| 基于 PyTorch 的图像特征提取 | 您所在的位置:网站首页 › 图片的特征值 › 基于 PyTorch 的图像特征提取 |
基于 PyTorch 的图像特征提取
|
引言 假设你看到一只猫的图像,在几秒钟内,你就可以识别出来这是一只猫。如果我们给计算机提供相同的图片呢?好吧,计算机无法识别它。也许我们可以在计算机上打开图片,但无法识别它。 众所周知,计算机处理数字,它们看到的和我们不同,因此计算机处理的一切都应该用数字来表示。 我们如何用数字表示图像?图像实际上由数字组成,每个数字代表颜色或亮度。不幸的是,当我们要执行一些机器学习任务(例如图像聚类)时,这种表示形式不合适。 集群基本上是一个机器学习任务,我们根据它们的特征对数据进行分组,每个分组由彼此相似的数据组成。当我们想要对图像进行聚类时,我们必须将其表示形式改变为一维向量。 但是我们不能直接将图像转换为矢量。假设有一个彩色图像,大小为512x512像素,有三个通道,其中每个通道代表红色、绿色和蓝色。 当我们将三维矩阵转换为一维向量时,向量将由786432个数值组成。这是一个巨大的数字! 如果我们全部使用它们,将使我们的计算机处理数据的速度变慢。因此,我们需要一种方法来提取这些特性,这就是 CNN 的卷积神经网络。 卷积神经网络 CNN 是最流行的深度学习模型之一。该模型主要用于图像数据。这个模型将对图像进行卷积处理,用一个叫做卷积核的东西对图像进行过滤,这样我们就可以从中得到一个图案。 由于其层次结构和过滤器大小的不同,CNN 可以捕捉高级、中级甚至低级的特征。此外,它还可以通过使用一种称为池化的机制将信息压缩成一个较小的尺寸。 CNN 模型的优势在于它可以捕捉特征而不用考虑位置。因此,该神经网络是处理图像数据,特别是特征提取的理想类型。 K- 均值算法 在我们使用 CNN 提取特征向量之后,现在我们可以根据我们的目的使用它。在这种情况下,我们希望将图像集群到几个组中。我们如何对图像进行分组? 我们可以使用一种叫做 K-Means 的算法。首先,K-Means 将初始化几个点称为质心。质心是数据进入组的参考点。我们可以按照自己的意愿来初始化质心。 初始化质心后,我们将测量每个数据到每个质心的距离。如果距离值最小,则数据属于该组。它会随时间变化,直到集群不会发生重大变化。 为了测量距离,我们可以使用一个叫做欧几里得度量的公式。
现在我们知道了 CNN 和 K-Means 的概念。让我们开始实现吧! 实现 数据 在本次案例中,我们将使用来自 AI Crowd 的数据集来进行一个名为 AI Blitz 7: Stage Prediction 的挑战。 数据集由一个包含图像的文件夹和一个CSV文件组成,该CSV文件显示了提交给AI Crowd的示例。该文件夹上有1799张图像,并且其中没有标签。因此,这是一个无监督的学习问题。 下载数据集的代码如下所示。 !pip install aicrowd-cli API_KEY = '' !aicrowd login --api-key $API_KEY !unzip test.zip -d data建立模型 在我们下载数据之后,现在我们可以建立模型了。该模型基于 VGG-16体系结构,并且已经使用 ImageNet 进行了预先训练。代码是这样的。 import torch from torch import optim, nn from torchvision import models, transforms model = models.vgg16(pretrained=True)因为我们只想提取特征,所以我们只提取特征层、平均池化层和一个输出4096维向量的全连接层。下面是修改 VGG 模型之前的网络结构。 VGG( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace=True) (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (3): ReLU(inplace=True) (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (6): ReLU(inplace=True) (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (8): ReLU(inplace=True) (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (13): ReLU(inplace=True) (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (15): ReLU(inplace=True) (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (18): ReLU(inplace=True) (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (20): ReLU(inplace=True) (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (22): ReLU(inplace=True) (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (25): ReLU(inplace=True) (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (27): ReLU(inplace=True) (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (29): ReLU(inplace=True) (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(7, 7)) (classifier): Sequential( (0): Linear(in_features=25088, out_features=4096, bias=True) (1): ReLU(inplace=True) (2): Dropout(p=0.5, inplace=False) (3): Linear(in_features=4096, out_features=4096, bias=True) (4): ReLU(inplace=True) (5): Dropout(p=0.5, inplace=False) (6): Linear(in_features=4096, out_features=1000, bias=True) ) )我们如何根据上述结构在PyTorch中提取特征?我们可以使用点运算符来执行此操作。我们对上面提到的每个图层都执行此操作。 提取每一层之后,我们创建一个名为FeatureExtractor的新类,该类继承了PyTorch的nn.Module。完成这些工作的代码如下所示。 class FeatureExtractor(nn.Module): def __init__(self, model): super(FeatureExtractor, self).__init__() # Extract VGG-16 Feature Layers self.features = list(model.features) self.features = nn.Sequential(*self.features) # Extract VGG-16 Average Pooling Layer self.pooling = model.avgpool # Convert the image into one-dimensional vector self.flatten = nn.Flatten() # Extract the first part of fully-connected layer from VGG16 self.fc = model.classifier[0] def forward(self, x): # It will take the input 'x' until it returns the feature vector called 'out' out = self.features(x) out = self.pooling(out) out = self.flatten(out) out = self.fc(out) return out # Initialize the model model = models.vgg16(pretrained=True) new_model = FeatureExtractor(model) # Change the device to GPU device = torch.device('cuda:0' if torch.cuda.is_available() else "cpu") new_model = new_model.to(device)结果如下所示 FeatureExtractor( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace=True) (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (3): ReLU(inplace=True) (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (6): ReLU(inplace=True) (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (8): ReLU(inplace=True) (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (13): ReLU(inplace=True) (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (15): ReLU(inplace=True) (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (18): ReLU(inplace=True) (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (20): ReLU(inplace=True) (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (22): ReLU(inplace=True) (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (25): ReLU(inplace=True) (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (27): ReLU(inplace=True) (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (29): ReLU(inplace=True) (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) (pooling): AdaptiveAvgPool2d(output_size=(7, 7)) (flatten): Flatten(start_dim=1, end_dim=-1) (fc): Linear(in_features=25088, out_features=4096, bias=True) )特征提取 现在我们已经建立了模型。是时候通过使用它来提取特征了。其步骤是输入图像,对图像进行变换,最后提取特征。代码是这样的。 from tqdm import tqdm import numpy as np # Transform the image, so it becomes readable with the model transform = transforms.Compose([ transforms.ToPILImage(), transforms.CenterCrop(512), transforms.Resize(448), transforms.ToTensor() ]) # Will contain the feature features = [] # Iterate each image for i in tqdm(sample_submission.ImageID): # Set the image path path = os.path.join('data', 'test', str(i) + '.jpg') # Read the file img = cv2.imread(path) # Transform the image img = transform(img) # Reshape the image. PyTorch model reads 4-dimensional tensor # [batch_size, channels, width, height] img = img.reshape(1, 3, 448, 448) img = img.to(device) # We only extract features, so we don't need gradient with torch.no_grad(): # Extract the feature from the image feature = new_model(img) # Convert to NumPy Array, Reshape it, and save it to features variable features.append(feature.cpu().detach().numpy().reshape(-1)) # Convert to NumPy Array features = np.array(features)聚类 现在我们有了这些特征,下一步是将其分组。为此,我们将使用scikit-learn库。 from sklearn.cluster import KMeans # Initialize the model model = KMeans(n_clusters=5, random_state=42) # Fit the data into the model model.fit(features) # Extract the labels labels = model.labels_ print(labels) # [4 3 3 ... 0 0 0]保存结果 最后一步是将结果保存到 DataFrame。 import pandas as pd sample_submission = pd.read_csv('sample_submission.csv') new_submission = sample_submission new_submission['label'] = labels new_submission.to_csv('submission_1.csv', index=False)总结 在本文中我们了解了如何使用CNN进行特征提取,以及如何使用K-Means进行聚类,快来动手实践一下吧~ · END · HAPPY LIFE
|
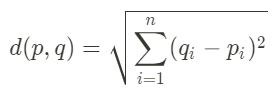

【本文地址】