| SAS | 您所在的位置:网站首页 › 变异系数如何解读 › SAS |
SAS
|
PROC UNIVARIATE 用于对单变量做统计分析,可以生成一系列统计量和图表。 假设有一组学生考试得分的数据如下:
生成的结果包含5部分: 1. 矩统计量 2. 基本的位置和分散程度统计量 3. 关于均值=0的三种检验:t检验、符号检验、符号秩检验 4. 各个重要的分位数 5. 观测数据的五个最低值和五个最高值
1. 矩统计量 N: 观测数据个数 Sum Weights:
Mean : 加权平均或算数平均,当没有指定权重时,就是算数平均(即每个观测的权重为1)。
Sum Observations:所有观测值的和。等于 N*Mean. Variance:方差。这里 d 是自由度,默认等于 n-1。
关于 VARDEF 的说明:其中CSS就是结果中的 Corrected SS (4592.9667).
Std Deviation : 标准差 (SD)。等于方差求根号运算。 Skewness:偏度。用来衡量变量分布的偏斜度。偏度的取值范围为(-∞,+∞) . 当偏度0时,概率分布图右偏。 Kurtosis:峰度。用来衡量变量分布的顶部陡峭程度。峰度的取值范围为[1,+∞), 正态分布的峰度值为 3, 超过3说明变量分布是尖峰的, 低于3说明峰度更平缓。 Coeff Variation: 变异系数。是样本标准差(sample standard deviation) 和 样本均值的比值。用来衡量样本的离散程度, CV 越大表示数据分布越离散。
Std Error Mean: 标准误差均值 (Standard Error of Mean, SE)。SE是样本统计量的标准差,是衡量样本抽样的误差的指标, SE越小说明抽样误差越小。SD衡量一组数据的离散程度。
输出结果中的SE=2.297666(=SD/根号N=12.584839/根号30).
2. 基本的位置和分散程度统计量 输出结果有: 均值, 中位数, 众数, 标准差, 方差, 极差(Range), 四分位距(Interquartile Range)。 极差 (Range) = 最大值 - 最小值 ; 四分位距(Interquartile Range, IQR) = Q3 - Q1。
3. 关于均值=0的三种检验:t检验、符号检验、符号秩检验
|






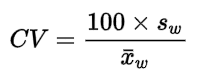

【本文地址】