| 【Python强化学习】强化学习基本概念与冰湖问题实战(图文解释 附源码) | 您所在的位置:网站首页 › 冰湖的读后感 › 【Python强化学习】强化学习基本概念与冰湖问题实战(图文解释 附源码) |
【Python强化学习】强化学习基本概念与冰湖问题实战(图文解释 附源码)
|
需要源码请点赞关注收藏后评论区留言私信~~~ 强化学习强化学习(Reinforcement Learning, RL)是学习主体(Agent)以“尝试”的方式探索世界、获取知识的学习机制。强化学习起源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。 与前述的聚类、回归、分类和标注任务不同,强化学习面向的是所谓的序列决策(Sequential Decision Making)任务:主体根据环境的状态和反馈连续选择行为,力图收获最大收益。 仿真工具强化学习需要不断地尝试,因此研究强化学习,离不开仿真。OpenAI的gym 仿真工具提供了对强化学习问题求解仿真的支持。gym采用Python语言,可以和本书使用的编程环境无缝衔接。 可通过 “conda install gym=0.18.0”命令安装本书使用的gym仿真环境。 在gym中仿真强化学习问题,先要在gym中构建相应的仿真环境(具体构建方法可参考相应网站和书籍)。gym内部预先集成了很多已经构建好的强化学习问题仿真环境供初学者使用,如冰湖问题仿真环境。 冰湖问题v0版的冰湖问题(FrozenLake-v0) 的情景是agent要自主穿过有窟窿的冰面拿到飞盘。冰面由4×4的方格表示,标记为S的方格为agent的出发点,标记为G的方格为飞盘所在的位置,即agent要到达的终点。空白方格表示可以行动的安全区域,灰色方格表示有窟窿的冰面,是会掉入水中的危险区域。
为了简化表示,在gym的FrozenLake-v0环境中,用由S、F、H、G四个字母组成的表格来表示冰面。 强化学习要解决的问题是如何控制agent从S点出发顺利到达G点。 称agent为强化学习中的主体。主体要依据某个策略(policy)来决定下一步的动作(action)。主体通过不断地尝试来优化策略。 在冰湖问题中,动作有4个,分别是向左、向下、向右和向上,用0、1、2、3来标记。动作的所有可能取值的集合称为动作空间,记为A={0,1,2,3}。 import gym # loading the Gym library env = gym.make("FrozenLake-v0") # 看一下动作空间 print("Action space: ", env.action_space) >>>Action space: Discrete(4) # 看一下观察空间,以及它的取值大小 print("Observation space: ", env.observation_space) >>>Observation space: Discrete(16) 状态空间在冰湖问题中,主体在冰面上的不同位置称为环境(environment)的不同状态。总共有4×4=16个位置,因此,环境有16个状态,编号为0,1,…,15。
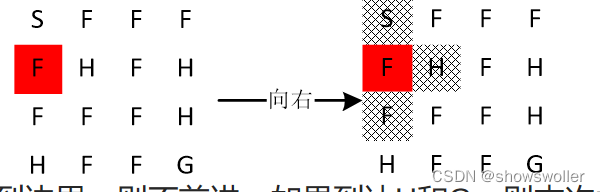
状态的所有可能取值组成状态空间,记为S={0,1,…,15}。 策略示例主体的策略是从状态到动作的映射,也就是说,对一个具体的状态,策略要给出明确的动作指示来确定主体的下一步行动。在冰湖问题中,可以用如下的列表来表示一个策略:[1, 3, 2, 2, 0, 0, 0, 1, 3, 0, 1, 2, 0, 3, 2, 3] 列表最左侧的1表示在0号状态时执行编号为1的动作,即在起始点S执行向下的动作。左侧第2个位置上的3表示在1号状态时执行编号为3的动作,即在位置1执行向上的动作。以此类推。 rand_pi = [] for _ in range(16): rand_pi.append(env.action_space.sample()) print("随机策略:", rand_pi) >>>随机策略: [1, 3, 2, 2, 0, 0, 0, 1, 3, 0, 1, 2, 0, 3, 2, 3] 环境模型在冰湖问题中,规定当前位置为S和F时,施加动作的影响是使主体向动作的方向以及该动作两侧的方向等概率前进一格。用深色背景表示主体当前所在的位置,当前状态为状态4,如果执行向右的动作,则会以1/3的概率进入状态0、状态5和状态8。
如果碰到边界,则不前进。如果到达H和G,则本次尝试结束,默认回到状态0(下次尝试出发点)。强化学习中,环境状态因为动作而改变的规律称为环境模型,一般用概率来描述。 回报在仿真实验中,主体的每进入到下一状态都有一个回报(reward)。 如果当前动作使主体到达了终点G,则能得到一个回报值1,否则回报值为0。 def episode(env, pi, gamma = 1.0, render = False): s = env.reset() # 初始状态 sum_reward = 0 n = 0 # 折扣的幂 while True: if render: env.render() s, reward, done , _ = env.step( int(pi[s]) ) sum_reward += ( gamma**n * reward ) # 累积折扣回报函数 n += 1 if done: env.render() break #print(sum_reward) return sum_reward episode(env, rand_pi, 1.0, True)
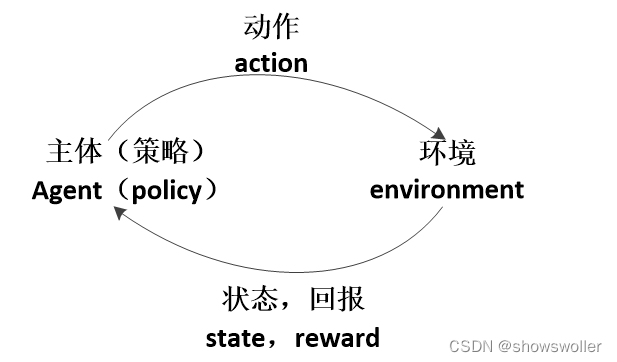
强化学习中,主体(策略)、动作、环境、状态和回报之间的关系:
主体依据策略来决定下一步动作,主体的动作又会改变环境,主体能够观察到环境状态的变化,并得到环境的立即回报。然后,主体根据新的状态并依据策略来决定新的动作。可见,强化学习是一个持续决策的过程。 策略、动作、状态和回报分别记为π、a、s和r。 在任一时刻t,主体依据策略π和环境的状态s_t,作出动作a_t。 环境对动作a_t的新反馈s_t+1和新回报r_t+1在下一时刻t+1传递到主体,此时,主体再作出新的动作a_t+1。 如此持续循环,直至本次尝试结束。 在每一个循环中,可分为两个阶段:(1)主体决策并作出动作阶段;(2)环境接受动作并反馈状态和回报阶段。 在阶段(1),主体的策略可表示为: a_t=π(s_t│θ) 其中, θ是π的参数。 策略可以是各种形式的,如决策函数、概率分布和神经网络等等。策略本质上反映了从主体接收的环境状态s_t到发出的动作a_t之间的映射关系。策略是强化学习算法要求解的最终目标。 策略可以分为确定性策略和随机性策略。确定性策略的决策过程是确定的,即一个状态明确对应一个动作,如均匀随机策略。随机性策略的决策过程是依据一定的概率对可选动作进行随机选择,即一个状态对应多个动作,并依事先确定的概率来随机选择其中一个动作。因此,随机性策略要用概率分布函数来描述。 在阶段(2),环境接受主体的动作并反馈的状态可表示为: s_t+1=O(s_t,a_t ) 该式反映的是环境从当前状态因外部动作刺激而转换到另外状态的映射关系,即环境模型。在gym中,环境模型在env.step()函数中仿真实现。 回报r反映的是价值目标,它是人们主观确定的东西。比如,在冰湖实验中,人们认为主体到达目标点捡起飞盘是“好”的,因此,把此时的回报定为1,否则为0。 因此,强化学习的过程可以看作是在回报这个主观价值目标的指引下,使决策努力适应环境模型的过程。 创作不易 觉得有帮助请点赞关注收藏~~~ |



【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |