| python怎么做网络爬虫 | 您所在的位置:网站首页 › 基于python的网络爬虫 › python怎么做网络爬虫 |
python怎么做网络爬虫
|
1 背景分析
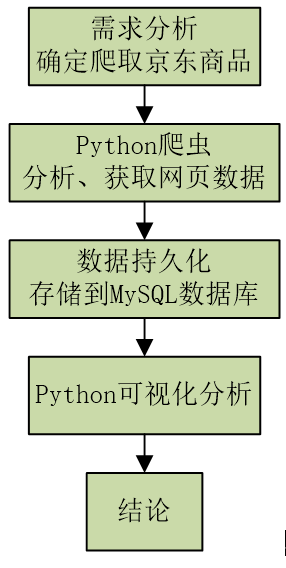
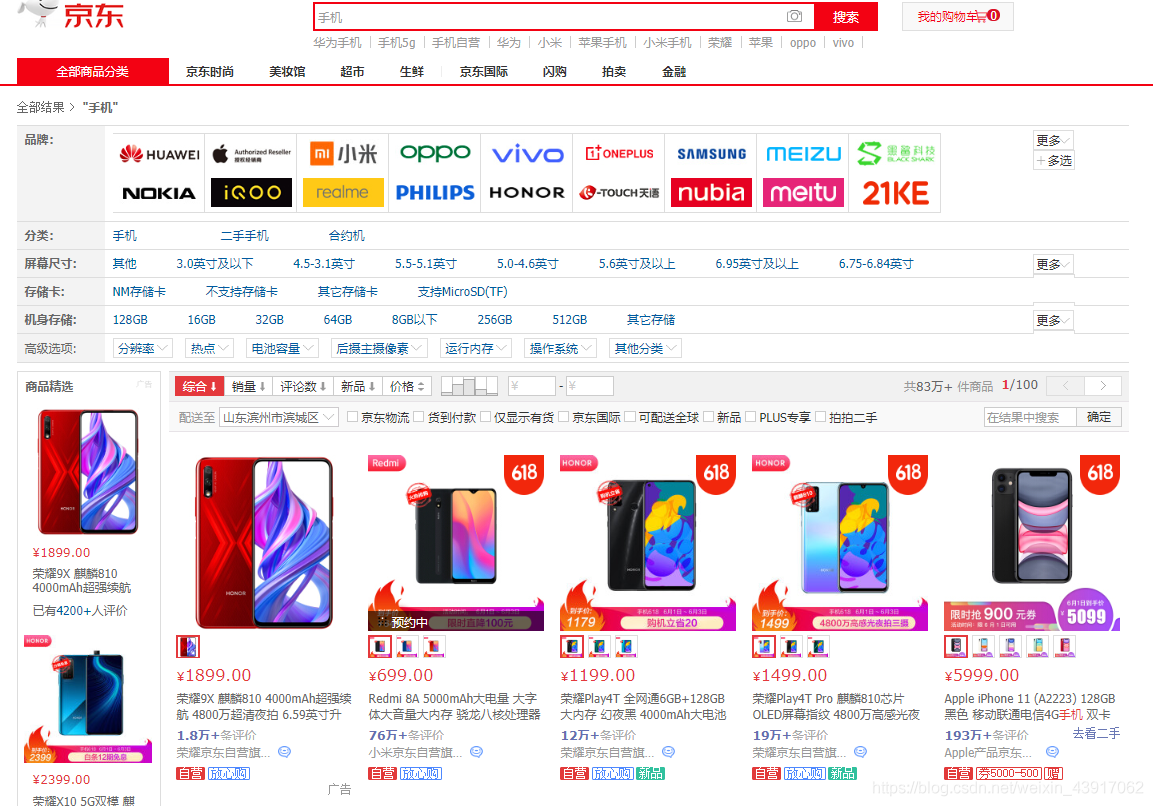
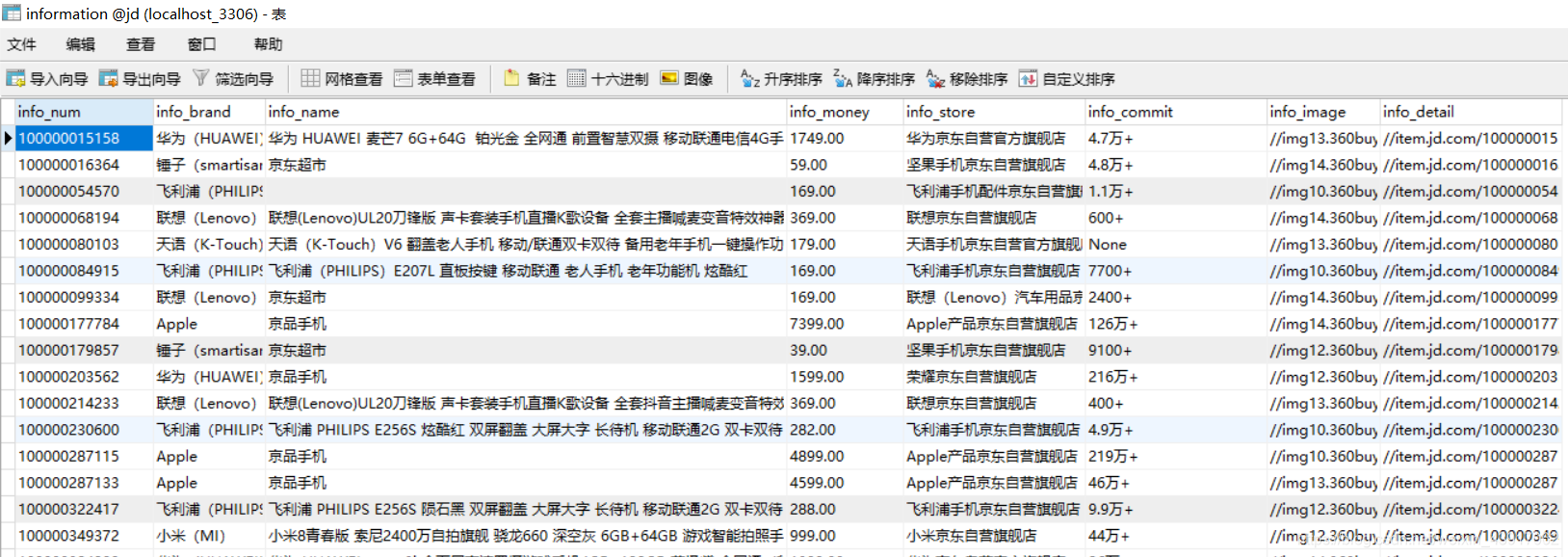
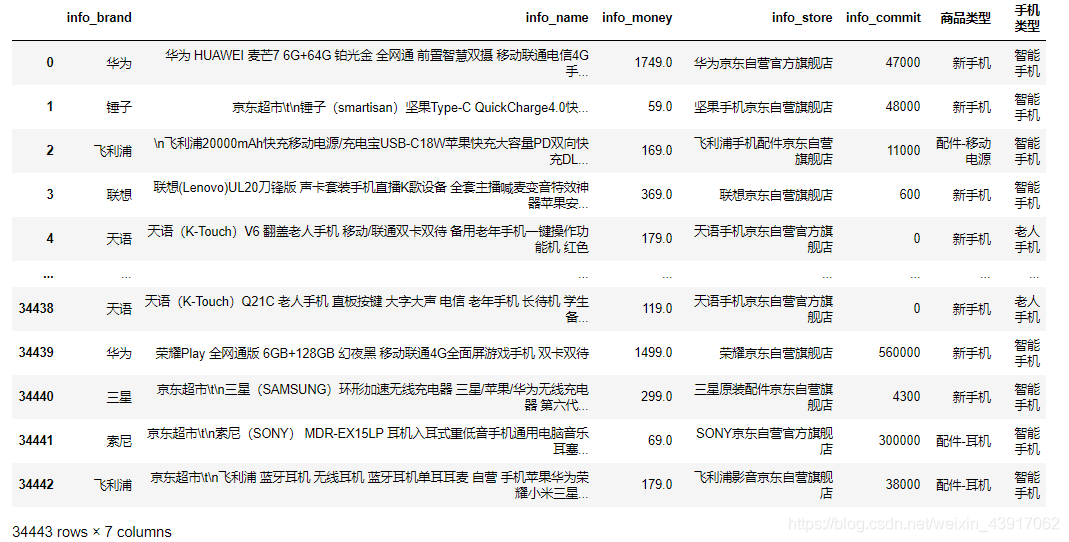
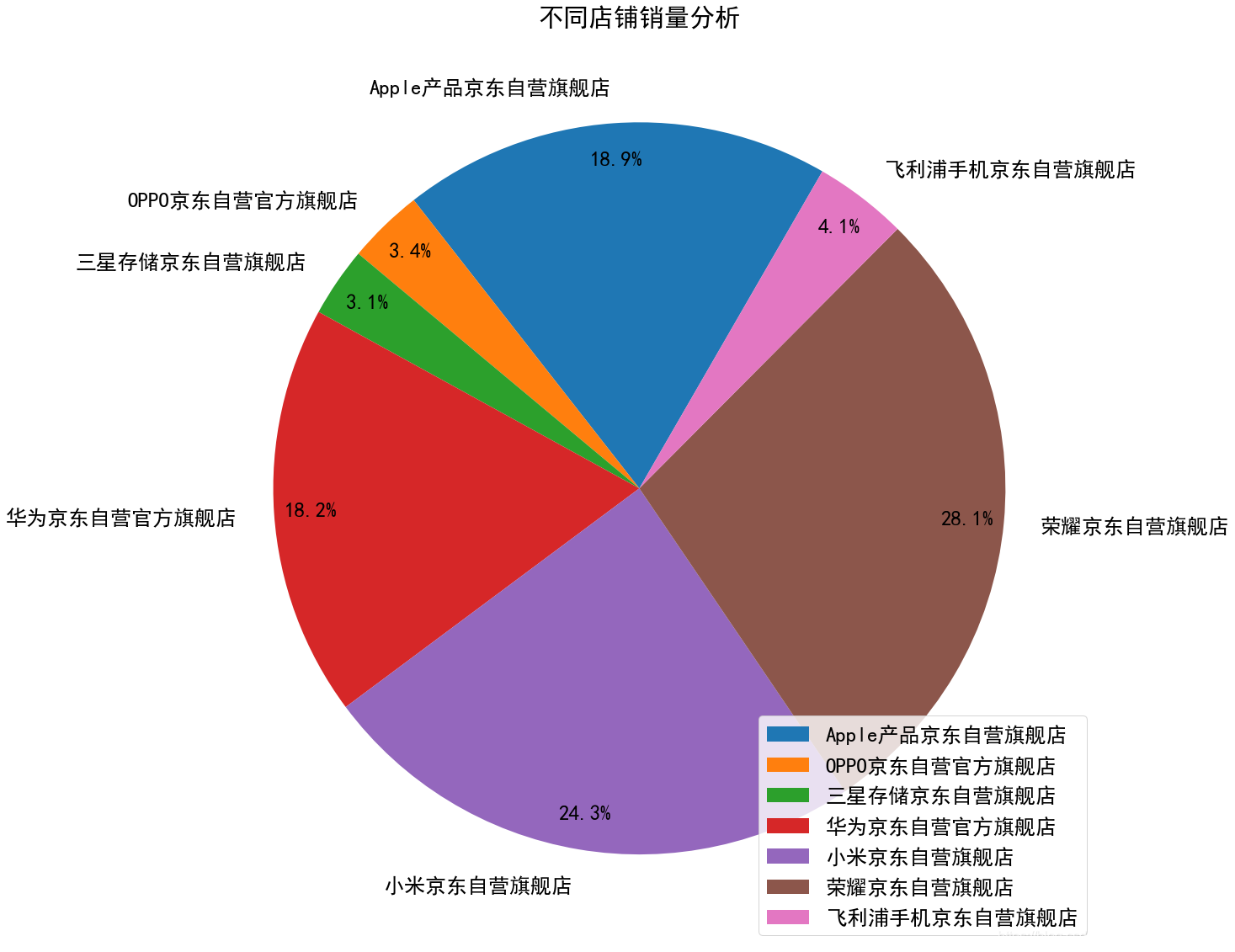
在互联网技术迅速发展的背景下,网络数据呈现出爆炸式增长,对数据的应用需要在大量数据中记性挖掘搜索,搜索引擎结合这一需求就应运而生,不只是搜索数据信息,还要帮助人们找到需要的结果被人们所应用。信息数据的处理就需要爬虫技术加以应用来收集网络信息。作为搜索引擎的重要组成部分,网络爬虫的设计直接影响着搜索引擎的质量。网络爬虫是一个专门从万维网上下载网页并分析网页的程序。它将下载的网页和采集到的网页信息存储在本地数据库中以供搜索引擎使用。网络爬虫的工作原理是从一个或若干初始网页的链接开始进而得到一个链接队列。伴随着网页的抓取又不断从抓取到的网页里抽取新的链接放入到链接队列中,直到爬虫程序满足系统的某一条件时停止。 Python语言简单易用,现成的爬虫框架和工具包降低了使用门槛,具体使用时配合正则表达式的运用,使得数据抓取工作变得生动有趣。在数据搜索方面,现在的搜索引擎虽然比刚开始有了很大的进步,但对于一些特殊数据搜索或复杂搜索,还不能很好的完成,利用搜索引擎的数据不能满足需求,网络安全,产品调研,都需要数据支持,而网络上没有现成的数据,需要自己手动去搜索、分析、提炼,格式化为满足需求的数据,而利用网络爬虫能自动完成数据获取,汇总的工作,大大提升了工作效率。 网络在我们的生活中越来越重要,网络的信息量也越来越大,研究该课题可以更好的理解网络爬虫的原理以及可视化分析的作用。 2 需求分析现在的社会已经进入了信息时代,尤其是网络购物成为一种很普遍的购物方式,大数据的获取和分析对于促进经济发展有着重要的意义。掌握消费者的爱好和习惯,有助于商家及时的调整商品的类型和定价。 手机在我们的日常生活中使用的越来越频繁,为了更好的掌握消费者对于手机品牌、价格以及店铺的喜好程度,我们选取京东网站的手机产品作为我们研究的目标,通过网络爬虫技术获取网站的数据,利用数据库技术存储数据,最后用可视化分析的形式给出我们最终的研究结果。 3 详细设计及技术原理项目设计主要分为几个步骤:根据需求,确定我们需要爬取的网站和数据类型;通过Python爬虫技术对网页进行解析;将数据持久化,存储到数据库中,以便于随时提取、查询、添加数据;通过获取的数据进行可视化分析,得到我们的结论。整个过程如图3.1所示: 网络爬虫技术,别名“网络蜘蛛”,指的就是一种通过依照既定程序自动获取网页信息或脚本的技术。其可以在互联网当中帮助搜索引擎下载各类信息资料,并通过依次进行数据的采集和分析处理。最后完成数据的统一存储。当程序处于正常运行阶段时,爬虫会从一个或多个初始URL开始下载网页内容,随后依托搜索方式或内容匹配法将网页中其所需内容进行精准“抓取”,与此同时爬虫也会不间断地从网页中获取新URL。当爬虫检索到的信息满足停止条件时将自动停止检索。此时其将自动进入到抓取数据的处理环节,通过构建索引并妥善存储数据,使得用户可以依照自身的实际需求随时提取、查阅数据库中的数据资料。 基于Python的网络爬虫技术,因使用了Python编写程序,可以抛弃传统笨重的IDE,仅使用一个文本编辑器便可以基本完成开发网络爬虫技术功能,为技术人员的编程工作提供巨大便利。加之Python本身拥有相对比较完善的爬虫框架,可支持迅速挖掘、提取和处理信息数据等程序任务。在充分发挥Python强大网络能力下,即便面对海量的信息数据检索要求,只通过编写少数代码便可以有效完成网页下载并利用其网页解析库,准确解读和表达各网页标签,以有效提升抓取数据的质量水平。 4 功能实现本项目以手机为例,对京东商城中50多个手机品牌(华为、Apple、小米、OPPO、VIVO……)进行了数据的爬取,获得了超过5万条的数据,包括商品品牌、商品名称、售价、店铺信息、评价量等信息,并将数据存储到MySQL数据库中。在数据分析阶段,我们对获取到的数据从多个角度进行了可视化分析,并给出了我们的结论。 4.1 网页分析 4.1.1 URL地址构建登录京东网站,搜索关键词“手机”可以发现,在返回的搜索结果中,虽然显示有83万+件商品,但页面只有100页,每页只有60件商品。这是由于京东网站的反爬虫机制,导致无法显示所有的商品。为了获得更多的数据量,我们采用二级关键词进行检索的方式,在图4.1中我们可以看到,在品牌那一栏有所有的手机品牌信息,如“华为手机”、“Apple手机”,这样可以在很大程度上增加我们的数据量。 构建URL地址。查看搜索二级关键词之后的网站地址:https://search.jd.com/search?keyword=%E6%89%8B%E6%9C%BA&wq=%E6%89%8B%E6%9C%BA&ev=exbrand_%E5%8D%8E%E4%B8%BA%EF%BC%88HUAWEI%EF%BC%89%5E。此时的网址看上去比较复杂,图中的汉字已经进行过重新编码,我们还需要对其简化处理,简化后构建的URL为: https://search.jd.com/Search?’ + parse.urlencode(keyword) + ‘&ev=exbrand_%s’%(华为) + ‘&enc=utf-8’ + ‘&page=%s’%(2n-1) 使用urlencode将keyword转码成可识别的url格式,enc以utf-8方式编码,并得传入对应page,得到完整的url。Keyword处代表关键词“手机”, exbrand后面代表的是二级关键词,如“华为(HUAWEI)”。另外京东网站的page变化规律是n2-1。这样就构建出我们的URL地址。 4.1.2 网页分析通过分析网页的元素,可以找到商品列表在good-list中,继续往下分析可以找到商品名称、手机价格、评价量、店铺信息、图片地址、商品地址等数据。首先导入bs4包,然后就可以使用BeautifulSoup库了,通过使用BeautifulSoup提供的强大的解析方法,即可解析出网页中我们想要的数据。 MySQL是一种关系型数据库,关系型数据库最重要的概念就是表,表具有固定的列数和任意的行数,在数学上称为“关系”二维表是同类实体的各种属性的集合,每个实体对应于表中的一行,在关系中称为元组,相当于通常的一条记录,表中的列属性,称为Field,相当于通常记录中的一个数据项,也叫做列、字段。 首先,打开数据库连接之前,一定保证打开MySQL服务,否则就会出现连接失败的情况。Navicat for MySQL是一款强大的MySQL数据库管理和开发工具,它为专业开发者提供了一套强大的足够尖端的工具,对于数据库的可视化是很方便简洁的。然后,我们要设置好数据库连接的相关配置,以便于我们可以在Python中成功连接数据库,包括数地址、端口号、用户名、密码,具体的配置信息如图4.3所示: 最后,在数据库中创建表格,用来存储数据。数据库建表语句如图4.4所示。我们建立的商品信息表包含8列,分别是商品ID、手机品牌、商品名称、价格、店铺信息、评论量、图片地址、商品详情页地址。并且以京东的商品ID为主键,这样做可以避免因为商品名称的重复导致的保存失败的情况,每一件商品的ID在京东商城里都是唯一的。 在完成上述工作及配置之后,我们就可以正式的编写代码来爬取数据了。将我们的爬虫伪装成浏览器去获取网页,然后对网页解析,得到我们需要的数据,最后将数据存储到MySQL数据库中。为了保证报告的美观和质量,在此部分将不再展示代码,全部的源代码见附录。最终得到的数据如图4.5所示: 在得到数据之后,我们对数据进行了全方面多维度的分析,在原有数据的技术上进行深度挖掘,具体的过程如下。 5.1 数据的预处理从图5.1中可以看出,由于我们直接得到的数据里面的数据类型以及可用的信息比较少,品牌名称比较混乱复杂,商品名称较长无法知道商品具体属性,评论数量单位不统一等,这些问题的存在会直接影响我们的分析结果。 为了更方便我们的处理,在可视化分析之前,我们对数据进行了预处理操作,如图5.2所示。首先对于手机品牌,删除无用的后缀括号里的内容,使名称看上去更加简洁。其次对评论量进行了处理,将带单位“万”的数据都进行了单位的统一,方便我们后续计算使用。然后我们利用关键词检索的方式,对商品类型进行了划分,判断出它们是属于手机还是配件,是新手机还是二手手机,这些对于后续的统计计算结果有着非常大的影响。最后,我们对手机类型进行了划分,分为智能手机、商务手机、老年手机、5G手机、学生手机,在后续的处理中,我们会对不同类型的手机价格及购买人数进行可视化分析。 我们主要从三个大角度对数据进行可视化分析:店铺销量分析、品牌商品分析、手机类型分析。由于京东网站上不显示具体的销量,这里我们把评论量近似等于购买人数,后面不再进行说明。 5.2 店铺销量分析 5.2.1 不同店铺销量分析我们选取了销量前7的店铺进行了对比分析,从图5.3中可以看出,“荣耀京东自营店”、“小米京东自营旗舰店”、“华为京东自营官方旗舰店”、“Apple产品京东自营旗舰店”的销量占比比重较大,也反映出华为、小米、Apple的手机产品在市场中占有比较大的份额。
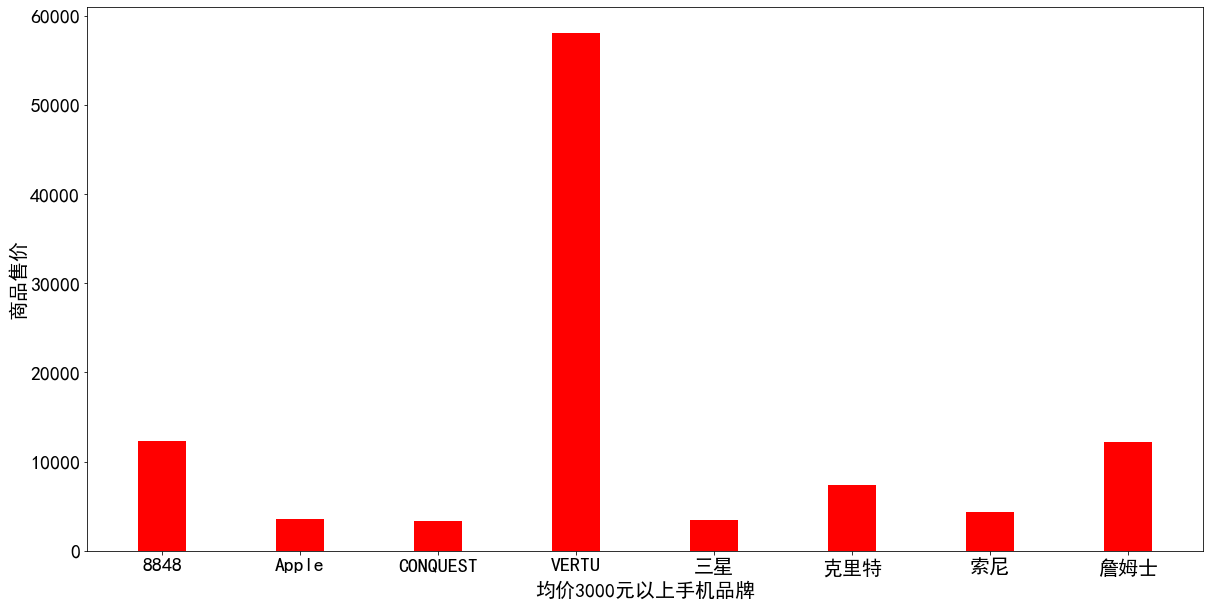
由于品牌众多,考虑到报告篇幅的限制,无法将所有的店铺均价一一对比显示,我们选取平均售价8000元以上的店铺进行对比分析。从图5.4中可以看出,“VERTU官方旗舰店”的手机均价最高,达到了近8万元,其他比较高端的手机品牌店铺售价也都在一万元左右。 5.3 品牌商品分析 5.3.1 不同价格区间购买人数为了更好的看到不同的价格区间的购买人数信息,我们对原始数据进行了价格分层,500元以下、500-1000元、1000-3000元、3000-5000元、5000元以上。从图5.5中可以看出,大部分人的选择在1000-3000元之间,占比39.55%。只有7.33%的人选择购买5000元以上的手机。 在图5.6中,我们以柱状图的形式将不同品牌的平均价格展示出来,从中可以看出,均价3000元以上的手机品牌中,Vertu品牌的均价最高,达到近6万元,其他品牌均价在1万元左右;均价1000-3000元的手机品牌的差距不是特别明显,黑鲨、华为、OPPO、iQOO、一加这几个品牌的手机均价较高。
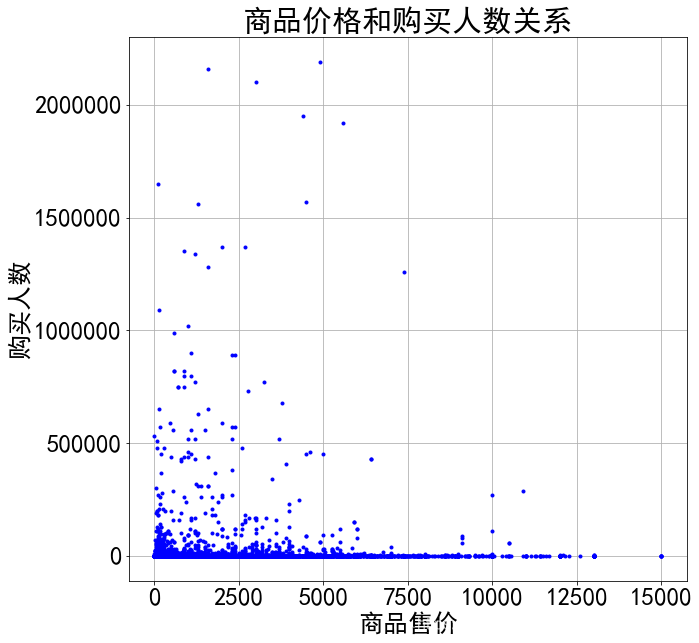
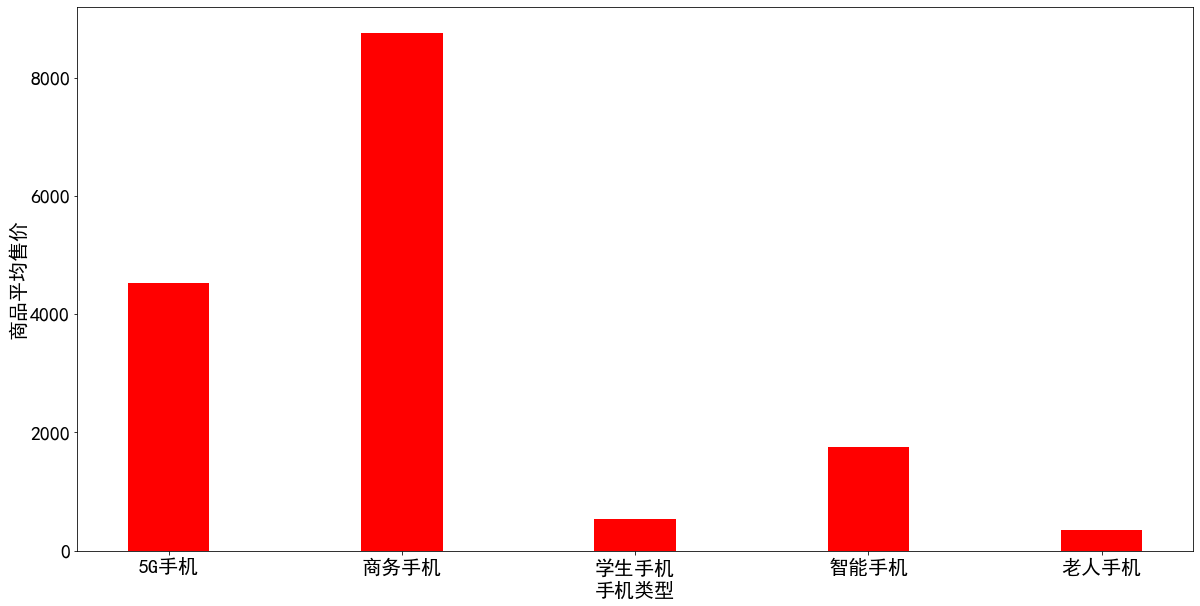
在有大量的数据下,散点图相比于其他的图形,在反映两个变量相互关系下更具有优势。为了更直观的看出商品价格与购买人数之间的关系,我们采用散点图的形式,将其表现出来。 从图5.7中可以看出,排除个别品牌或者店铺影响力的情况下,从总体分布情况来看,商品的售价越低,购买人数越多;商品售价越高,购买人数越少。因此,根据这些可以帮助商家及时的调整价格,增加销量。 目前市面上充斥着各种类型的手机商品,特别是近年来,“5G手机”成为大众追捧的热点。因此,我们对不同的手机类型进行了对比分析。如图5.8所示,商务手机相比于其他手机要贵很多,均价达到近1万元;其次是5G手机,随着近年的快速发展,其价格相比于普通的智能手机要高一点,达到了近5000元;另外,老年手机和学生手机因为功能较少,配置较低,因此它的售价也比较低,只有500元左右。 从图5.9中可以看出,有80.8%的人选择购买普通智能手机;5G手机的占比还比较少,只有6%;老年手机占比11.8%。 通过几周对Python爬虫以及数据可视化分析的学习,我们在这过程中查阅了大量的资料,经过多次实验分析,最终形成我们的项目报告。主要实现了对京东商城中手机商品数据的爬取以及数据分析工作,掌握了Python常用包函数以及数据库的使用方法。总体而言,网络编程这门课让我们学到了很多的东西,网络在我们身边无处不在,学会网络编程对于我们日常的学习和工作都有很大的帮助。 由于时间有限,我们的项目还有一定的不足,后续有机会将会继续改进。 有问题可以随时留言交流 |






【本文地址】