tolist() image_embeddings = [arr.tolist() for arr in image_data_df.img_embeddings.tolist()] # 创建以字典格式插入的单个列表 data_to_upsert = list(zip(image_IDs, image_embeddings, final_metadata)) # 上传最终数据 my_index.upsert(vectors = data_to_upsert) # 检查每个命名空间的索引大小 my_index.describe_index_stats()让我们来理解一下这里发生了什么: 要插入的数据需要三个部分:每个观察值的唯一标识符(ID)、嵌入列表和包含有关要存储数据的附加信息的元数据。 从第7行到第12行,通过存储每个观察值的“ID”、“字幕”和“URL”来创建元数据。 在第14行和第15行,我们生成一个ID列表,并将嵌入转换为一个列表列表。 然后,我们创建一个字典列表,将ID、嵌入和元数据映射在一起。 最后,我们使用.upsert()函数将数据插入到索引中。 与之前的场景类似,我们可以使用.myindex.describeindex_stats()检查所有向量是否已插入。 5.7.4、开始查询剩下的就是使用文本到图像和图像到图像搜索来查询我们的索引。两者都使用以下语法: my_index.query(my_query_embedding, top_k=N, include_metadata=True)myqueryembedding是用户提供的查询(字幕或图像)的嵌入(作为一个列表)。 N对应于要返回的结果数。 include_metadata=True表示我们希望查询结果包含元数据。 5.7.5、文本到图像 text_query = image_data_df.iloc[8].caption # 获取标题嵌入 query_embedding = get_single_text_embedding(text_query).tolist() # 运行查询 my_index.query(query_embedding, top_k=4, include_metadata=True)以下是查询返回的JSON响应
从“matches”属性中,我们可以观察到查询返回的最相似的四张图片。 5.7.6、图像到图像同样的方法适用于图像到图像搜索。 image_query = image_data_df.iloc[9].image这是用户提供的作为搜索条件的图片。
完成后不要忘记删除你的索引以释放你的资源: pinecone.delete_index(my_index) 六、使用Pinecone而不是本地pandas数据框的优势?使用Pinecone这种方法有几个优势: 简单性:与第一种方法相比,查询方法更简单,用户不需要管理向量索引。 速度:Pinecone方法更快,适用于大多数行业需求。 可扩展性:托管在Pinecone上的向量索引可以轻松扩展,而不需要额外的工作。而第一种方法在扩展时会变得越来越复杂和缓慢。 信息丢失的可能性更低:基于Pinecone的向量索引在云端进行托管,具有备份和高信息安全性。第一种方法在生产环境中风险较高。 网络服务友好:查询结果以JSON格式返回,可以轻松集成到网络服务中。 七、结论本文详细介绍了如何使用图像和自然语言来实现一个完整的图像搜索应用。首先,我们讨论了先决条件,包括所需的库和数据集。然后,我们学习了文本和图像嵌入的实现方法,以及如何进行数据预处理。接下来,我们探讨了两种不同的向量存储方法,包括使用本地数据框和基于云的向量索引。我们还展示了如何进行文本到图像和图像到图像的搜索,并提供了使用Pinecone进行向量索引管理的方法。最后,我们总结了使用Pinecone相比本地数据框的优势,并鼓励读者进一步学习相关资源。通过本文的学习,读者可以掌握如何构建一个高性能的图像搜索应用,并将其应用于实际项目中。 Jupyter Notebook 的完整代码:https://github.com/Crossme0809/frenzyTechAI/blob/main/clip-search/TexttoImageAndImagetoImageSearchwithOpenAICLIP.ipynb 参考文献 [1] A. Radford, J. W. Kim, et al., Learning Transferable Visual Models From Natural Language Supervision (2021) [2] A. Vaswani, et al., Attention Is All You Need (2017), NeurIPS 如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以关注「技术狂潮AI」公众号。在这里,你可以看到最新最热的AIGC领域的干货文章和案例实战教程。 |










【本文地址】