| 通过移动设备行为数据预测使用者的性别和年龄 | 您所在的位置:网站首页 › 用户行为预测结果可以用来分析什么 › 通过移动设备行为数据预测使用者的性别和年龄 |
通过移动设备行为数据预测使用者的性别和年龄
|
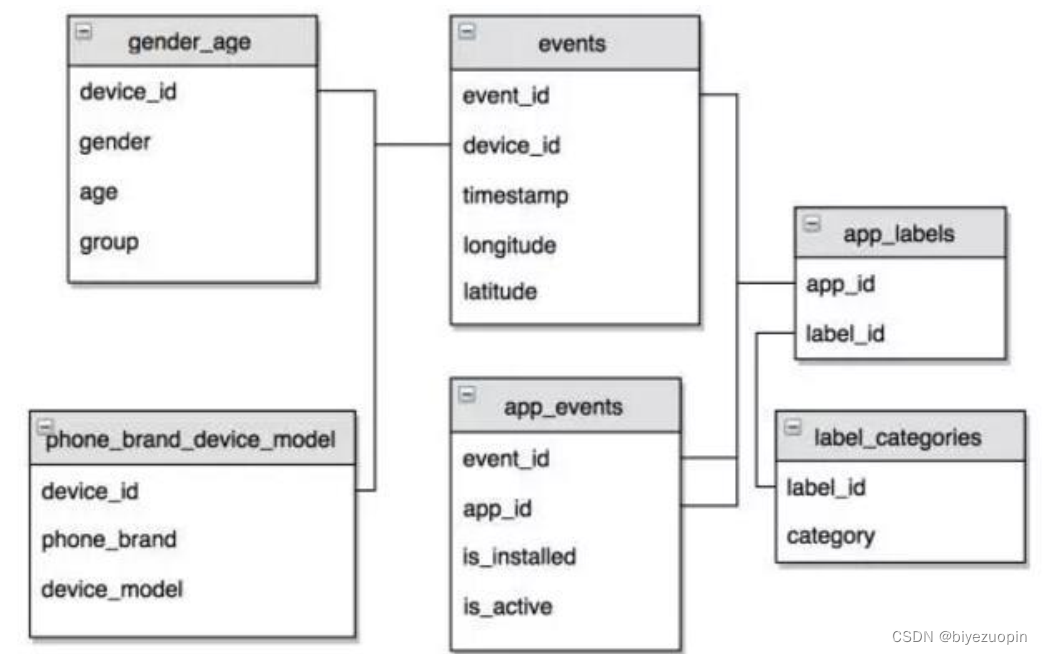
资源下载地址:https://download.csdn.net/download/sheziqiong/85657041 资源下载地址:https://download.csdn.net/download/sheziqiong/85657041 此项目为入门项目,用来了解: 多表连接,数据处理; OneHot编码 特征选择; 交叉验证选择参数 项目介绍:通过行为习惯对移动用户人口属性(年龄+性别)进行预测 数据及包含~20万用户数据,分成12组,同时提供了用户行为属性,如:手机品牌、型号、 APP的类型等 步骤: 解读数据特征工程模型调参 数据集结构
每个用户用一个ID表示,一个用户的行为是在一系列的Events里面,每个Event里面的信息包括该ID行为发生的时间、地理坐标信息,安装的APP类型、手机型号类别等 数据集基本信息: RangeIndex: 74645 entries, 0 to 74644 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- device_id 74645 non-null int64 gender 74645 non-null object age 74645 non-null int64 group 74645 non-null object dtypes: int64(2), object(2) memory usage: 2.3+ MB特征内容: device_id: 设备id (主键) gender:用户性别 age:用户年龄 event_id:事件id标识 group:用户分组 phone_brand: 手机品牌 device_model: 设备型号 timestamp: 事件发生时间 …… 项目流程: 分割数据集将原数据划分为训练集和测试集,用来验证训练出的模型准确率 加载数据 index_col='device_id';index_col='event_id'加载时,设定各表之间的关联键,实现表的连接 特征工程3.1 手机品牌特征 使用LabelEncoder将类别转换为数字,使用OneHotEncoder将数字转换为OneHot码,稀疏矩阵3.2 手机型号特征 合并手机品牌与型号字符串产生新的特征继续使用OneHotEncoder编码3.3 安装app特征 将表“event”和“app_events“进行连接,获取运行app的总次数和运行app的个数 n_run_s=device_app['app_id'].groupby(device_app['device_id']).size() n_app_s=device_app['app_id'].groupby(device_app['device_id']).nunique() 填充缺失数据,没有的数据简单粗暴,直接填03.4 合并所有特征 tr_feat=np.hstack((tr_brand_feat.toarray(),tr_model_feat.toarray(),tr_app_feat,tr_run_feat)) te_feat = np.hstack((te_brand_feat.toarray(),te_model_feat.toarray(), te_app_feat, te_run_feat))合并后:每个样本特征维度: 1800 tr_app_feat.shape: (1866, 1800) te_app_feat.shape: (1866, 1800)3.5 特征范围归一化,这里选用标准归一化 3.6 特征选择,通过标准差,方差初步筛除掉变化很小的特征 3.7 PCA降维操作,选取95%的重要性进行保留 pca=PCA(n_components=0.95) 处理后每个样本特征维度: 439 为数据添加标签对target特征‘group‘进行编码,标记为target 训练模型5.1 逻辑回归模型 clf=GridSearchCV(lr_model,lr_param_grid,cv=5) #网格搜索超参数5.2 SVM模型 svm_param_grid=[{'C':[1e-2,1e-1,1,10,100],'gamma':[0.001,0.0001],'kernel':['rbf']}] # 网格搜索超参数 best_svm_model=svm_grid.best_estimator_ best_svm_para = svm_grid.best_params_ 预测结果 logloss训练逻辑回归模型… 最好的回归模型参数是: {‘C’: 10} 训练SVM模型… 最好的svm模型参数是: {‘C’: 1, ‘gamma’: 0.001, ‘kernel’: ‘rbf’} 逻辑回归模型 logloss: 0.5017557850900733 SVM logloss: 0.846481034000951 资源下载地址:https://download.csdn.net/download/sheziqiong/85657041 资源下载地址:https://download.csdn.net/download/sheziqiong/85657041 |
【本文地址】