| Python爬虫:给我一个链接,虎牙视频随便下载 | 您所在的位置:网站首页 › 我想下载一个虎牙直播怎么下载 › Python爬虫:给我一个链接,虎牙视频随便下载 |
Python爬虫:给我一个链接,虎牙视频随便下载
|
1. 爬取的原理
小编经过分析发现, 第一个参数callback的值应该是:jQuery+一段随机字段+_+时间戳,既然有一段随机字段,那么这个不改直接用应该也是可以的;第二个参数r的值应该是固定的,这个直接用就行;第三个参数vid,也就是的视频的id,其实这个参数就是这个视频在服务器上的数据库中的id(小编猜测的,毕竟小编最近也在做相应的项目,也会使用到相应的id编号),这个参数在发布者视频下可以通过re正则表达式获取;第四个参数是format,应该是类型,这个应该也是固定的,直接copy即可;第五个参数也就是时间戳,直接copy或者写都行。 3. 代码和运行结果
代码如下: import requests from lxml import etree from crawlers.userAgent import useragent import re import json import time class video(object): def __init__(self,url): # url 为输入的链接 self.url = url self.page = 0 self.u = useragent() def getPages(self): # 获取当前链接界面的总页数 headers = {'user-agent':self.u.getUserAgent()} rsp = requests.get(url=self.url,headers=headers) html = etree.HTML(rsp.text) aList = html.xpath('//div[@class="user-paginator"]/ul/li/a') print('视频总页数为:',aList[-2].text) self.page = int(input("请输入想下载的视频页数:")) def downloadVideo(self): # 下载视频的方法,并没有下载视频,只是获取视频的下载链接 for i in range(1,self.page+1): if i == 1: url2 = '{}?sort=news'.format(self.url) else: url2 = '{}?sort=news&p={}'.format(self.url,i) headers = {'user-agent':self.u.getUserAgent()} rsp = requests.get(url=url2,headers=headers) html2 = etree.HTML(rsp.text) hrefs = html2.xpath('//div[@class="content-list"]/ul/li/a') for j in range(len(hrefs)): href = hrefs[j].xpath('./@href')[0] title = hrefs[j].xpath('./@title')[0] print('视频名称为:',title) vid = re.findall("/play/(\d*).html",href)[0] # 获取vid self.getDownloadHref(vid=vid) print('#'*50) time.sleep(2) def getDownloadHref(self,vid): url3 = 'https://v-api-player-ssl.huya.com' params={'callback': 'jQuery1124017458848743440036_1632126349635', 'r': 'vhuyaplay/video', 'vid': vid, 'format': 'mp4,m3u8', '_': '1632126349643'} rsp = requests.get(url=url3,headers={'user-agent':self.u.getUserAgent()},params=params) infos = rsp.text lindex = infos.find('(') rindex = infos.find(')') dict2 = json.loads(infos[lindex+1:rindex]) list2 = dict2['result']['items'] v_list2=['高清','原画','流畅'] for i in range(len(list2)): print(v_list2[i],list2[i]['transcode']['urls'][0]) if __name__ == '__main__': url = input("请输入视频链接:") v = video(url) v.getPages() v.downloadVideo()其中crawlers模块如果读者一直阅读小编的博客,就知道是来干什么的,如果读者是第一次来阅读小编的博客,可以去看看小编的这篇博客,博客链接为:Python爬虫:制作一个属于自己的IP代理模块 另外,小编并没有实现下载视频的功能,只是把视频的下载链接给提取出来了哈!爬虫需要遵守相应的法律法规,不能对服务器造成很大的负担,还有,就是,有的视频时间比较长,代码实现下载效果还没有直接copy下载链接到网页端下载那么高效,当然,有兴趣的读者可以自己去试试哈! 看看运行效果吧! 运用Python爬虫下载虎牙视频 对了,需要注意输入的视频链接喔! |
 我们来到虎牙视频主界面,链接为:虎牙视频主界面 然后随便点击一下某个视频的发布者,来到这个发布者的主界面,点击到视频,如下:
我们来到虎牙视频主界面,链接为:虎牙视频主界面 然后随便点击一下某个视频的发布者,来到这个发布者的主界面,点击到视频,如下: 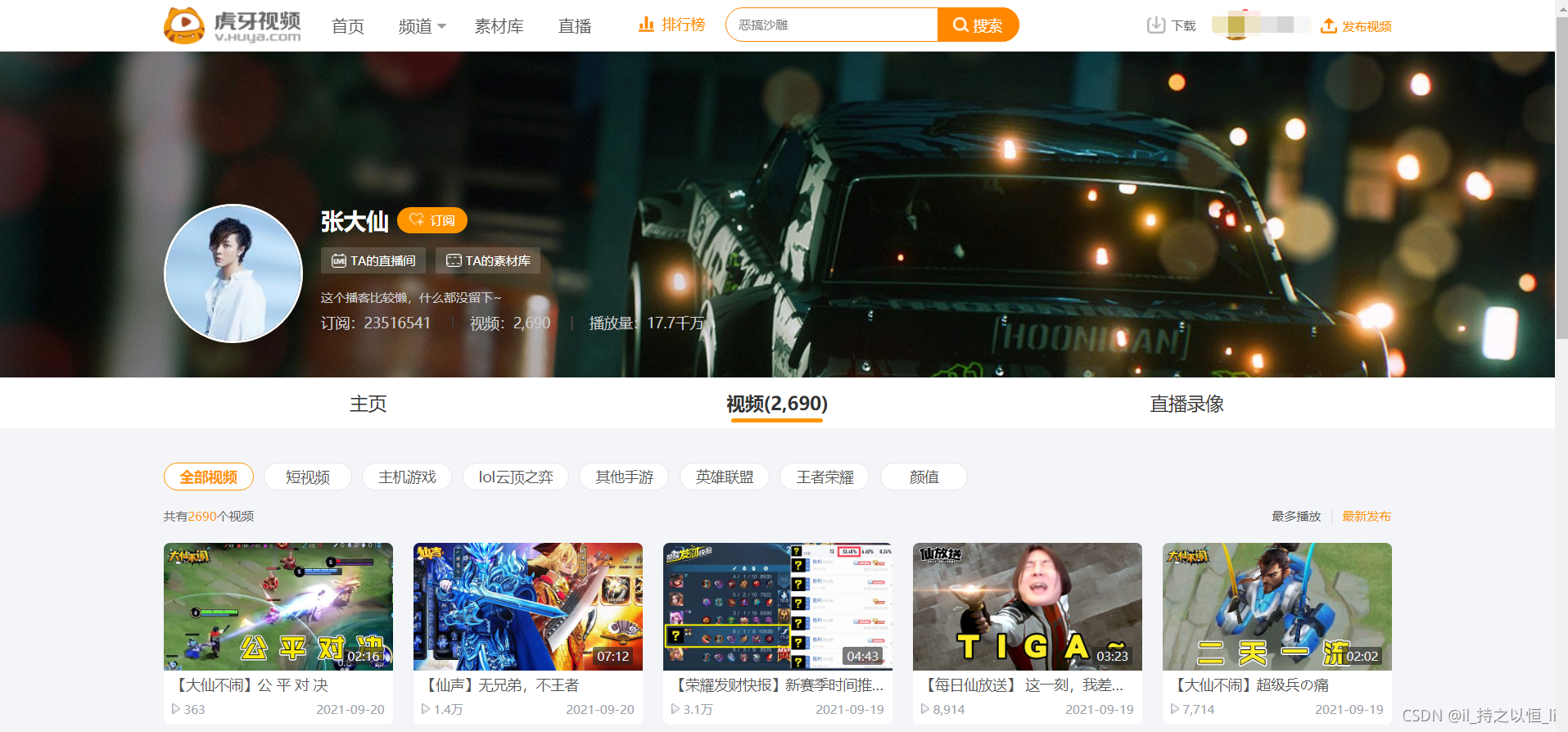 我们可以看到这个界面下有许多视频可以观看,那么怎样下载呢?我们随便点击其中的一个视频进入,按电脑键盘的F12来到开发者模式,然后点击network->js->找到相应的网址->视频下载链接
我们可以看到这个界面下有许多视频可以观看,那么怎样下载呢?我们随便点击其中的一个视频进入,按电脑键盘的F12来到开发者模式,然后点击network->js->找到相应的网址->视频下载链接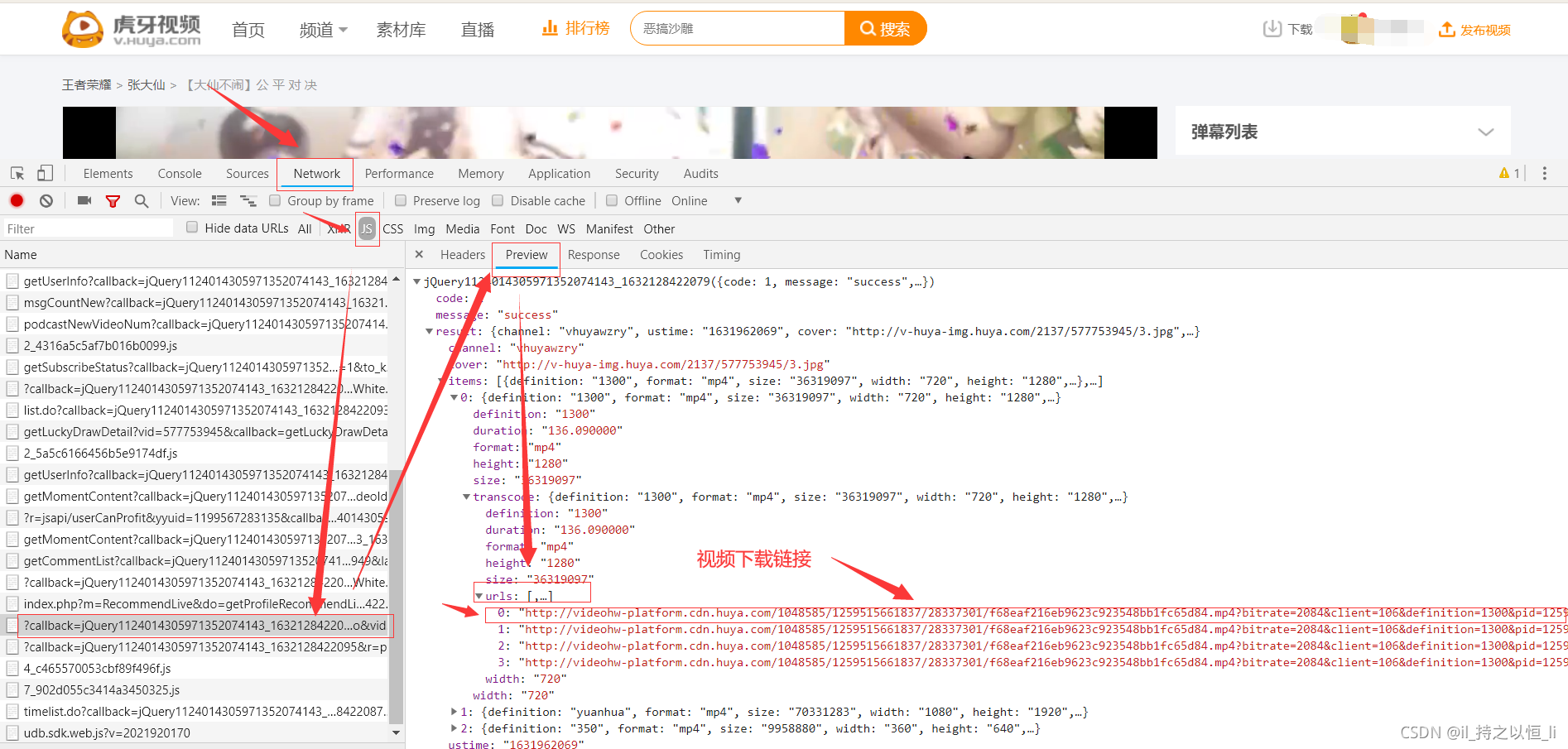 我们可以找到相应的视频下载链接。 那么怎样发起请求呢?这是一个get请求,网址为:https://v-api-player-ssl.huya.com,请求参数如下:
我们可以找到相应的视频下载链接。 那么怎样发起请求呢?这是一个get请求,网址为:https://v-api-player-ssl.huya.com,请求参数如下: 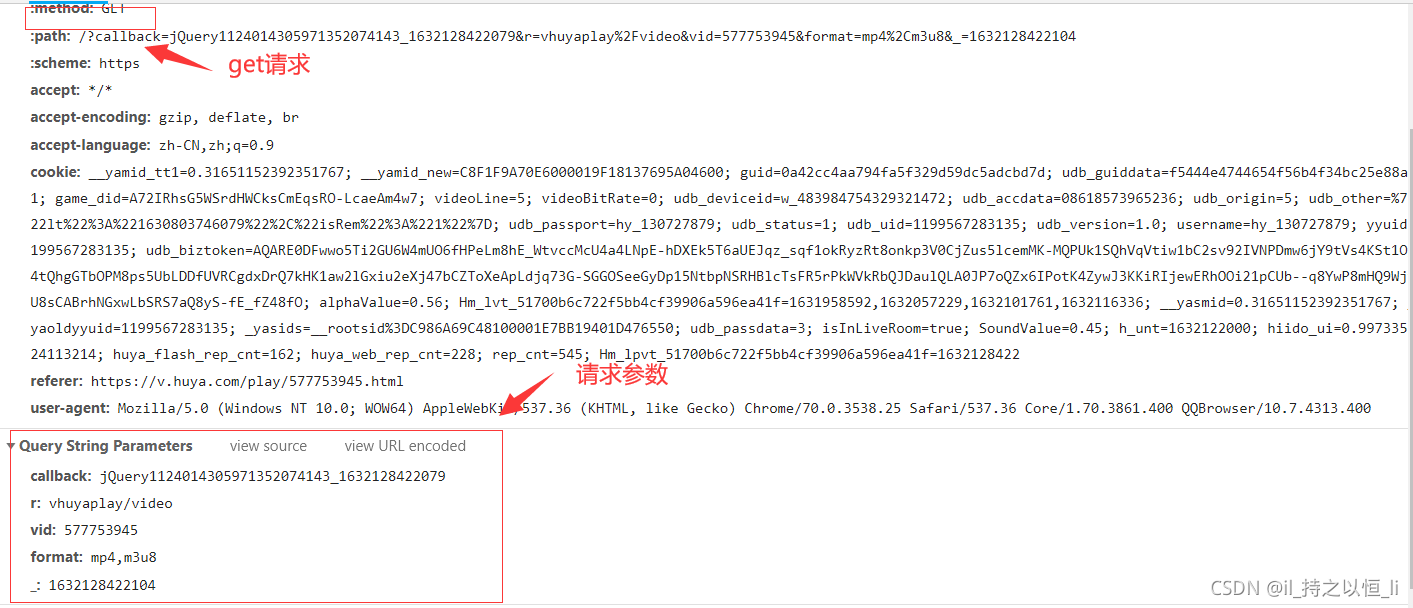 那么这些请求参数具体代表什么意思呢?
那么这些请求参数具体代表什么意思呢?
【本文地址】
公司简介
联系我们